說明:這是一個機器學習實戰項目(附帶數據+代碼+文檔+視頻講解),如需數據+代碼+文檔+視頻講解可以直接到文章最後獲取。
1.項目背景
在污水處理全過程中,為了更好地使解決後的水達到環保標准,在污水處理的每一個環節都是會用水質檢測機器設備測量水體,依據水質檢測機器設備測出的數據信息,選用相對應的處置方式,使本環節水質指標做到規定,再進到下一個解決環節。
本項目通過PSO粒子群優化支持向量機回歸模型,進行水質檢測。
2.數據獲取
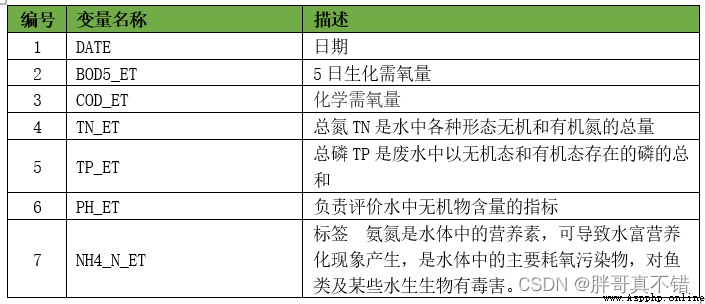
本次建模數據來源於網絡(本項目撰寫人整理而成),數據項統計如下:
數據詳情如下(部分展示):
3.數據預處理
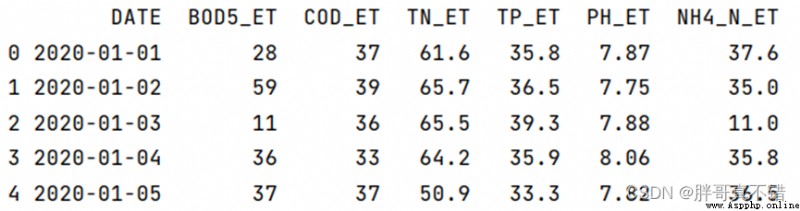
3.1 用Pandas工具查看數據
使用Pandas工具的head()方法查看前五行數據:
關鍵代碼:
3.2數據缺失查看
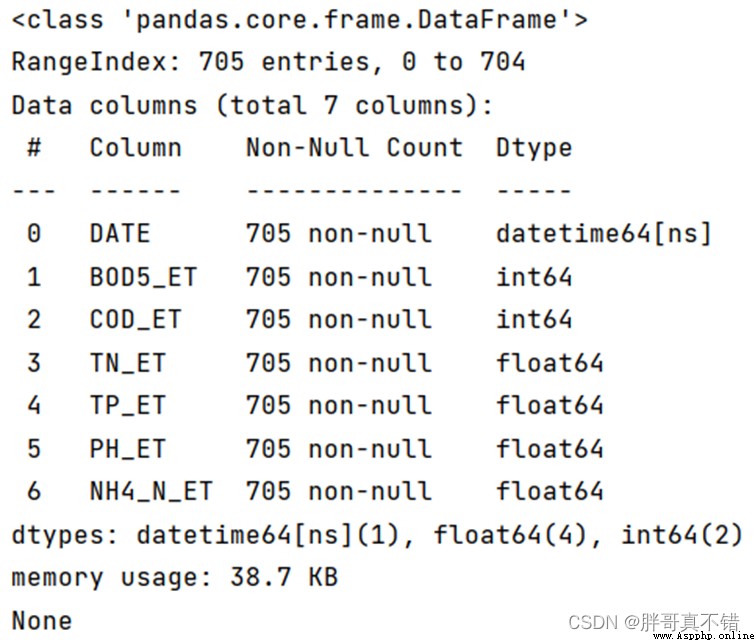
使用Pandas工具的info()方法查看數據信息:
從上圖可以看到,總共有7個變量,數據中無缺失值,共705條數據。
關鍵代碼:
3.3數據描述性統計
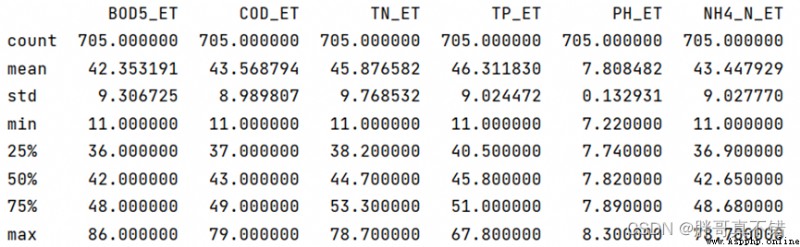
通過Pandas工具的describe()方法來查看數據的平均值、標准差、最小值、分位數、最大值。
關鍵代碼如下:
4.探索性數據分析
4.1 氨氮NH4_N_ET變量的折線圖
用Matplotlib工具的plot()方法繪制折線圖:
4.2 PH_ET變量箱型圖
用Pandas工具的plot(kind=‘box)方法繪制柱狀圖:
從上圖可以看出,PH值均值在7.8左右。
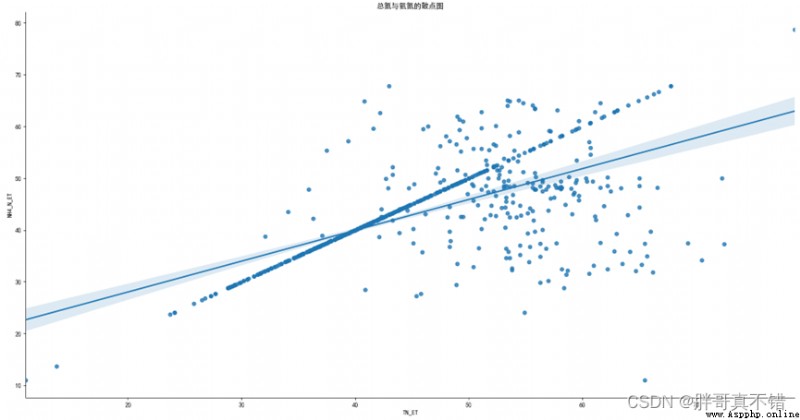
4.3 總氮與氨氮的散點圖與擬合線
用seaborn工具的lmplot ()方法繪制散點圖與擬合線:
從上圖可以看出,總氮和氨氮存在一定的線性關系。
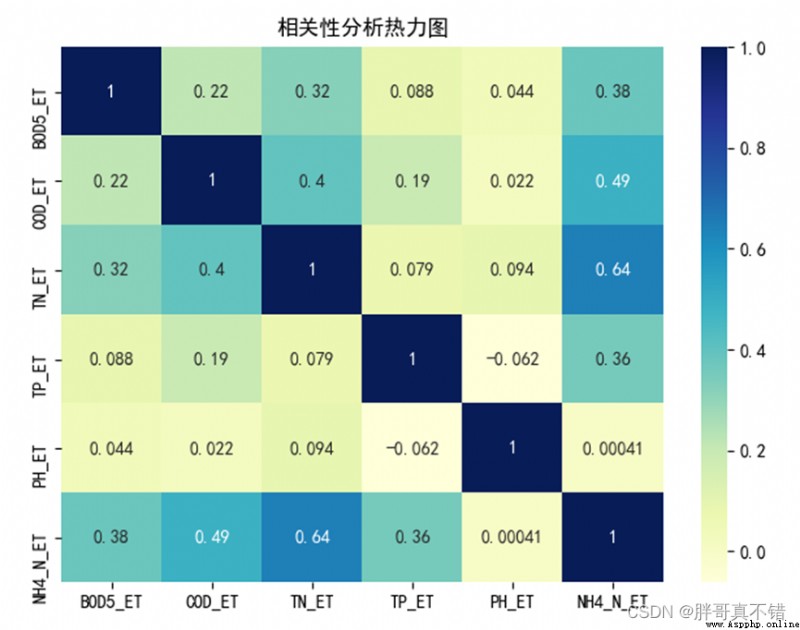
4.4 相關性分析
從上圖中可以看到,數值越大相關性越強,正值是正相關、負值是負相關。PH_ET和標簽NH4_N_ET相關性非常弱,在後續特征工程中可以考慮去掉此特征變量。
5.特征工程
5.1 建立特征數據和標簽數據
關鍵代碼如下:
5.2 數據集拆分
通過train_test_split()方法按照80%訓練集、20%測試集進行劃分,關鍵代碼如下:
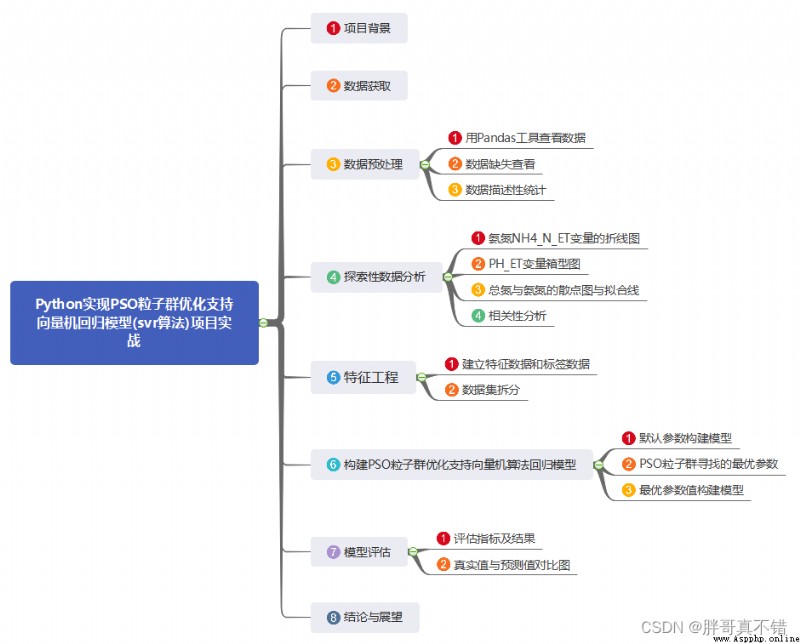
6.構建PSO粒子群算法優化支持向量機回歸模型
粒子群優化算法(PSO:Particle swarm optimization) 是一種進化計算技術(evolutionary computation)。源於對鳥群捕食的行為研究。粒子群優化算法的基本思想:是通過群體中個體之間的協作和信息共享來尋找最優解。
主要使用PSO粒子群優化SVR算法,用於目標回歸。
6.1默認參數構建模型
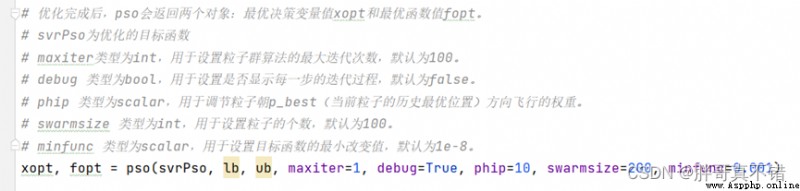
6.2 PSO粒子群尋找的最優參數
關鍵代碼:
最優參數:
6.3 最優參數值構建模型
7.模型評估
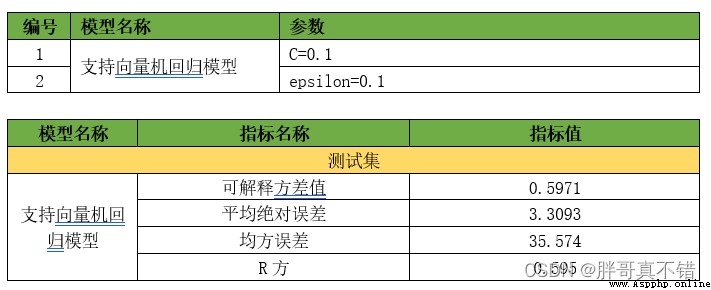
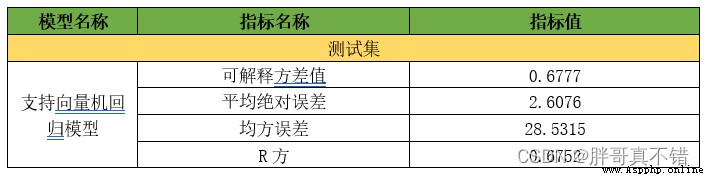
7.1評估指標及結果
評估指標主要包括可解釋方差值、平均絕對誤差、均方誤差、R方值等等。
從上表可以看出,R方為0.6752 較默認參數優提升;可解釋方差值為0.6777 較默認參數優提升,優化後的回歸模型效果良好,大家可以基於這個基礎上增加粒子群迭代次數等進行調優,我這裡的模型評估值為迭代1次的評估值,一般都要迭代100次到1000次,所以大家實際應用時根據需要修改參數值即可。
關鍵代碼如下:
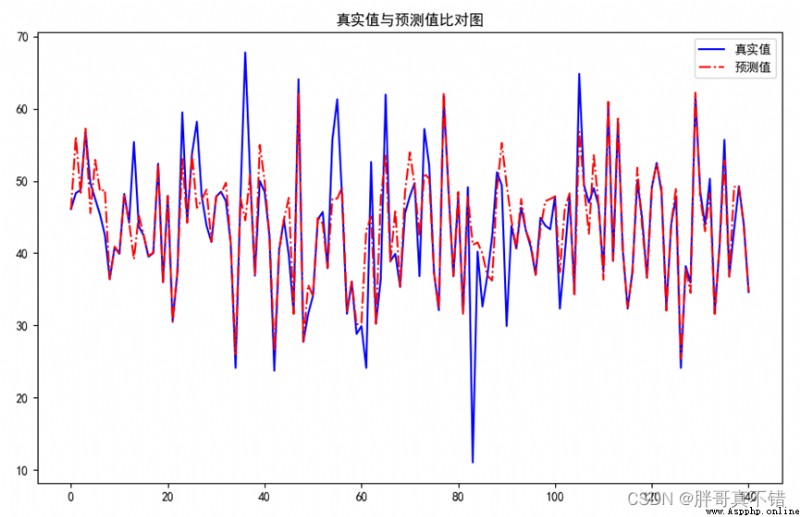
7.2 真實值與預測值對比圖
從上圖可以看出真實值和預測值波動基本一致,模型擬合效果良好。
8.結論與展望
綜上所述,本文采用了PSO粒子群優化算法尋找支持向量機SVR算法的最優參數值來構建回歸模型,最終證明了我們提出的模型效果良好。此模型可用於日常產品的預測。
本次機器學習項目實戰所需的資料,項目資源如下:
項目說明:
鏈接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w
提取碼:bcbp網盤如果失效,可以添加博主微信:zy10178083