Catalog
Mission profile
Solution steps
Code implementation
summary
Hello everyone I am a Zhengyin Today, I will teach you to crawl through financial futures data
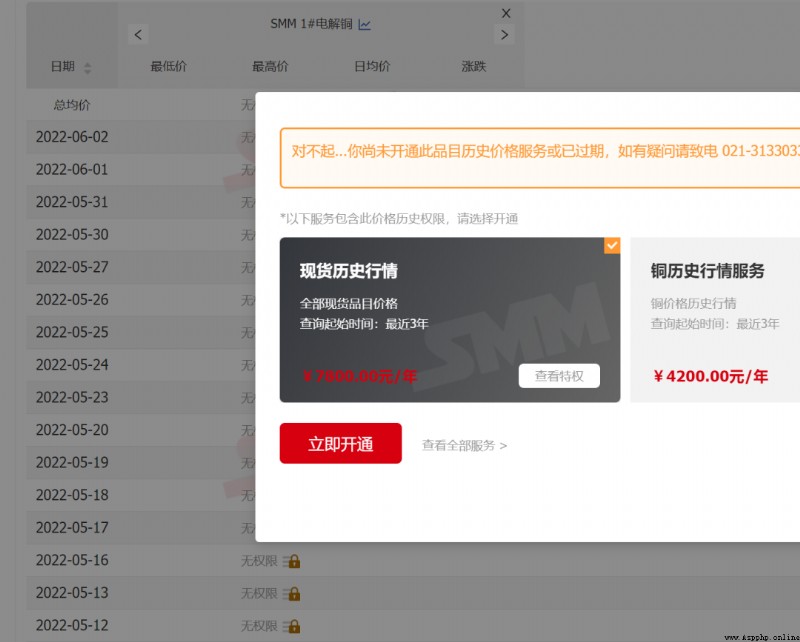
First , The customer's original demand is to obtain https://hq.smm.cn/copper Price data on the website ( notes : What we get is the public data on the website ), As shown in the figure below :
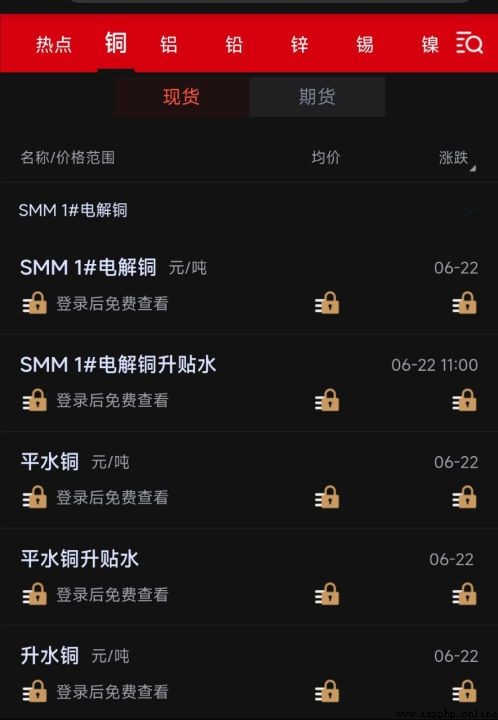
If you target this website , The problem to be solved is “ Sign in ” user , Then the price can be parsed into a table for output . however , In fact, the core goal of the customer is to obtain “ Shanghai copper CU2206” The historical price of , Although the site also provides data , But need “ members ” To access , And members need krypton gold ......
Value of data !!!
Whereas , Customer needs are just “ Shanghai copper CU2206” The historical price of a futures , Krypton gold members are not cost-effective , therefore , The actual task goal becomes how to obtain the historical price , The goal is to have a website that publicly provides data throughout the network . And finally solve the problem , Is to turn to the Almighty Baidu ^_^. Found the right website , And the difficulty of obtaining data has been reduced to the lowest level .
Baidu search resources : This step is the most difficult part of the whole task ( Actually, it's not difficult. ), But here's a catch , The full text does not publish the website finally found , Let's try and see if we can find , And how much time it takes ^_^.
Parsing web site requests , The website finally found is parsed , It is found that data is obtained through get To submit parameters . The requested parameters are as follows :/price?starttime=1638545822&endtime=1654357022&classid=48, It's the start time 、 Timestamp of the end time , And commodities id. To resolve headers, Even cookie No need , It means that there is no reverse climbing ! There is no anti climbing ! There is no anti climbing ! I have to say that my luck broke out !
Parsing response data : Because the response data is regular json Format data , Use pandas Of read_json Direct access to dataframe Formatted data , This step is not difficult .
In view of the fact that the website is not anti - crawled , And the parameters are simple , In fact, the main task is to plan how to design the process of incrementally updating data information , The specific code is as follows :
# @author: zheng yin
# @contact: [email protected]
"""
1. This is the procedure for crawling Shanghai copper
2. The actual request address for the data of the current month of the website is :'( Actual web address )/price?starttime={starttime}&endtime={endtime}&classid={classid}'
2.1. starttime Is the timestamp of the start date
2.2. endtime Is the timestamp of the end date
2.3. classid To query the product id
3. The website can directly initiate a request to obtain data
I am Zhengyin Looking forward to your attention
"""
import time
from datetime import datetime
import pathlib as pl
import requests
import pandas as pd
class Spider:
"""
Crawler object for crawling website data
"""
def __init__(self, starttime: str = None, endtime: str = None, classid: int = 48):
"""
Initialize object properties
:param starttime: Start date of data , Text date format , Example 2022-1-1
:param endtime: End date of data , Text date format , Example 2022-1-1
:param classid: goods id, Default 48
"""
self.classid = classid # goods id
self.data = pd.DataFrame() # Initialization null dataframe
self.data_file = pl.Path('./data/hutong.xlsx') # Crawled data storage file
# Column name dictionary
self.cols_dict = {
'createtime': ' date ',
'classid': ' goods ',
'start': ' The opening quotation ',
'end': ' The close ',
'min': ' The minimum ',
'max': ' The highest ',
'move': ' Up and down ',
'move_percent': ' Up and down percentage '
}
# goods id Dictionaries
self.classid_dict = {
48: 'CU2206'
}
# Get the start time and end time of crawling
self.starttime, self.endtime = self.make_starttime_endtime(starttime=starttime, endtime=endtime)
# Initialize the crawling url
self.url = '( Actual address )/price?starttime={starttime}&endtime={endtime}&classid={classid}'
# initialization headers
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
}
def make_starttime_endtime(self, starttime: str, endtime: str):
"""
Production start date , The logic is as follows ;
1. If there is an incoming date , According to the incoming date , Define start and end dates
2. If no parameter is passed in , The start date is the maximum date in the read historical data file 、 Take the current date as the end date
3. If the historical data file is not read , Or the maximum date in the file is empty , with 2021-1-1 As the start date , Take the current date as the end date
:param starttime: Start date of data , Text date format , Example 2022-1-1
:param endtime: End date of data , Text date format , Example 2022-1-1
:return:
"""
self.read_data() # Read historical crawl data
now = datetime.now() # Get the timestamp integer part of the current time
if endtime: # If it is not empty
year, month, day = endtime.split('-')
endtime = int(now.replace(year=int(year), month=int(month), day=int(day)).timestamp())
else:
endtime = int(now.timestamp())
if starttime:
year, month, day = starttime.split('-')
starttime = int(now.replace(year=int(year), month=int(month), day=int(day)).timestamp())
else:
starttime = self.data[' date '].max()
if pd.isnull(starttime): # If the start date is null
starttime = int(now.replace(year=2021, month=1, day=1).timestamp())
else:
starttime = int(
now.replace(year=starttime.year, month=starttime.month, day=starttime.day).timestamp())
return starttime, endtime
def read_data(self):
"""
Read historical data
:return:
"""
if self.data_file.is_file(): # If the historical data file exists
self.data = pd.read_excel(self.data_file)
self.data[' date '] = self.data[' date '].map(lambda x: x.date())
else: # If the historical data file does not exist , Then initialize a column name only dataframe,
self.data = pd.DataFrame(self.cols_dict.values()).set_index(0).T
def crawl_data(self):
"""
Crawl data
:return:
"""
retry_times = 0
while retry_times < 10: # retry 10 Time
try:
res = requests.get(
self.url.format(starttime=self.starttime, endtime=self.endtime, classid=self.classid),
headers=self.headers, timeout=30)
if res.status_code == 200: # If the return status is 200, Perform subsequent data processing
data = pd.read_json(res.text) # json Format conversion to dataframe
data['createtime'] = data['createtime'].map(lambda x: datetime.fromtimestamp(x).date()) # Timestamp date converted to date
data.rename(columns=self.cols_dict, inplace=True) # To be ranked high
data = data[self.cols_dict.values()] # Intercept the required columns
data[' goods '] = self.classid_dict.get(self.classid, ' Unknown product , Please maintain classid_dict Dictionaries ') # Convert trade name
data.sort_values(by=[' goods ', ' date '], ascending=True, inplace=True) # Sort by date in ascending order
return data
else:
retry_times += 1
print(f' The return status code is {res.status_code}, wait for 5 Reissue the request in seconds ')
time.sleep(5)
except Exception as e:
retry_times += 1
print(f' Request error , wait for 5 Reissue the request in seconds , error message : {e}')
time.sleep(5)
print(' launch 10 No data was obtained for each request ')
return pd.DataFrame()
def concat_and_write_data(self, data: pd.DataFrame):
"""
Merge data , And write the data to the file
:param data: Pass in the data to be merged
:return:
"""
self.data = pd.concat([self.data, data]) # Merge data
self.data = self.data.drop_duplicates([' date ', ' goods '], keep='last') # The data is de duplicated according to the product name and date , Keep the latest record every time
if not self.data_file.parent.is_dir(): # Check if the directory of the data file exists , If it does not exist, create a new directory
self.data_file.parent.mkdir()
self.data.to_excel(self.data_file, index=False, encoding='utf-8') # The output data is excel Format
def run(self):
"""
Run the program
:return:
"""
data = spider.crawl_data() # Running crawl
if len(data) > 0: # If the crawled data is not empty
self.concat_and_write_data(data)
start = str(datetime.fromtimestamp(self.starttime))[:10]
end = str(datetime.fromtimestamp(self.endtime))[:10]
print(f'{start} to {end} Data crawling task completed ')
def pivot_data(self):
"""
Convert data to PivotTable format
:return:
"""
data = self.data.copy()
data[' years '] = data[' date '].map(lambda x: f'{str(x)[:7]}')
data[' Japan '] = data[' date '].map(lambda x: x.day)
data = data.pivot_table(values=' The close ', index=' Japan ', columns=' years ', aggfunc='sum')
data_mean = data.mean().to_frame().T
data_mean.index = [' Average ']
data = pd.concat([data, data_mean])
data.to_excel(self.data_file.parent.parent / 'data.xlsx', encoding='utf-8')
if __name__ == '__main__':
spider = Spider()
spider.run()
spider.pivot_data()
print(spider.data)From a technical point of view , After step-by-step analysis , The task is simple , introduction requests Reptile and introduction pandas Data analysis can be completed ( The only difficulty is to find the right target ). But from another angle , In terms of economic value , It is also very valuable , That is, it saves the high annual fee of a website ( notes : It's not that the annual fee is not worth it , It's just that the demand is just CU2206 When one item of data goes up , Low cost performance ), At the same time, it avoids the tedious manual operation , And possible errors . Big problems can be solved with a small learning cost
therefore , What are you waiting for ? Turn on Python The way !
I am a Zhengyin Looking forward to your attention