資源下載地址:https://download.csdn.net/download/sheziqiong/85836603
資源下載地址:https://download.csdn.net/download/sheziqiong/85836603
選題:設計實現一種基於文本內容/情感的文本自動分類方法
具體目標:實現一個分類器,完成對微博文本的簡單二元分類,即分為正面、負面。
微博文本不同於正式文本,作為在網絡社區上的文本,具有不規范性、流行性、符號混雜性等特點,具體總結了以下四點:
2、4給處理上帶來方便,特別是文本化的表情符號能夠增加情緒詞權重;而 1、3 是挑戰,需要數據量盡量大,涵蓋更多的語言現象。
而在中期報告中也提出,由於句子中與情緒表達無關的文本的存在,直接使用分類的方法對於長文本不適用,需要進行過濾,並且傳統分類方法忽略了詞間的語義聯系,使得訓練集的規模需求變大,在沒有大的微博語料庫的情況下也很難取得好的效果。
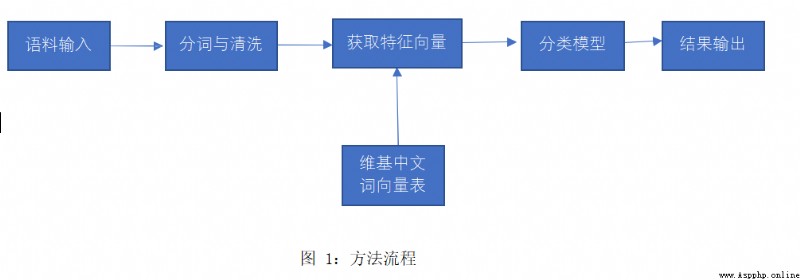
因此,本文考慮結合詞向量和傳統分類方法,可以在某個大規模語料庫上訓練詞向量表,繼而用微博文本中詞向量的平均獲得整個文本的向量,用向量作為輸入來進行分類。同時,當輸入不再需要完整的文本時,過濾無用文本也就成為可能,刪除連詞、介詞等並不會對句子中的關鍵信息有影響。詞向量模型照顧到了語義聯系,也符合情緒本質上是語義層面的特點;而傳統分類方法訓練速度較深度學習方法快,消耗計算資源較小,效果也沒有絕對的差距,因此適合在個人電腦上運行。
維基百科中文語料( ):用於訓練詞向量表
第二屆 CCF 自然語言處理與中文計算會議中文微博情感分析樣例數據:本項目微博語料來源中科院計算所中文自然語言處理開放平台發布的中文停用詞表 StopWord.txt:用於過濾無用文本
首先由維基百科中文語料獲取詞向量表,借助模塊為 python 中開源的 genism,其中包括了針對維基百科語料訓練詞向量的方法。
之後對微博語料進行預處理,下載的樣例數據中並不是簡單的正負二元分類,其分類包括:anger 憤怒、disgust 厭惡、fear 恐懼、happiness 快樂、like 喜好、sadness 悲傷、surprise 驚訝、none 中性。我將 anger 憤怒、disgust 厭惡、fear 恐懼、sadness 悲傷歸為負面,happiness 快樂、like 喜好歸為正面,最終獲得各 1029 句的正負平衡語料,命名為 neg.txt 和 pos.txt。
對正負語料進行分詞,借助模塊為 jieba(結巴分詞);使用停用詞表進行文本清洗; 最終對照詞向量表並取平均值獲得句子的特征向量。獲得的特征向量維數為 400,為節約計算資源、加快速度,使用 PCA 分析作圖,發現 100 維即可包含幾乎全部信息,因此降維至 100。
隨機劃分訓練集與驗證集為 95:5。驗證集有 102 句,其中負面 48 句,正面 54 句。
使用三種分類模型進行比較研究,為 SVM、BP 神經網絡、隨機森林。分別在訓練集上訓練得到模型,調用模型在驗證集上進行驗證。
1.評價指標
表 1:混淆矩陣
TP、TN 表示分類結果與實際標簽一致的文本數,FN、FP 表示分類結果與實際標簽不一致的文本數。
准確率:P=TP/(TP+FP)
召回率:R=TP/(TP+FN)
F1 值:F1=2P*R/(P+R)
2.實驗結果
在驗證集上測試結果如下表:
表 2:驗證結果
3.實驗結果分析
資源下載地址:https://download.csdn.net/download/sheziqiong/85836603
資源下載地址:https://download.csdn.net/download/sheziqiong/85836603