GIL的全稱是Global Interpreter Lock(全局解釋器鎖),為了數據安全,GIL保證同一時間只能有一個線程拿到數據。所以,在python中,同時只能執行一個線程。
而IO密集型,多線程能夠有效提昇效率( 單線程下有IO操作會進行IO等待,造成不必要的時間浪費,而開啟多線程能在線程A等待時,自動切換到線程B,可以不浪費CPU的資源,從而能提昇程序執行效率 )。所以python多線程對IO密集型代碼比較友好。
而CPU密集型( 各種循環處理、計算等等 ),由於計算工作多,計時器很快就會達到閾值,然後觸發GIL的釋放與再競爭( 多個線程來回切換當然是需要消耗資源的 ),所以python多線程對CPU密集型代碼並不友好。
Python在使用多線程的時候,調用的是c語言的原生線程。
筆記:有些沒看懂?
threading.Thread(group=None, target=None, name=None, args=(), kwargs={}, *, daemon=None)
調用這個構造函數時,必需帶有關鍵字參數。參數如下:
group 應該為 None;為了日後擴展 ThreadGroup 類實現而保留。
target 是用於 run() 方法調用的可調用對象(一個函數)。默認是 None,錶示不需要調用任何方法。
name 是線程名稱。默認情況下,由 “Thread-N” 格式構成一個唯一的名稱,其中 N 是小的十進制數。多個線程可以賦予相同的名稱。
args 是用於調用目標函數的參數元組。默認是 ()。
kwargs 是用於調用目標函數的關鍵字參數字典。默認是 {}。
daemon 參數如果不是 None,將顯式地設置該線程是否為守護模式。 如果是 None (默認值),線程將繼承當前線程的守護模式屬性。
3.3 版及以上才具有該屬性。
注意:一定要在調用 start() 前設置好,不然會拋出 RuntimeError 。
初始值繼承於創建線程;主線程不是守護線程,因此主線程創建的所有線程默認都是 daemon = False。
當沒有存活的非守護線程時,整個Python程序才會退出。
如果子類型**重載了構造函數,**它一定要確保在做任何事前,先發起調用基類構造器(Thread.init())。
名詞解釋:守護模式
有一種線程,它是在後臺運行的,它的任務是為其他線程提供服務,這種線程被稱為“後臺線程(Daemon Thread)”,又稱為“守護線程”或“精靈線程”。Python 解釋器的垃圾回收線程就是典型的後臺線程。
後臺線程有一個特征,如果所有的前臺線程都死亡了,那麼後臺線程會自動死亡。
開始線程活動。
它在一個線程裏最多只能被調用一次。它安排對象的 run() 方法在一個獨立的控制進程中調用。
如果同一個線程對象中調用這個方法的次數大於一次,會拋出 RuntimeError 。
等待,直到線程終結。
這會阻塞調用這個方法的線程,直到被調用 join() 的線程終結。
當 timeout 參數存在而且不是 None 時,它應該是一個用於指定操作超時的以秒為單比特的浮點數(或者分數)。
因為 join() 總是返回 None ,所以你一定要在 join() 後調用is_alive()才能判斷是否發生超時 ,如果線程仍然存活,則 join() 超時。
當 timeout 參數不存在或者是 None ,這個操作會阻塞直到線程終結。
一個線程可以被 join() 很多次。
import threading # 線程模塊
import time
def run(n):
print("task", n)
time.sleep(1)
print('2s')
time.sleep(1)
print('3s')
if __name__ == '__main__':
th = threading.Thread(target=run,name="thread_1" args=("thread 1",), daemon=True) # 創建線程
# 把子進程設置為守護線程,**必須在start()之前設置
th.setDaemon(True) # 設置守護線程,其實在創建時已經 設置了 daemon=True
th.start()
# 設置主線程等待子線程結束
th.join()
print("end")
由於線程之間是進行隨機調度,並且每個線程可能只執行n條執行之後,當多個線程同時修改同一條數據時可能會出現髒數據(筆記:Python基礎數據類型、列錶、元組、字典都是線程安全的,因此不會導致程序崩潰,但會導致數據出現未知值,即髒數據),
所以出現了線程鎖,即同一時刻允許一個線程執行操作。線程鎖用於鎖定資源,可以定義多個鎖,像下面的代碼,當需要獨占某一個資源時,任何一個鎖都可以鎖定這個資源,就好比你用不同的鎖都可以把這個相同的門鎖住一樣。
由於線程之間是進行隨機調度的,如果有多個線程同時操作一個對象,並且沒有很好地保護該對象,會造成程序結果的不可預期,我們因此也稱為“線程不安全”。
為了防止上面情況的發生,就出現了鎖。
我在5種Python線程鎖中有詳細講述。
概念補充:
以下分5種不同的形式解釋join在多線程編程中的用處
Python多線程的默認情況(設置線程setDaemon(False)),主線程執行完自己的任務以後,就退出了,此時子線程會繼續執行自己的任務,直到自己的任務結束
筆記:setDaemon(False) 即 該線程被設置為非守護線程;主程序退出後,子線程不會自動退出。
import threading, time
def doWaiting1():
print('start waiting1: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(3)
print("線程1奉命報道")
print('stop waiting1: ' + time.strftime('%H:%M:%S') + "\n")
def doWaiting2():
print('start waiting2: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(8)
print("線程2奉命報道")
print('stop waiting2: ', time.strftime('%H:%M:%S') + "\n")
tsk = [] # 線程列錶
# 創建並開啟線程1
thread1 = threading.Thread(target = doWaiting1)
thread1.start() # start()函數 實際調用 RUN()函數(Python調用的是 C語言的線程)
tsk.append(thread1)
# 創建並開啟線程2
thread2 = threading.Thread(target = doWaiting2)
thread2.start()
tsk.append(thread2)
# 計時程序
print('start join: ' + time.strftime('%H:%M:%S') )
print('end join: ' + time.strftime('%H:%M:%S') )
運行結果
start waiting1: 20:03:30
start waiting2: 20:03:30
start join: 20:03:30
end join: 20:03:30 # 此處主線程已經結束,而子線程還在繼續工作
線程1奉命報道 # 子線程1 繼續在工作
stop waiting1: 20:03:33
線程2奉命報道
stop waiting2: 20:03:38
結論:
開啟線程的**setDaemon(True),**設置子線程為守護線程,實現主程序結束,子程序立馬全部結束功能
import threading, time
def doWaiting1():
print('start waiting1: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(3)
print("線程1奉命報道")
print('stop waiting1: ' + time.strftime('%H:%M:%S') + "\n")
def doWaiting2():
print('start waiting2: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(8)
print("線程2奉命報道")
print('stop waiting2: ', time.strftime('%H:%M:%S') + "\n")
tsk = []
# 創建並開啟線程1
thread1 = threading.Thread(target = doWaiting1)
thread1.setDaemon(True)
thread1.start()
tsk.append(thread1)
# 創建並開啟線程2
thread2 = threading.Thread(target = doWaiting2)
thread2.setDaemon(True)
thread2.start()
tsk.append(thread2)
print('start join: ' + time.strftime('%H:%M:%S') )
print('end join: ' + time.strftime('%H:%M:%S') )
運行結果:
start waiting1: 20:10:04
start waiting2: 20:10:04
start join: 20:10:04
end join: 20:10:04 # 主線程結束後,子線程立刻結束,無論處於什麼狀態。
結論:
非守護線程,主程序將一直等待子程序全部運行完成才結束
import threading, time
def doWaiting1():
print('start waiting1: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(3)
print("線程1奉命報道")
print('stop waiting1: ' + time.strftime('%H:%M:%S') + "\n")
def doWaiting2():
print('start waiting2: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(8)
print("線程2奉命報道")
print('stop waiting2: ', time.strftime('%H:%M:%S') + "\n")
tsk = []
# 創建並開啟線程1
thread1 = threading.Thread(target = doWaiting1)
thread1.start()
tsk.append(thread1)
# 創建並開啟線程2
thread2 = threading.Thread(target = doWaiting2)
thread2.start()
tsk.append(thread2)
print('start join: ' + time.strftime('%H:%M:%S') )
for t in tsk:
print('%s線程到了'%t)
t.join() # 線程join() 即:兩個線程再次回合,全部完成後才能繼續進行下一行
print('end join: ' + time.strftime('%H:%M:%S') )
運行結果:
start waiting1: 20:14:35
start waiting2: 20:14:35
start join: 20:14:35
<Thread(Thread-1, started 19648)>線程到了
線程1奉命報道
stop waiting1: 20:14:38
<Thread(Thread-2, started 24056)>線程到了
線程2奉命報道
stop waiting2: 20:14:43
end join: 20:14:43 # 兩個線程執行完畢後,才能運行至此
結論:
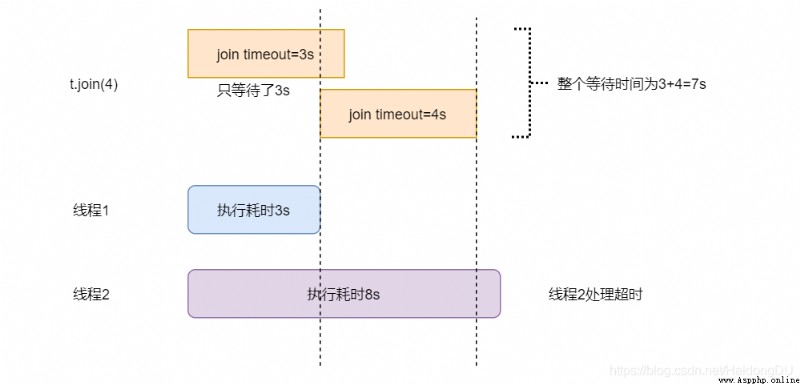
給join設置timeout數值,判斷等待多後子線程還沒有完成,則主線程不再等待
筆記:join設置超時後,判斷依據為 子線程執行完畢 | 超時 (邏輯或的關系),即兩個條件誰先為真,就向下執行。
import threading, time
def doWaiting1():
print('start waiting1: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(2)
print("線程1奉命報道")
print('stop waiting1: ' + time.strftime('%H:%M:%S') + "\n")
def doWaiting2():
print('start waiting2: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(8)
print("線程2奉命報道")
print('stop waiting2: ', time.strftime('%H:%M:%S') + "\n")
tsk = []
# 創建並開啟線程1
thread1 = threading.Thread(target = doWaiting1)
thread1.start()
tsk.append(thread1)
# 創建並開啟線程2
thread2 = threading.Thread(target = doWaiting2)
thread2.start()
tsk.append(thread2)
print('start join: ' + time.strftime('%H:%M:%S') )
for t in tsk:
print("開始:"+time.strftime('%H:%M:%S'))
print('%s線程到了'%t)
t.join(5)
print("結束:" + time.strftime('%H:%M:%S'))
print('end join: ' + time.strftime('%H:%M:%S') )
運行結果:
start waiting1: 21:14:25
start waiting2: 21:14:25
start join: 21:14:25
開始:21:14:25
<Thread(Thread-1, started 22348)>線程到了
線程1奉命報道
stop waiting1: 21:14:27
結束:21:14:27
開始:21:14:27
<Thread(Thread-2, started 13164)>線程到了
結束:21:14:32
end join: 21:14:32
線程2奉命報道
stop waiting2: 21:14:33
結論:
超時且未處理完畢的子線程將被直接終止(符合守護線程的特性)
import threading, time
def doWaiting1():
print('start waiting1: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(2)
print("線程1奉命報道")
print('stop waiting1: ' + time.strftime('%H:%M:%S') + "\n")
def doWaiting2():
print('start waiting2: ' + time.strftime('%H:%M:%S') + "\n")
time.sleep(8)
print("線程2奉命報道")
print('stop waiting2: ', time.strftime('%H:%M:%S') + "\n")
tsk = []
# 創建並開啟線程1
thread1 = threading.Thread(target = doWaiting1)
thread1.setDaemon(True) # 守護線程
thread1.start()
tsk.append(thread1)
# 創建並開啟線程2
thread2 = threading.Thread(target = doWaiting2)
thread2.setDaemon(True) # 守護線程
thread2.start()
tsk.append(thread2)
print('start join: ' + time.strftime('%H:%M:%S') )
for t in tsk:
print("開始:"+time.strftime('%H:%M:%S'))
print('%s線程到了'%t)
t.join(5)
print("結束:" + time.strftime('%H:%M:%S'))
print('end join: ' + time.strftime('%H:%M:%S') )
運行結果:
start waiting1: 21:24:14
start waiting2: 21:24:14
start join: 21:24:14
開始:21:24:14
<Thread(Thread-1, started daemon 9060)>線程到了
線程1奉命報道
stop waiting1: 21:24:16
結束:21:24:16
開始:21:24:16
<Thread(Thread-2, started daemon 13912)>線程到了
結束:21:24:21
end join: 21:24:21
結論: