是為了爬取網站數據,提取結構性數據而編寫的應用框架,可應用在包括數據挖掘、信息處理或存儲歷史數據等一系列程序中
(一)安裝
pip install scrapy -i https://pypi.douban.com/simple
報錯:
WARNING: You are using pip version 21.3.1; however, version 22.1.2 is available.
You should consider upgrading via the 'D:\PythonCode\venv\Scripts\python.exe -m pip install --upgrade pip' command.
解決辦法:運行python -m pip install --upgrade pip
(二)基本使用
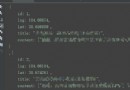
scrapy startproject scrapy_baidu_01D:\P ythonCode\venv\ScriptsD:\PythonCode\venv\Scripts\scrapy_baidu_01\scrapy_baidu_01\spiders>scrapy genspider 爬蟲文件名字 要爬取的網頁scrapy crawl 爬蟲的名字名字是[name = ‘baidu’] import scrapy
class BaiduSpider(scrapy.Spider):
# 爬蟲的名字,使用的值
name = 'baidu'
# 允許訪問的域名
allowed_domains = ['www.baidu.com']
# 起始的url地址 第一次要訪問的域名
# start_urls實在allowed_domains的前面添加一個http://,在後面添加了/
start_urls = ['http://www.baidu.com/']
# 執行了start_urls之後執行的方法,方法中的response是返回的對象,相當於
# response = urllib.request.urlopen()
# response = requests.get()
def parse(self, response):
print('ssssss')
1. scrapy項目的結構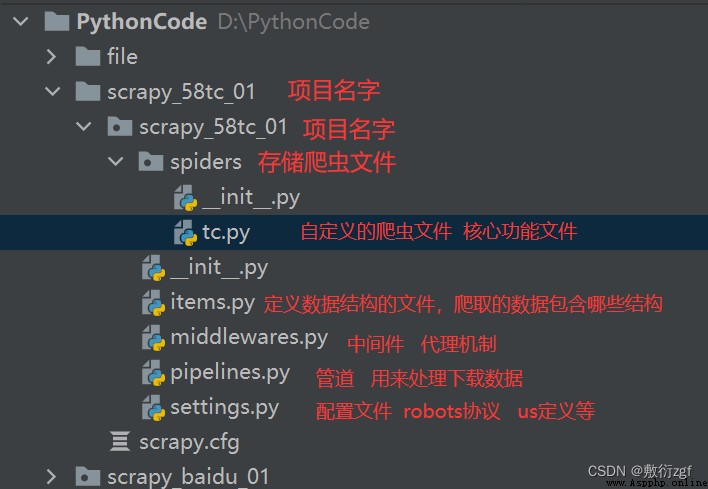
2. response的屬性和方法
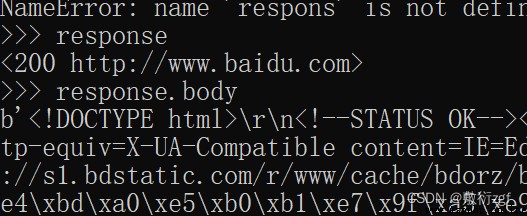
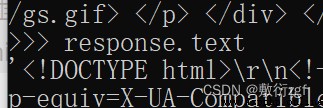
response.text獲取的是響應的字符串
response.body獲取二進制數據
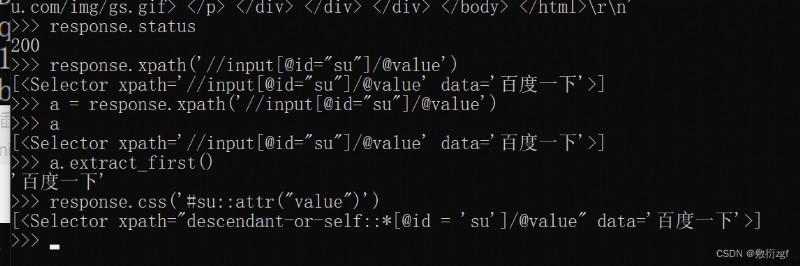
response.xpath可以直接使用xpath方法來解析response中的內容
response.extract() 用於提取seletor對象中的data屬性值
response.extract_first() 提取seletor列表的第一個數據
import scrapy
class CarSpider(scrapy.Spider):
name = 'car'
allowed_domains = ['car.autohome.com.cn/price/brand-15.html']
start_urls = ['https://car.autohome.com.cn/price/brand-15.html']
def parse(self, response):
name_list = response.xpath('//div[@class="main-title"]/a/text()')
price_list = response.xpath('//div[@class="main-lever"]//span/span/text()')
for i in range(len(name_list)):
name = name_list[i].extract()
price = price_list[i].extract()
price(name,price)
scrapy工作原理【灰常重要!!】
直接輸入指令:scrapy shell www.baidu.com