Preface
use first Python take Word File import
row and cell Parsing required content
Inner parsing loop
PrefaceHello everyone , Today there is a civil servant junior partner asked me to give him a favor , Probably there is such a Word( Due to privacy related to specific contents of the file so the text has been specifically modified )

A total of nearly 2600 Thin strip table column similar format , Each section contains information there :
date
Units issued
Number
title
Bar sign
We need to extract the contents to a bold three Excel Table storage , The following table style :
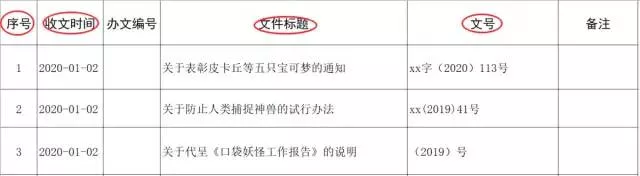
That is to say, the time of receiving the document 、 Document title 、 Number fill to the specified location , At the same time it needs to be changed to standard time format , If it is completely manually copy and modify time , According to an entry 10s The time calculation , A minute to complete 6 strip , Then the fastest also need :
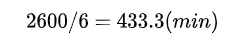
And this kind of structured file arrangement is very suitable for Python To execute , Good then the next please Python appearance , I have the necessary information to comment information presented in the code .
use first Python take Word File import# Import required libraries docxfrom docx import Document# Specify the file storage path path = r'C:\Users\word.docx' # Read the file document = Document(path)# Read word All tables in tables = document.tablesThen divide-by-issue , First, try to get the first table entry of the first file three required information
# Get the first table table0 = tables[0]Careful observation can be found in a file entry occupies 3 That's ok , So when all the lines in the table iteration of the loop can be set in steps of 3
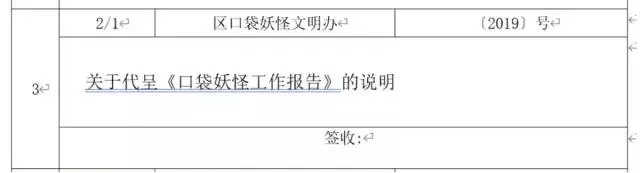
Observe table , according to row and cell The content analysis clearly needed
# Put in a global variable for counting number to fill n = 0for i in range(0, len(table0.rows) + 1, 3): # date date = table0.cell(i, 1).text # title title = table0.cell(i + 1, 1).text.strip() # Number dfn = tables[j].cell(i, 3).text.strip() print(n, date, tite, dfn) Next we need to address is , Time we have obtained is 2/1 such Japan / The form of the month . We need to be converted into YYYY-MM-DD Format , This use to datetime Bag strptime and strftime function :
strptime: Contained in parsing a string time
strftime: Conversion to the desired time format
import datetimen = 0for i in range(0, len(table0.rows) + 1, 3): # date date = table0.cell(i, 1).text # Some time entry is empty , Not too much discrimination here if '/' in date: date = datetime.datetime.strptime(date, '%d/%m').strftime('2020-%m-%d') else: date = '-' # title title = table0.cell(i + 1, 1).text.strip() # Number dfn = tables[j].cell(i, 3).text.strip() print(n, date, tite, dfn)Such a table of contents parsing is done , Notice I'm using theta table[0] That first table , Through all the tables plus a nested loop can , Alternatively, you can capture an abnormal increase in the flexibility of the program
n = 0for j in range(len(tables)): for i in range(0, len(tables[j].rows)+1, 3): try: # date date = tables[j].cell(i, 1).text if '/' in date: date = datetime.datetime.strptime(date, '%d/%m').strftime('2020-%m-%d') else: date = '-' # title title = tables[j].cell(i + 1, 1).text.strip() # Number dfn = tables[j].cell(i, 3).text.strip() n += 1 print(n, date, title, dfn) except Exception as error: # Capture exception , It can also be used. log Written log for easy viewing and management print(error) continue Information analysis and can export the completed acquisition , The package is used openpyxl
from openpyxl import Workbook# Instantiation wb = Workbook()# Get current sheetsheet = wb.active# Set up the header header = [' Serial number ', ' Time of receipt ', ' Office of the text number ', ' Document title ', ' Number ', ' remarks ']sheet.append(header) Inner parsing loop At the end of the innermost loop parsing code below to add
row = [n, date, ' ', title, dfn, ' ']sheet.append(row)Finally, remember to save the thread
wb.save(r'C:\Users\20200420.xlsx')Running time at 10 About minutes , Probably leave for a while on the implementation of the program ended
Finally, attach the complete code , The code is simple , The most important sort out ideas
from docx import Documentimport datetimefrom openpyxl import Workbookwb = Workbook()sheet = wb.activeheader = [' Serial number ', ' Time of receipt ', ' Office of the text number ', ' Document title ', ' Number ', ' remarks ']sheet.append(header)path = r'C:\Users\word.docx'document = Document(path)tables = document.tablesn = 0for j in range(len(tables)): for i in range(0, len(tables[j].rows)+1, 3): try: # date date = tables[j].cell(i, 1).text if '/' in date: date = datetime.datetime.strptime(date, '%d/%m').strftime('2020-%m-%d') else: date = '-' # title title = tables[j].cell(i + 1, 1).text.strip() # Number dfn = tables[j].cell(i, 3).text.strip() n += 1 print(n, date, title, dfn) row = [n, date, ' ', title, dfn, ' '] sheet.append(row) except Exception as error: # Capture exception , It can also be used. log Written log for easy viewing and management print(error) continuewb.save(r'C:\Users\20200420.xlsx')That's all Python Office automation Word turn Excel Details of document batch processing , More about Python Office automation Word turn Excel Please pay attention to other relevant articles of software development network !