公眾號:尤而小屋
作者:Peter
編輯:Peter
今天給大家分享一個粉絲朋友問的一道關於Pandas題,提供多種解決思路!

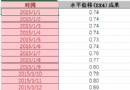
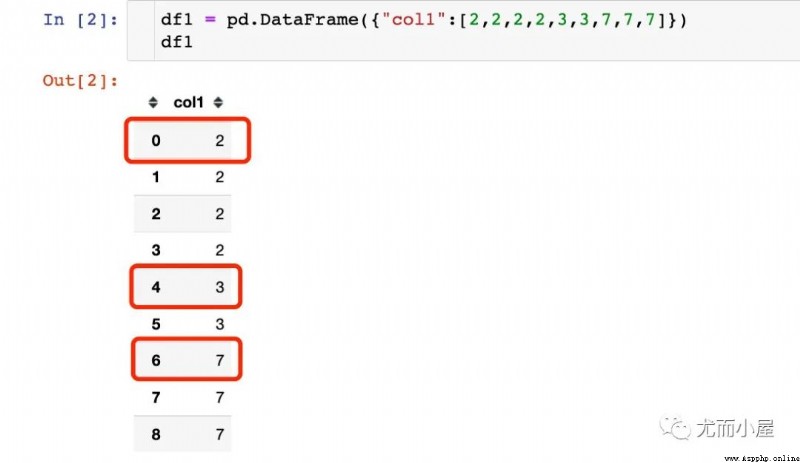
有下面的這樣一個DataFrame(數據是模擬的),找出每個數值第一次出現的索引號:
2第一次出現索引為0
3第一次出現索引為4
7第一次出現索引為6
這就是最終要展現的結果,如何解決?下面提供不同的解決思路
shift函數是在指定的軸方向上進行移動指定的長度:
1、先向下移動一個單位,得到df2

2、為了後面的處理,df2進行屬性字段的重命名:
df2.rename(columns={"col1":"col2"},inplace=True)3、將df1和df2進行合並

4、篩選col1和col2不等的情況即可
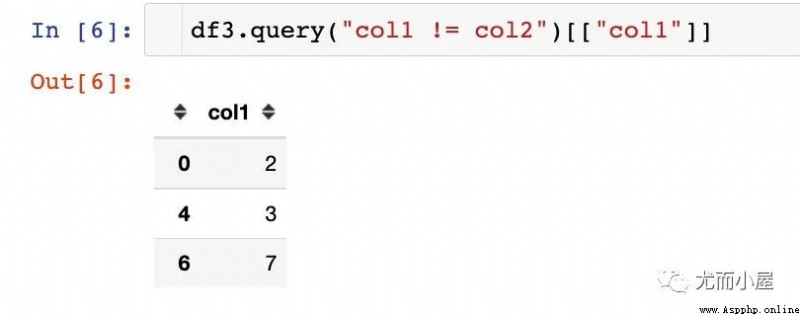
完整的一行代碼如下:
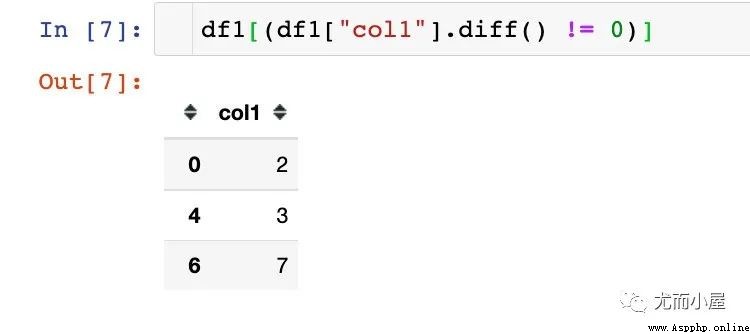
下面我們拆解下這行代碼:
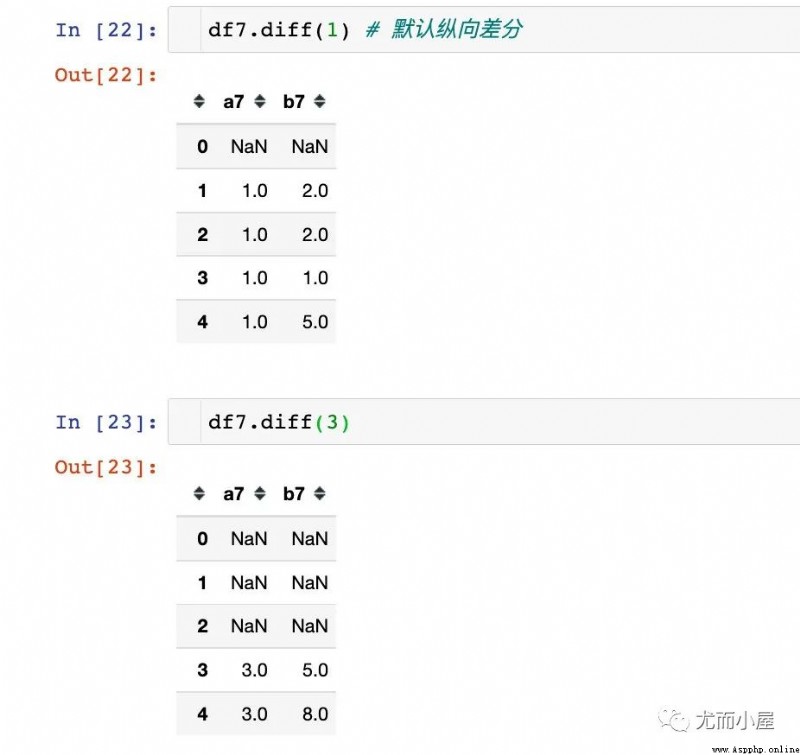
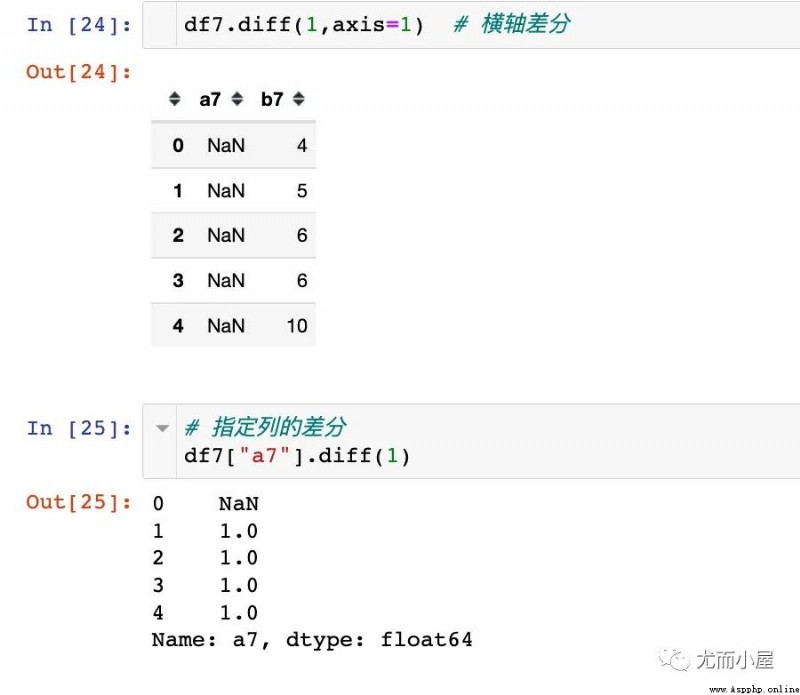
1、差分函數diff
每個數據和前一個數值相減;如果兩個值相等,差值為0

2、判斷和0的關系
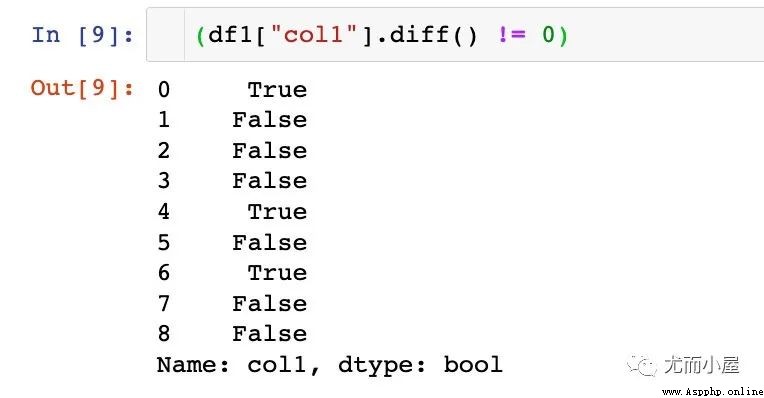
3、鎖定為True的值即可
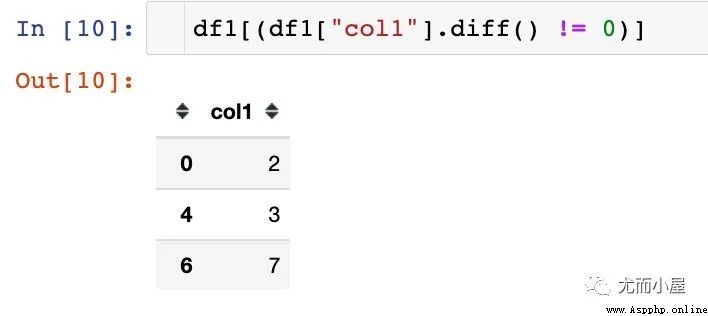
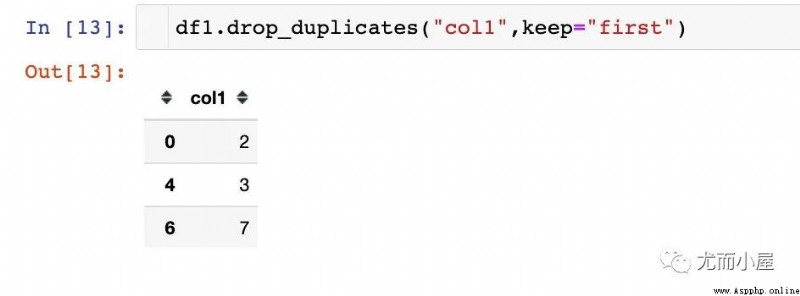
一個很巧妙的方法:直接去重,保留第一條數據;但這僅僅是特例
需求還是類似,找出每個數值第一次出現的索引;但是數據會重復隔斷出現。
下面已經標記了正確的結果:

還是可以解決

結果:

同樣可以解決:

但是去重函數在這種情況就不行:drop_duplicates函數是對整體數據的去重,只保留一條數據

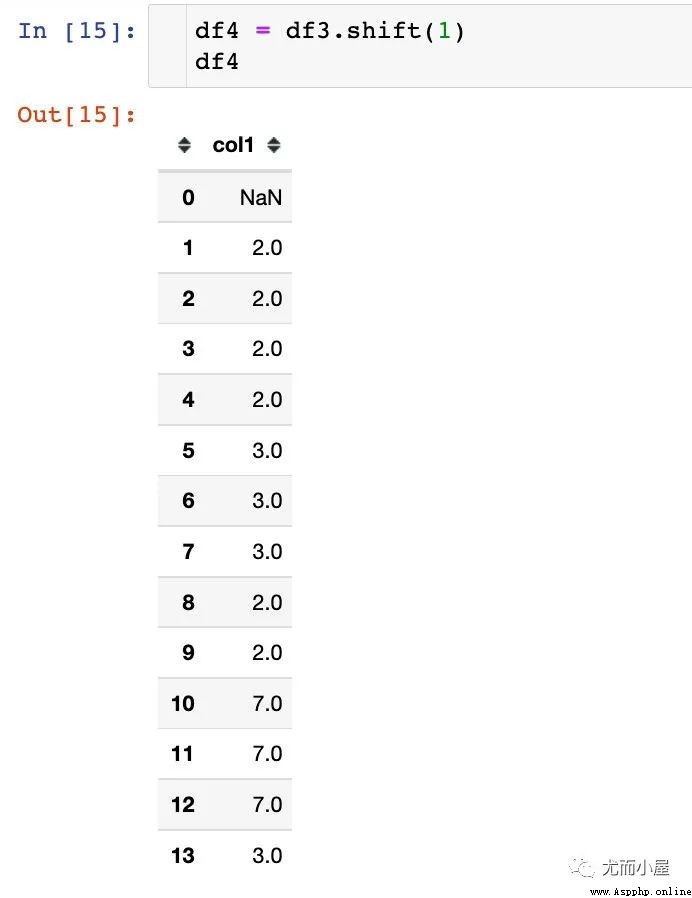
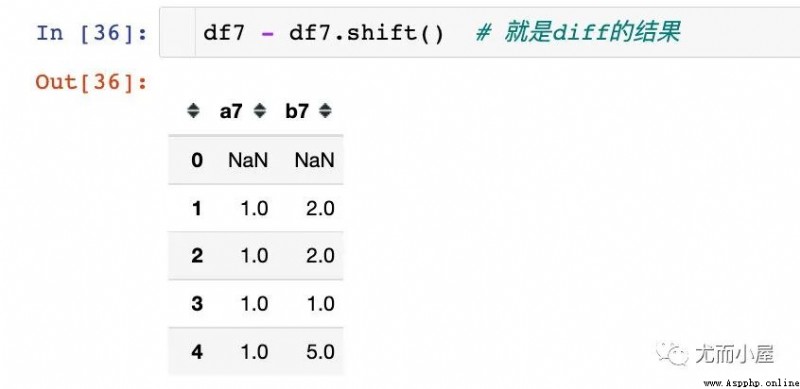
在這裡重點理解下移位函數shift和差分函數diff的關系,模擬一份數據:


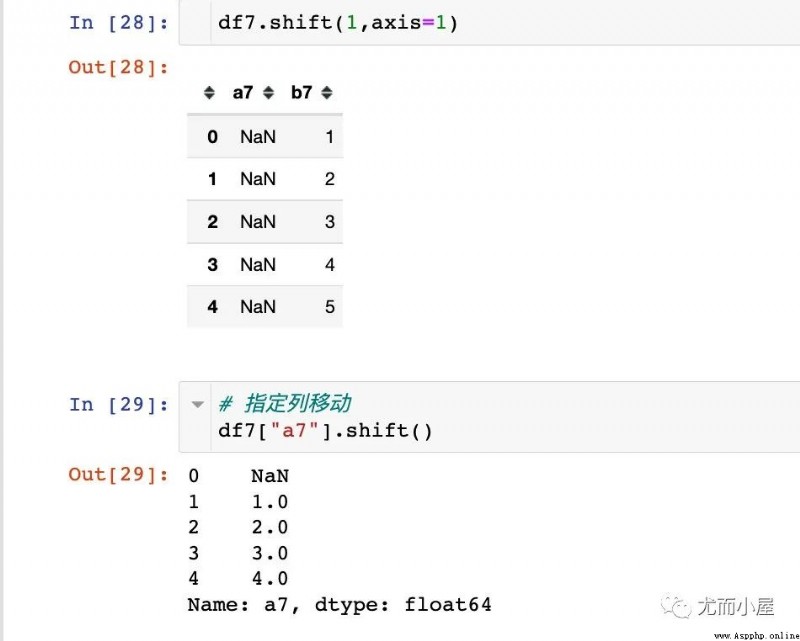
以默認移動一個單位為例
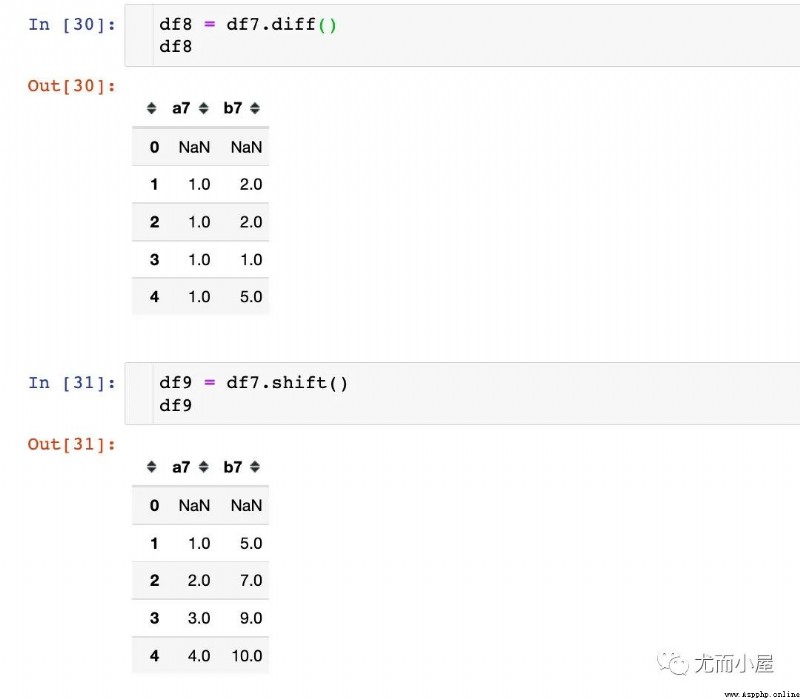
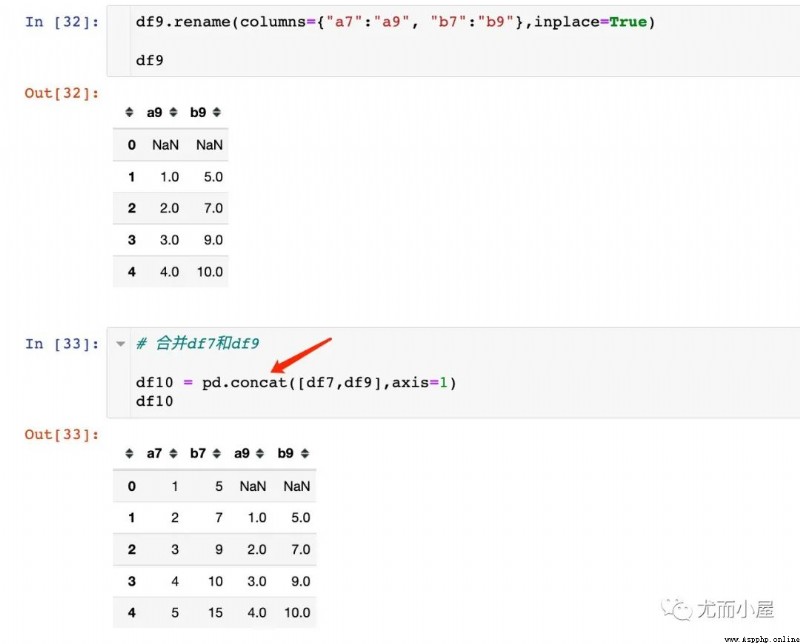
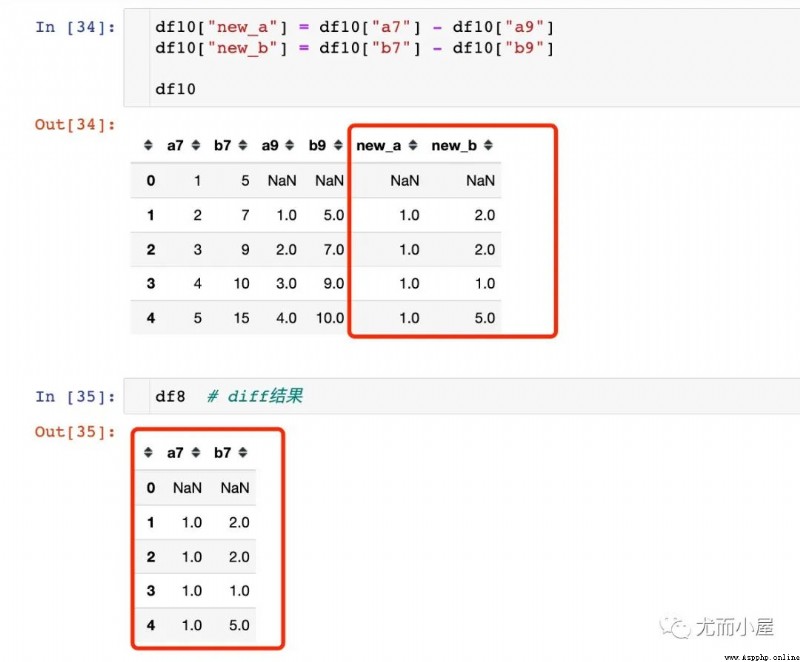
結論:在相同的條件下,原數據框 減掉 shift函數生成的數據就是diff函數的結果
什麼情況下會用到移位或者差分函數?

往期精彩回顧
適合初學者入門人工智能的路線及資料下載(圖文+視頻)機器學習入門系列下載中國大學慕課《機器學習》(黃海廣主講)機器學習及深度學習筆記等資料打印《統計學習方法》的代碼復現專輯機器學習交流qq群955171419,加入微信群請掃碼