Steam By the American video game company Valve On 2003 year 9 month 12 The digital distribution platform launched on the th , It is considered to be one of the largest digital distribution platforms in the computer game industry ,Steam The platform is one of the largest comprehensive digital distribution platforms in the world . Players can buy 、 download 、 Discuss 、 Upload and share games and software .

And every week steam The meeting opened a round of special offers , You can discount the game , And players will buy the game they want
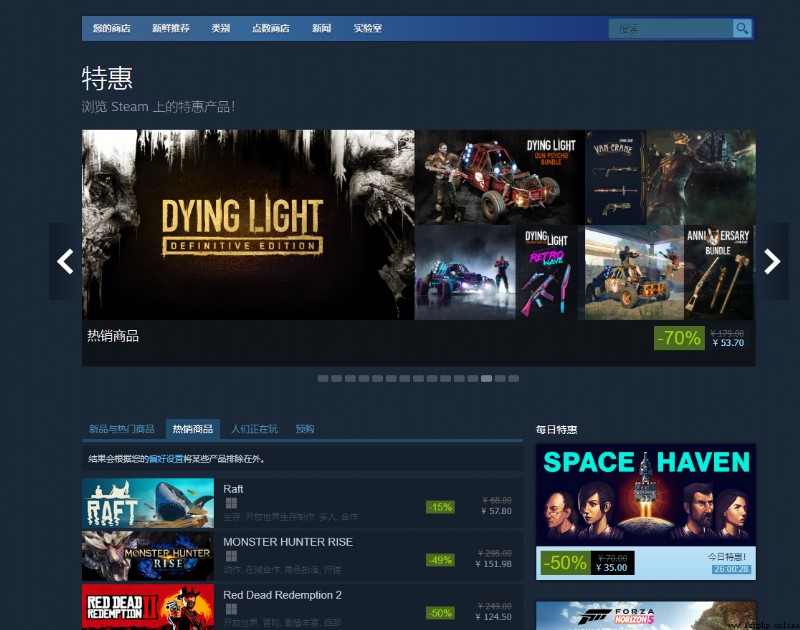
It is said that every time there is a big discount , Countless players will buy games , It can make G Fat loss death

import random
import time
import requests
import parsel
import csv
Modules can pycharm Direct installation in , Input pip install XXX( Module name ) Just go
url = f'https://store.steampowered.com/contenthub/querypaginated/specials/TopSellers/render/?query=&start=1&count=15&cc=TW&l=schinese&v=4&tag='
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
}
response = requests.get(url=url, headers=headers)
html_data = response.json()['results_html']
print(html_data)
In this way, the source code of the web page is obtained 
selector = parsel.Selector(html_data)
lis = selector.css('a.tab_item')
for li in lis:
href = li.css('::attr(href)').get()
title = li.css('.tab_item_name::text').get()
tag_list = li.css('.tab_item_top_tags .top_tag::text').getall()
tag = ''.join(tag_list)
price = li.css('.discount_original_price::text').get()
price_1 = li.css('.tab_item_discount .discount_final_price::text').get()
discount = li.css('.tab_item_discount .discount_pct::text').get()
print(title, tag, price, price_1, discount, href)
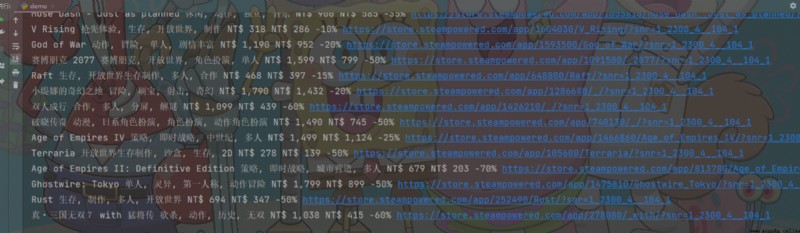
First save the data in the dictionary
dit = {
' game ': title,
' label ': tag,
' The original price ': price,
' The price is ': price_1,
' discount ': discount,
' Details page ': href,
}
csv_writer.writerow(dit)
Finally save it to csv in
f = open(' game _1.csv', mode='a', encoding='utf-8', newline='')
csv_writer = csv.DictWriter(f, fieldnames=[
' game ',
' label ',
' The original price ',
' The price is ',
' discount ',
' Details page ',
])
csv_writer.writeheader()

Python Crawling 【steam Preferential 】 Game data ( Game name 、 The game type 、 The original price 、 Discount price, etc )