Hello, tie Zhimeng ~ Today, Xiaobian is going to teach you how to remove pictures and PDF Watermark in ~
Is this the humble you who always ask people to send the original picture


But after this period, we can stand up ! This watermark ~ EH ! I mean, we can go as we like
It's downloaded from the Internet pdf Some of the learning materials will be watermarked , It affects reading very much . For example, the following picture is in pdf Intercepted from the file . Now let's look at using Python How to remove these watermarks !

PIL:Python Imaging Library yes python A very powerful image processing standard library , But it can only support python 2.7, So there are volunteers PIL Created support based on python 3 Of pillow, And added some new features .
pip install pillowpymupdf It can be used python The access extension is *.pdf、.xps、.oxps、.epub、.cbz or *.fb2 The file of . It also supports many popular image formats , Include multiple pages TIFF Images .
pip install PyMuPDFImport the modules needed
from PIL import Image
from itertools import product
import fitz
import ospdf The principle of de watermarking is similar to that of image de watermarking , Xiaobian starts with removing the watermark of the picture above .
All my friends who have studied computer know , Used in computers RGB Red, green and blue , use (255, 0, 0) It means red ,(0, 255, 0) It means green ,(0, 0, 255) It means blue ,(255, 255, 255) Said the white ,(0, 0, 0) According to black , The principle of de watermarking is to change the color of the watermark into white (255, 255, 255).
First get the width and height of the picture , use itertools The module obtains the Cartesian product of width and height as pixels . The color of each pixel is determined by The top three RGB and Number four Alpha Channel composition .Alpha The channel does not need to , as long as RGB data .
def remove_img():
image_file = input(" Please enter the picture address :")
img = Image.open(image_file)
width, height = img.size
for pos in product(range(width), range(height)):
rgb = img.getpixel(pos)[:3]
print(rgb)Use wechat screenshots to view the watermark pixels RGB.
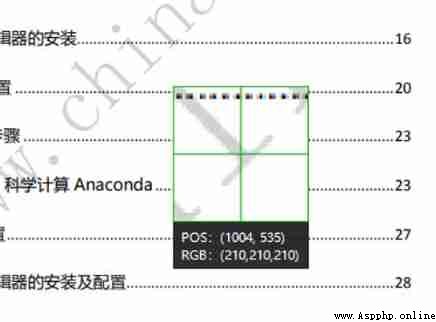
You can see the watermark RGB yes (210, 210, 210), Here we use RGB And more than 620 It is determined to be the watermark point , Replace the pixel color with white . Finally save the picture .
rgb = img.getpixel(pos)[:3]
if(sum(rgb) >= 620):
img.putpixel(pos, (255, 255, 255))
img.save('d:/qsy.png')Sample results :

PDF The principle of de watermarking is roughly the same as that of image de watermarking , use PyMuPDF open pdf After the document , take pdf Every page of is converted into a picture pixmap,pixmap It has its own RGB, Only need to pdf In the watermark RGB Change it to (255, 255, 255) Finally save as a picture .
def remove_pdf():
page_num = 0
pdf_file = input(" Please enter pdf Address :")
pdf = fitz.open(pdf_file);
for page in pdf:
pixmap = page.get_pixmap()
for pos in product(range(pixmap.width), range(pixmap.height)):
rgb = pixmap.pixel(pos[0], pos[1])
if(sum(rgb) >= 620):
pixmap.set_pixel(pos[0], pos[1], (255, 255, 255))
pixmap.pil_save(f"d:/pdf_images/{page_num}.png")
print(f" The first {page_num} Watermark removal is complete ")
page_num = page_num + 1Sample results :

Picture turn pdf It should be noted that the order of pictures , The digital file name must first be converted to int Sort after type . use PyMuPDF After the module opens the picture, use convertToPDF() Function into a single page pdf. Insert into new pdf In file .
def pic2pdf():
pic_dir = input(" Please enter the picture folder path :")
pdf = fitz.open()
img_files = sorted(os.listdir(pic_dir),key=lambda x:int(str(x).split('.')[0]))
for img in img_files:
print(img)
imgdoc = fitz.open(pic_dir + '/' + img)
pdfbytes = imgdoc.convertToPDF()
imgpdf = fitz.open("pdf", pdfbytes)
pdf.insertPDF(imgpdf)
pdf.save("d:/demo.pdf")
pdf.close()pdf And annoying watermarks on pictures can finally be used in powerful python Disappeared in front of . Have you learned how to ?
Take the iron juice you learned to have a try ! Remember to make up a series for Xiao before you leave ~
Want to get the complete source code and python Click this line for learning materials