Catalog
1 preface
1.1 Philosophic thinking brought about by survival pressure
1.2 buy a house & House slave
2 Reptiles
2.1 Basic concepts
2.2 Basic process of reptile
3 Crawl the Guiyang house price and write it into the table
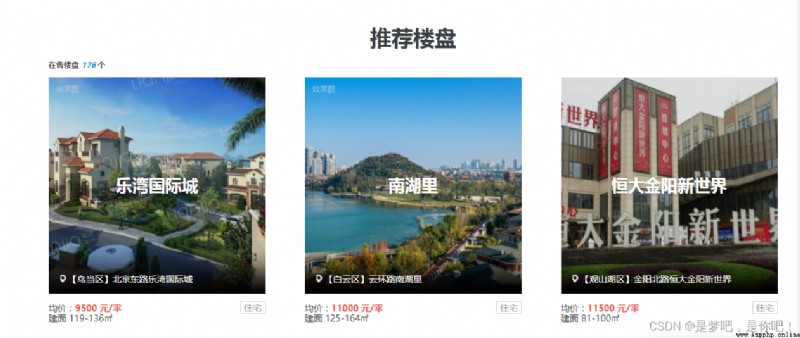
3.1 Result display
3.2 Code implementation (Python)

Malthus first discovered , The ability of a creature to multiply geometrically , Always greater than their actual viability or actual survival group , Think in turn , Intraspecific competition among organisms must be extremely cruel and inevitable . For the time being, whether Malthus is necessary to give corresponding warnings to mankind , It is only a series of basic problems implied in this phenomenon , for example , What is the natural limit of the ability of organisms to reproduce in excess ? What advantages do survivors of intraspecific competition rely on to win ? And how these so-called dominant groups lead themselves to where ? wait , It is enough to cause any thoughtful person to be afraid ( Fear ) Deep thought .
later , Darwin in his landmark 《 The origin of species 》 In the introduction of a Book , The scientific contribution and Enlightenment of Malthusian theory are specially mentioned , It can be seen that I want to be the bosom friend of that old priest ma , Not ordinary people are qualified !
Get married now , The woman generally requires the man to have a house and a car , In fact, you can't blame other girls , Highly developed in society 、 Today is turbulent , This requirement is not high . However, since the reform and opening up , Class solidify , It is difficult for us ! Let's take a look at the housing prices in Guiyang ( Lianjia Xinfang : Guiyang Xinfang _ Buy a house in Guiyang _ Guiyang real estate information network ( Guiyang Lianjia new house ))

Can not be eliminated by the times , Can't always sigh , There are few big capitalists who started from scratch , Liu qiangdong is just another one . Idols belong to idols , Come back to reality , Rural children , Maybe I bought a house , You may be a lifelong house slave , Back in the countryside , The surface is bright and beautiful and worshipped by others , Only you know the bitterness and grievances in your heart . In view of this , Personally, I don't want to be a house slave and a car slave , Happiness is your own , Life is your own , Live your own brilliance , It's not live for others to see , I want to make the charming scenery of my destiny colorful , What we should do at this stage is to improve our ability , Don't want to be a house slave !
It's a lot of hard work , It's over , It's time to return to today's theme . Why not put these data into a document table for analysis , Do as you say , Let's use reptiles to crawl , Then write the document .
Web crawler (Crawler): Also known as web spider , Or cyber robots (Robots). It's a rule of thumb , A program or script that automatically grabs information from the world wide web . In other words , It can automatically obtain the web content according to the link address of the web page . If the Internet is compared to a big spider web , There are many web pages in it , Web spiders can get the content of all web pages .
Reptiles Is a simulation of human request website behavior , A program or automated script that downloads Web resources in batches .Reptiles : Use any technical means , A way to get information about a website in bulk . The key is volume .
The crawler : Use any technical means , A way to prevent others from obtaining their own website information in bulk . The key is also volume .
Accidental injury : In the process of anti crawler , Wrong identification of ordinary users as reptiles . Anti crawler strategy with high injury rate , No matter how good the effect is .
Intercept : Successfully blocked crawler access . Here's the concept of interception rate . Generally speaking , Anti crawler strategy with higher interception rate , The more likely it is to be injured by mistake . So there's a trade-off .
resources : The sum of machine cost and labor cost .
(1) Request web page :
adopt HTTP The library makes a request to the target site , Send a Request, The request can contain additional headers etc.
Information , Wait for the server to respond !
(2) Get the corresponding content :
If the server can respond normally , You'll get one Response,Response The content of is the content of the page , There may be HTML,Json character string , binary data ( Like picture video ) Other types .
(3) Parsing content :
What you get may be HTML, You can use regular expressions 、 Web page parsing library for parsing . May be Json, Sure
Go straight to Json Object parsing , It could be binary data , It can be preserved or further processed .
(4) Store parsed data :
There are various forms of preservation , Can be saved as text , It can also be saved to a database , Or save a file in a specific format
Test cases :
Code Realization : Crawl the page data of house prices in Guiyang
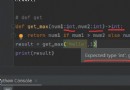
#========== guide package =============
import requests
#=====step_1 : finger set url=========
url = 'https://gy.fang.lianjia.com/ /'
#=====step_2 : Hair rise please seek :======
# send use get Fang Law Hair rise get please seek , The Fang Law Meeting return return One individual ring Should be Yes like . ginseng Count url surface in please seek Yes Should be Of url
response = requests . get ( url = url )
#=====step_3 : a take ring Should be Count According to the :===
# through too transfer use ring Should be Yes like Of text Belong to sex , return return ring Should be Yes like in save Store Of word operator strand shape type Of ring Should be Count According to the ( page Noodles Source Code number According to the )
page_text = response . text
#====step_4 : a For a long time turn save Store =======
with open (' Guiyang house price . html ','w', encoding ='utf -8') as fp:
fp.write ( page_text )
print (' climb take Count According to the End BI !!!') 
climb take Count According to the End BI !!!
Process finished with exit code 0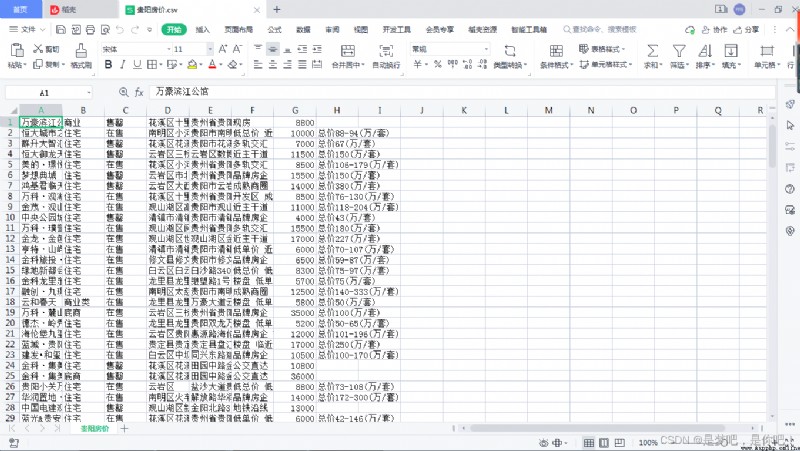

#================== Import related libraries ==================================
from bs4 import BeautifulSoup
import numpy as np
import requests
from requests.exceptions import RequestException
import pandas as pd
#============= Read the web page =========================================
def craw(url,page):
try:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3947.100 Safari/537.36"}
html1 = requests.request("GET", url, headers=headers,timeout=10)
html1.encoding ='utf-8' # Add code , important ! Convert to string encoding ,read() Get is byte Format
html=html1.text
return html
except RequestException:# Other questions
print(' The first {0} Failed to read page '.format(page))
return None
#========== Parse the web page and save the data to the table ======================
def pase_page(url,page):
html=craw(url,page)
html = str(html)
if html is not None:
soup = BeautifulSoup(html, 'lxml')
"-- First determine the house information , namely li Tag list --"
houses=soup.select('.resblock-list-wrapper li')# List of houses
"-- Then determine the information of each house --"
for j in range(len(houses)):# Traverse every house
house=houses[j]
" name "
recommend_project=house.select('.resblock-name a.name')
recommend_project=[i.get_text()for i in recommend_project]# name Yinghua Tianyuan , Binxin Jiangnan imperial residence ...
recommend_project=' '.join(recommend_project)
#print(recommend_project)
" type "
house_type=house.select('.resblock-name span.resblock-type')
house_type=[i.get_text()for i in house_type]# Office buildings , commercial real estate under residential buildings ...
house_type=' '.join(house_type)
#print(house_type)
" Sales status "
sale_status = house.select('.resblock-name span.sale-status')
sale_status=[i.get_text()for i in sale_status]# On sale , On sale , sell out , On sale ...
sale_status=' '.join(sale_status)
#print(sale_status)
" Large address "
big_address=house.select('.resblock-location span')
big_address=[i.get_text()for i in big_address]#
big_address=''.join(big_address)
#print(big_address)
" Specific address "
small_address=house.select('.resblock-location a')
small_address=[i.get_text()for i in small_address]#
small_address=' '.join(small_address)
#print(small_address)
" advantage ."
advantage=house.select('.resblock-tag span')
advantage=[i.get_text()for i in advantage]#
advantage=' '.join(advantage)
#print(advantage)
" Average price : How many? 1 flat "
average_price=house.select('.resblock-price .main-price .number')
average_price=[i.get_text()for i in average_price]#16000,25000, The price is to be determined ..
average_price=' '.join(average_price)
#print(average_price)
" The total price , Ten thousand units "
total_price=house.select('.resblock-price .second')
total_price=[i.get_text()for i in total_price]# The total price 400 ten thousand / set , The total price 100 ten thousand / set '...
total_price=' '.join(total_price)
#print(total_price)
#===================== Write table =================================================
information = [recommend_project, house_type, sale_status,big_address,small_address,advantage,average_price,total_price]
information = np.array(information)
information = information.reshape(-1, 8)
information = pd.DataFrame(information, columns=[' name ', ' type ', ' Sales status ',' Large address ',' Specific address ',' advantage ',' Average price ',' The total price '])
information.to_csv(' Guiyang house price .csv', mode='a+', index=False, header=False) # mode='a+' Append write
print(' The first {0} Page storage data succeeded '.format(page))
else:
print(' Parse failure ')
#================== Two threads =====================================
import threading
for i in range(1,100,2):# Traverse the web 1-101
url1="https://gy.fang.lianjia.com/loupan/pg"+str(i)+"/"
url2 = "https://gy.fang.lianjia.com/loupan/pg" + str(i+1) + "/"
t1 = threading.Thread(target=pase_page, args=(url1,i))# Threads 1
t2 = threading.Thread(target=pase_page, args=(url2,i+1))# Threads 2
t1.start()
t2.start()