chardet This third-party library is very easy to use ,chardet Support the detection of Chinese 、 Japanese 、 Korean and many other languages .
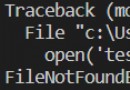
String encoding has always been a headache , Especially when dealing with some non-standard third-party Web pages . although Python Provides Unicode It means str and bytes Two types of data , And through encode() and decode() Method transformation , however , Without knowing the code , Yes bytes do decode() Not easy to do .
For unknown encoded bytes, To convert it into str, It needs to be done first “ guess ” code . The way of guessing is to collect various coded characteristic characters first , Judge according to the characteristic characters , There is a high probability “ Guess right ”.
Official documents :https://chardet.readthedocs.io/en/latest/
github Address :https://github.com/chardet/chardet
install :pip3 install chardet
Up to now , Detectable codes :
When we get one bytes when , It can be detected and coded . use chardet Detection code , Just one line of code :
import chardet
print(chardet.detect(b'Hello, world!'))
# Running results
# The detected code is ascii, Notice another confidence Field , Indicates that the probability of detection is 1.0( namely 100%).
{
'encoding': 'ascii', 'confidence': 1.0, 'language': ''}
import chardet
data = ' There is only one truth '.encode('gbk')
print(chardet.detect(data))
# Running results
# The detection code is GB2312, be aware GBK yes GB2312 Superset , They're the same code , The probability of correct detection is 99%,
# language The language indicated by the field is 'Chinese'.
{
'encoding': 'GB2312', 'confidence': 0.99, 'language': 'Chinese'}
import chardet
data = ' There is only one truth '.encode('utf-8')
print(chardet.detect(data))
# Running results
{
'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
import chardet
data = ' Truth はいつもひとつ'.encode('euc-jp')
print(chardet.detect(data))
# Running results
{
'encoding': 'EUC-JP', 'confidence': 1.0, 'language': 'Japanese'}
so , use chardet Detection code , It's simple . After obtaining the code , Re convert to str, It is convenient for subsequent processing .