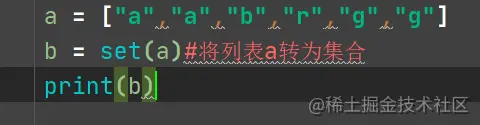
Use Python When programming , I often encounter the operation of reading and writing files . For various modes of reading and writing files ( Such as reading 、 write in 、 Supplemental ) Sometimes it's really confusing , And I don't know open、read、readline、readlines、write、writelines The use of such methods will also confuse you .
I hope this article can help you better understand how to read and write files , And use the most appropriate method in the most appropriate place .
Before we begin to study how to use Python Before files in , It is important to understand what files are and how modern operating systems handle some aspects of them .
essentially , A file is a contiguous set of bytes used to store data . The data is organized in a specific format , It can be any data as simple as a text file , It can also be as complex as a program executable . Last , These byte files are translated into binary files 1,0 So that the computer can handle it more easily .
Files on most modern file systems consist of three main parts :
1. title (Header): Metadata about file content ( file name , size , Type, etc )
2. data (Data): The content of a document written by the creator or editor
3. End of file (EOF): Special characters representing the end of the file 
The content of the data representation depends on the format specification used , Usually represented by an extension . for example , extension .gif Is most likely to conform to the Graphics Interchange Format Specification . There are hundreds of ( If not thousands ) File extension .
When accessing files on the operating system , File path required . The file path is a string representing the file location . It is divided into Three main parts :
(1) Folder path : Folder location on file system , Subsequent folders are composed of forward slashes /(Unix) Or backslash \(Windows) Separate
(2) file name : The actual name of the document
(3) Extension : A period is preset at the end of the file path (.), Used to represent the file type
Python File path related operations :
(1) Use getcwd() The current working directory is available , At present Python Directory path for script work , similar Linux in pwd command ,PS: If you want to print Windows Contains the Chinese file name or path , Need to use “GBK” Conduct decode
(2) Merge paths using path.join(),Windows The backslash in and Linux The forward slashes in use sep( Backslash requires the use of \ escape )
(3) Relative paths . Represents the current folder .. Represents the parent folder
(4) Relative paths 、 Absolute path conversion path.abspath(path): Return to absolute path path.isabs(path): Determine if it's an absolute path path.relpath(path,start): Return to relative path
(5) Path segmentation path.dirname(path): Returns the directory where the file is located ,os.path.basename(path): Return the filename path.split(path) : Divide paths by delimiters path.basename(): Get the file name path.splitext(): Detach extension path.getsize(filename): View file size , Only files can be counted , Different statistics folders , If you need to count folders, you need to traverse them by yourself .stat(file): Get file properties
(6) Path segmentation path.exists(): Does the path exist path.isdir(): Is it a directory path.isfile(): Is it a document
(6) Returns all files and directory names in the specified directory :listdir()
(7) Directory operation :copyfile('oldfile', 'newfile') Copy file ,oldfile and newfile It's just documents copy('oldfile', 'newfile') oldfile Only folders ,newfile It could be a file , It can also be the target directory copytree('olddir', 'newdir') Copy folder ,olddir and newdir It's just a catalog , And newdir Must not exist move('oldpos','newpos') Moving files ( Catalog )rmdir('dir') Only empty directories can be deleted rmtree('dir') Empty directory 、 Any directory with content can be deleted
(7) Other methods :os.remove(file) Delete file removedirs(r'c:\python ') Delete directory rename(old, new) rename makedirs(r'c:\python\test') Create multi-level directory mkdir('test') Create a single directory chmod(file) Modify file permissions and timestamps
One of the problems we often encounter when dealing with file data is the representation of new lines or the end of lines . The end of a line originated in the Morse code era , The use of a specific symbol is used to indicate the end of a transmission or the end of a line .
Windows Use CR+LF The character represents a new line , and Unix And the newer Mac Version only uses LF character . When you deal with files from different operating systems , This can lead to some complications . This is a simple example . Suppose we check on Windows System The files created on are as follows :
Pug\r\n
Jack Russel Terrier\r\n
English Springer Spaniel\r\n
German Shepherd\r\n
Staffordshire Bull Terrier\r\n
Cavalier King Charles Spaniel\r\n
Golden Retriever\r\n
West Highland White Terrier\r\n
Boxer\r\n
Border Terrier\r\n
The same output will be in Unix Explain in different ways on the device
Pug\r
\n
Jack Russel Terrier\r
\n
English Springer Spaniel\r
\n
German Shepherd\r
\n
Staffordshire Bull Terrier\r
\n
Cavalier King Charles Spaniel\r
\n
Golden Retriever\r
\n
West Highland White Terrier\r
\n
Boxer\r
\n
Border Terrier\r
\n
Solution :
with open('test.txt', 'r') as f:
for line in f.readlines():
line = line.strip('\n')
Use walk() The output always starts with the folder and ends with the file name
import os
# Traverse root_dir Download all folders and files What is returned is a list of triples , root,dir,file root directory , Folder list , File list
def echo_path(root_dir):
list_dirs = os.walk(root_dir)
for root, dirs, files in list_dirs:
for d in dirs:
print os.path.join(root, d)
for f in files:
print os.path.join(root, f)
Use listdir() Output according to the directory tree structure and alphabetical order .
import os
def echo_path(root_dir):
for dir_list in os.listdir(root_dir):
path = os.path.join(root_dir, dir_list)
print(path)
if os.path.isdir(path):
echo_path(path)
glob Module is one of the simplest modules , The content is very little . It can be used to find file pathnames that match specific rules .glob.glob() Returns all matching File path list . It has only one parameter pathname, The file path matching rules are defined , This can be an absolute path , It could be a relative path . Example :
import glob
# Get all pictures in the specified directory
print(glob.glob(r"E:\Picture\*\*.jpg") )
# Get all of the parent directory .py file
print(glob.glob(r'../*.py') # Relative paths )
glob.iglob() Get a traversable object , Use it to get the matching file pathnames one by one . And glob.glob() Is the difference between the :glob.glob Get all matching paths at the same time , and glob.iglob Get only one matching path at a time , namely generator .( The most obvious advantage of the generator is to save memory space , That is, it won't generate all the data at once , But when you need , When to generate .)
import glob
file = glob.iglob(r'../*.py')
print(file) #<generator object iglob at 0x00B9FF80>
for py in f:
print(py)
stay Python To read and write files in, you need 3 A step :
(1) call open function , Return to one File object
(2) call File Object's read() or write() Method
(3) call File Object's close() Method , Close the file
File common open mode :'r': read-only ( default . If the file doesn't exist , Throws an error )'w': Just write ( If the file doesn't exist , The file is created automatically )'a': Append to end of file 'r+': Reading and writing
If you need to open the file in binary mode , Need to be in mode Followed by the character ”b”, such as ”rb””wb” etc.
If not with sentence , The code is as follows :
file = open("/tmp/foo.txt")
data = file.read()
file.close()
Here are two questions :
(1) May forget to close the file handle ;
(2) File read data exception , There was no treatment .with Besides having more elegant grammar , It can also handle the exceptions generated by the context environment well .
with Version code :
with open("/tmp/foo.txt") as file:
data = file.read()
with workflow :
Following the with After the following statement is evaluated , Return object's enter() Method is called , The return value of this method will be assigned to as The latter variable .
When with After all the subsequent code blocks have been executed , Will call the... Of the previously returned object exit() Method .
Sometimes you may want to read a file and write to another file at the same time . If you use the example shown when learning how to write a file , It can actually be incorporated into the following :
d_path = 'dog_breeds.txt'
d_r_path = 'dog_breeds_reversed.txt'
with open(d_path, 'r') as reader, open(d_r_path, 'w') as writer:
dog_breeds = reader.readlines()
writer.writelines(reversed(dog_breeds))
read() Is the simplest way , Read all the contents of the file at once and put them in a large string , That is, it exists in memory .
f = open('test.txt')
try:
file_context = file_object.read()
file_context = open(file).read().splitlines() // file_context It's a list, Each line of text is list An element in
finally:
file_object.close()
read() The advantages of : convenient 、 Simple , The one-time read-out file is placed in a large string , The fastest
read() The shortcomings of : When the file is too large , It will take up too much memory
readline() Is to read the text line by line , The result is a list
with open(file) as f:
line = f.readline()
while line:
print(line)
readline() The advantages of : It takes up little memory , Read line by line
readline() The shortcomings of : Because it is read line by line , Relatively slow readlines() Read all the contents of the text at once , The result is a list
with open(file) as f:
for line in f.readlines():
print(line)
The text content read by this method , At the end of each line of text, there is a ’\n’ A newline ( have access to L.rstrip(‘\n’) Remove the newline )
readlines() The advantages of : Read text at once , It's quite fast
readlines() The shortcomings of : As the text grows , It will take up more and more memory
write() You pass in a string
lines = ['line1', 'line2']
with open('filename.txt', 'w') as f:
f.write('\n'.join(lines))
writelines() The number passed in is an array
lines = ['line1', 'line2']
with open('filename.txt', 'w') as f:
f.writelines("%s\n" % l for l in lines)