notes : This blog doesn't have any tutorials , Only the code and some comments , The blogger saw it by himself ! Just learning python Three days , No joy, no spray.
function :
1. Analyze homepage resources
2. Analyze the resource page link under the corresponding title of the home page
3. Automatically resolve the link of each resource .ts Number
4. Automatically resolve the corresponding of each resource .m3u8 resources ( Used to analyze the number of fragments )
5. Store by title
The code only provides the idea of crawler implementation , Cannot reuse
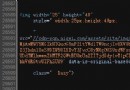
code:
import multiprocessing
import os
import string
import requests
import re
from bs4 import BeautifulSoup
from multiprocessing import Pool
# Header information
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.97 Safari/537.36"}
# m3u8 Prefix of file link ( All link prefixes are the same , So extract it )
m3u8path = "https://xxx.xxx.com/"
# Each resource link prefix ( All link prefixes are the same , So extract it )
repath = "https://xxx.xxx.de/"
# Request home page , And analyze html Get links to all resource pages
response = requests.get("https://www.xxx.xx/xxx.html", headers=headers)
# Set character encoding
response.encoding = "utf-8"
# Get home page html
syHtml = response.text
soup = BeautifulSoup(syHtml, "lxml")
# Analysis of home page html( Use css Selector positioning elements )
resourceList = soup.select("a[class='video-pic loading']")
# Save all resource links on the homepage in matrix Array
matrix = []
# Put all the elements of href Extract the label content
for i in range(0, len(resourceList)):
matrix.insert(i, resourceList[i].get("href"))
for url in matrix:
response1 = requests.get(repath+url, headers=headers)
response1.encoding="utf-8"
# Get links to each resource html Content
rehtml=response1.text
# The following code parses the resource page m3u8 link
soup1 = BeautifulSoup(rehtml, "lxml")
reinfo = soup1.select_one("#vpath")
# The following code gets the title of each video
title = soup1.select_one(".player_title>h1").text.split()
# request m3u8, To calculate the ts Number of documents
response2 = requests.get(m3u8path+reinfo.text.strip(), headers=headers)
response2.encoding = "utf-8"
count = response2.text.count("ts")
# The following code parses ts link
flag = 0
num = 0
while 1 == 1:
try:
k = (m3u8path + reinfo.text.strip()).index("/", num)
num = k+1
except:
flag=num
break
# It is concluded that url Prefix
vedioUrlPre = (m3u8path + reinfo.text.strip())[0:int(flag)]
# Crawl the current resource
for i in range(0,count):
vedioUrl = vedioUrlPre + "%04d.ts" % i
response3 = requests.get(vedioUrl, headers=headers)
dir = "D:\\ Reptiles \\" + str(title)
if not os.path.exists(dir):
os.makedirs(dir)
file = open(dir+"\\{}".format(vedioUrl[-7:]), "wb")
print(" Start writing resources :"+ url +" Of the " + str(i)+" A fragment ")
file.write(response.content)
print(" Write fragment " + str(i) + " end \n")
file.close()
print(" All videos are crawled !!!")