Knowledge points applied :
s=difflib.SequenceMatcher(isjunk=None,a,b, autojunk=True) : Constructors , It mainly creates comparison objects of any type of sequence .
isjunk It's a keyword parameter , Mainly set the filter function , If you want to lose a and b Compare specific characters in the sequence , You can set the corresponding function
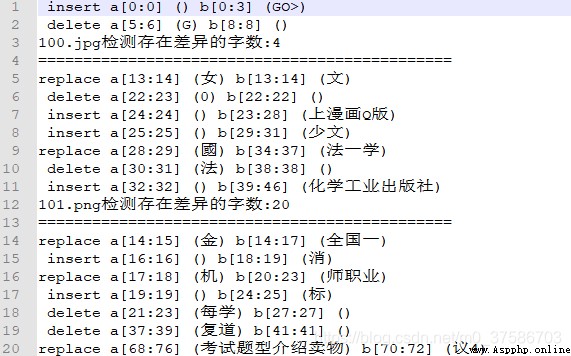
s.get_opcodes() Each time the function executes, it returns 5 Tuples of elements , Tuples describe a and b Compare the similarities and differences of the sequence .5 Tuples of elements are represented as (tag, i1, i2, j1, j2), among tag Show action ,i1 Represents a sequence a The beginning of ,i2 Represents a sequence a At the end of ,j1 Represents a sequence b The beginning of ,j2 Represents a sequence b At the end of .
tag The string represented is :
replace Express a[i1 : i2] Will be b[j1 : j2] Replace .
delete Express a[i1 : i2] Will be deleted .
insert Express b[j1 : j2] Will be inserted into a[i1 : i1] place .
equal Express a[i1 : i2] == b[j1 : j2] identical .
string.maketrans(instr,outstr) Return a translation table ,instr The characters in need to be outstr Character replacement in , and instr and outstr Must be equal in length
str.maketrans(intab, outtab) Method to create a conversion table for character mapping , For the simplest call to accept two parameters , The first parameter is the string , Indicates the character to be converted , The second parameter is also the target of string representation transformation . The length of the two strings must be the same , It is a one-to-one correspondence .
import xlrd,re
import difflib
def E_trans_to_C(string):# English symbols are converted to Chinese symbols
E_pun = u',.!?[]()<>"\''
C_pun = u',.!?【】()《》“‘'
trantab = str.maketrans(E_pun, C_pun) # Make a translation table
return string.translate(trantab)
def change_txt(st):# Convert text : Remove the space 、 Remove the symbol 、 Chinese English character conversion
# # Remove spaces at the beginning or end of a string
# new_st = st.strip()
# Remove all spaces
new_st = ''.join(E_trans_to_C(st).split(' '))
# Chinese and English symbols : Convert all symbols in the text to Chinese symbols
# toggle case
# new_st = st.upper()
# new_st = st.lower()
return new_st
data = xlrd.open_workbook(r'D:\ Job content \content423.xlsx')
table = data.sheets()[0]
log=''
for i in range(1,table.nrows):
row_value = table.row_values(i)
txt1=row_value[1]
txt2=row_value[2]
s = difflib.SequenceMatcher(None, txt1, txt2)
# s = difflib.SequenceMatcher(None, change_txt(txt1), change_txt(txt2))
cw_num=0
for tag, i1, i2, j1, j2 in s.get_opcodes():
# print ("%7s a[%d:%d] (%s) b[%d:%d] (%s)" % (tag, i1, i2, a[i1:i2], j1, j2, b[j1:j2]))
if tag != 'equal':
print("%7s a[%d:%d] (%s) b[%d:%d] (%s)" % (tag, i1, i2, txt1[i1:i2], j1, j2, txt2[j1:j2]))
log += ("%7s a[%d:%d] (%s) b[%d:%d] (%s)" % (tag, i1, i2, txt1[i1:i2], j1, j2, txt2[j1:j2]) + '\n')
if len(txt1[i1:i2]) > len(txt2[j1:j2]):
cw_num += len(txt1[i1:i2])
else:
cw_num += len(txt2[j1:j2])
print("{} Detect the number of words with difference :{}".format(row_value[0],cw_num))
log += ("{} Detect the number of words with difference :{}".format(row_value[0],cw_num) + '\n')
log += ("==============================================" + '\n')
with open(r'D:\ Job content \content423_log.txt', 'w', encoding="UTF-8") as f:
f.write(log + '\n')Return results : ( For reference only )