List keywords :list
# Type description of the list : Enclosed in brackets , Internal storage of multiple elements or data values , Data values are separated by commas , The data value can be any data type The expression keyword is list
# 1. Define a list first , Easy to understand
# l1 = [' Liu bei ', ' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ']
# l2 = [11, 22, 33, 44, 55, 66]
# 1. Count the number of data values in the list len
# print(len(l1))
# 2. The increase of the list
# 2.1 The tail element append() No matter what data type is written in brackets , Are added as a single data value
# l1.append(' Huang Zhong ')
# print(l1) # It should be noted that , The list will not generate new data values after calling the built-in method , Instead, it modifies itself [' Liu bei ', ' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ', ' Huang Zhong ']
# l1.append([1, 2, 3, 4, 5])
# print(l1) # [' Liu bei ', ' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ', ' Huang Zhong ', [1, 2, 3, 4, 5]]
# 2.2 Insert data values anywhere insert() No matter what data type is written in brackets , Are inserted as a single data value
# l1.insert(2, ' d ') # [' Liu bei ', ' Cao Cao ', ' d ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ']
# print(l1)
# 2.3 Extended list
# new_l1 = [77, 88, 99, 100]
# new_l2 = [1, 2, 3]
# Mode one
# for i in new_l1:
# new_l2.append(i)
# print(new_l2) # [1, 2, 3, 77, 88, 99, 100]
# Mode two
# print(new_l1 + new_l2) # [77, 88, 99, 100, 1, 2, 3]
# Mode three ( Recommended )
# new_l1.extend(new_l2)
# print(new_l1) # [77, 88, 99, 100, 1, 2, 3]
# 3. Query data and modify data
# Query data
# print(l1) # [' Liu bei ', ' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ']
# print(l1[3]) # Guan yu
# print(l1[1:5]) # [' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ']
# Modifying data
# l1[2] = ' zhaoyun '
# print(l1) # [' Liu bei ', ' Cao Cao ', ' zhaoyun ', ' Guan yu ', ' Zhang Fei ']
# 4, Delete data
# 4.1 General delete policy
# del l1[1] # Index 1 Delete the specified data
# print(l1) # [' Liu bei ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ']
# 4.2 Specify the data value to delete Clear data values must be filled in brackets
# l1.remove(' Zhang Fei ')
# print(l1) # [' Liu bei ', ' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ']
# 4.3 Take out the data value first , Then delete
# res = l1.pop() # Get the last data value in the list first , And then delete it
# print(l1, res) # [' Liu bei ', ' Cao Cao ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu '] Zhang Fei
# res = l1.pop(1)
# print(res, l1) # Cao Cao [' Liu bei ', ' king of Wu in the Three Kingdoms Era ', ' Guan yu ', ' Zhang Fei ']
# 5. View the index value corresponding to the data value
# print(l1.index(' Zhang Fei ')) # 4
# 6. Count the number of occurrences of a data value
# l1.append(' Liu bei ')
# print(l1.count(' Liu bei '))
# 7. Sort
# l2.sort()
# print(l2) # [11, 22, 33, 44, 55, 66] Ascending
# l2.sort(reverse=True)
# print(l2) # [66, 55, 44, 33, 22, 11] Descending
# 8. reverse
# l1.reverse()
# print(l1) # [' Zhang Fei ', ' Guan yu ', ' king of Wu in the Three Kingdoms Era ', ' Cao Cao ', ' Liu bei '] Reverse the order
# 9. Comparison operations
# new_1 = [88, 66]
# new_2 = [33, 44, 55, 66]
# print(new_1 > new_2) # True When comparing the sizes of lists, they are compared one by one according to the position order
# new_1 = ['a', 66]
# new_2 = [33, 44, 55, 66]
# print(new_1 > new_2) # Different data types cannot be operated directly by default
# new_1 = ['a', 66]
# new_2 = ['A', 44, 55, 66]
# print(new_1 > new_2) # True
Dictionary keywords dict
# Type description of the dictionary : Enclosed in braces , Multiple data values can be stored internally , Data values are separated by commas , The organizational form is K:V Key value pair
# Type conversion
# print(dict([('name', 'zh'), ('pwd', 123)])) # {'name': 'zh', 'pwd': 123}
# print(dict(name='huawei', pwd=666)) # {'name': 'huawei', 'pwd': 666}
""" Dictionary rarely involves type conversions Are directly defined and used """
info = {
'username': 'lisa',
'password': 666,
'hobby': ['read', 'run']
}
"""
k It's right v The descriptive nature of the information , It's usually a string , It can also be an immutable type , Like integer 、 floating-point 、 character string 、 Tuples
"""
# 1. In dictionary K:V Key value pairs are unordered , Cannot take value with index
# 2. Value operation
# print(info['username']) # It is not recommended to use , If the key doesn't exist , An error message will be printed
# print(info.get('username')) # lisa
# print(info.get('name')) # None
# print(info.get('username', ' The key does not have a returned value , The default is None')) # lisa
# print(info.get('xxx', ' The key does not have a returned value , The default is None')) # The key does not have a returned value , The default is None
# 3. A dictionary of key pairs in the
# print(len(info)) # 3
# 4. Modifying data
# info['username'] = 'name' If the key exists, it is modified
# print(info) # {'username': 'name', 'password': 666, 'hobby': ['read', 'run']}
# 5. The new data
# info['salary'] = 600 If the key does not exist, it is added
# print(info) # {'username': 'lisa', 'password': 666, 'hobby': ['read', 'run'], 'salary': 600}
# 6. Delete data
# Mode one
# del info['username']
# print(info) # {'password': 666, 'hobby': ['read', 'run']}
# Mode two
# res = info.pop('username')
# print(info, res) # {'password': 666, 'hobby': ['read', 'run']} lisa
# Mode three
# info.popitem() # Random delete
# print(info)
# 7. Quick access key 、 value 、 Key value pair data
# print(info.keys()) # dict_keys(['username', 'password', 'hobby']) Get all the dictionary's K value , The results can be treated as a list
# print(info.values()) # dict_values(['lisa', 666, ['read', 'run']]) Get all the dictionary's V value , The results can be treated as a list
# print(info.items()) # dict_items([('username', 'lisa'), ('password', 666), ('hobby', ['read', 'run'])]) Take the dictionary KV Key value pair data , Organize into list tuples
# 8. Quickly construct a dictionary The given value defaults to , All keys use one
# res = dict.fromkeys([1, 2, 3, 4, 5], {})
# print(res) # {1: {}, 2: {}, 3: {}, 4: {}, 5: {}}
Tuple keyword tuple
# Type description of tuples : Enclosed in brackets , Store multiple data values internally , Data values are separated by commas , The data value can be any data type , Also known as immutable lists
# Type conversion Support for The data type of the loop can be converted
# print(tuple(123))
# print(tuple(1.2))
# print(tuple('huawei')) # ('h', 'u', 'a', 'w', 'e', 'i')
# print(tuple([1, 2, 3, 4, 5])) # (1, 2, 3, 4, 5)
# print(tuple({'name': 'lib', 'age': 18})) # ('name', 'age')
# Define a tuple first
# t1 = ()
# print(type(t1)) # <class 'tuple'>
# t2 = (1)
# print(type(t2)) # <class 'int'>
# t3 = (22.22)
# print(type(t3)) # <class 'float'>
# t4 = 'name'
# print(type(t4)) # <class 'str'>
# When there is only one data value in a tuple , Commas cannot be omitted , If you omit , The data type in brackets is the data type
# When writing tuples , Add the comma , Even if there is only one data
# t1 = ()
# print(type(t1)) # <class 'tuple'>
# t2 = (1,)
# print(type(t2)) # <class 'tuple'>
# t3 = (22.22,)
# print(type(t3)) # <class 'tuple'>
# t4 = ('name',)
# print(type(t4)) # <class 'tuple'>
# In the future, you will encounter data types that can store multiple data values , If there is only one data value , Then take the opportunity to add the comma , Can be more standardized
# t1 = (11, 22, 33, 44, 55, 66, 77, 88)
# 1. Index related operations
# 2. Count the number of data values in the tuple
# print(len(t1)) # 8
# 3. Check and correct
# print(t1[0]) # Can find
# t1[0] = 333 # Cannot be modified
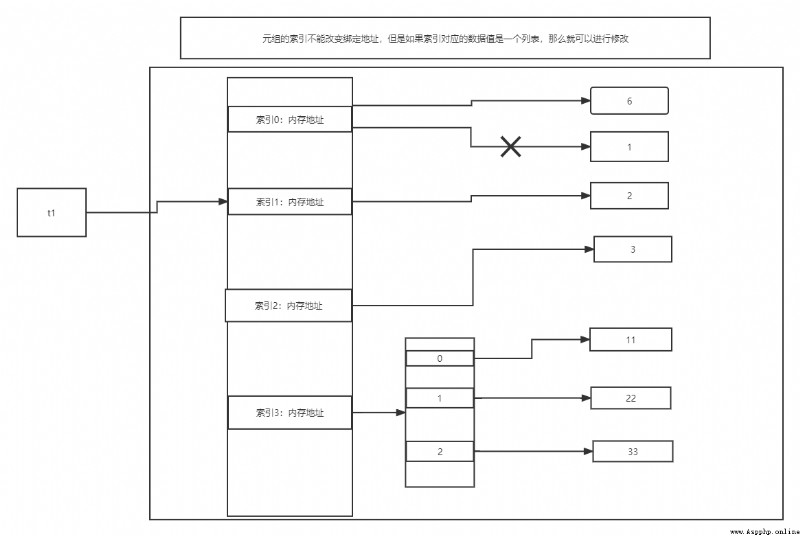
# Be careful : The index of tuples cannot change the binding address
# t2 = (11, 22, 33, 44, [1, 2])
# t2[-1].append(3)
# print(t2) # (11, 22, 33, 44, [1, 2, 3])
Express key words set
# To define an empty collection, you need to use keywords
# Type conversion : It can be for The data type of a loop can be converted to a set , But the converted data value can only be an immutable data type
# The data type in the collection must be immutable ( integer 、 floating-point 、 character string 、 Tuples 、 Boolean value )
# The collection has its own de duplication feature
# l1 = ['red', 'blue', 'black', 'green', 'red', 'red', 'red'] # Automatically remove duplicate elements from the list
# s1 = set(l1)
# print(s1) # {'red', 'black', 'blue', 'green'}
# l1 =list(s1)
# print(l1) # ['red', 'black', 'blue', 'green']
# Relationship between operation
# Simulate two people's friend collection
# a1 = {' Song Jiang ', ' Wu Yong ', ' Jun-yi lu ', ' Chaogai ', ' Wusong ', ' Li Kui '}
# a2 = {' Liu bei ', ' Guan yu ', ' Li Kui ', ' Cao Cao ', ' Zhou Yu ', ' d '}
# 1. seek a1 and a2 Our mutual friends
# print(a1 & a2) # {' Li Kui '}
# 2. seek a1 and a2 Unique friends
# print(a1 - a2) # {' Jun-yi lu ', ' Chaogai ', ' Song Jiang ', ' Wu Yong ', ' Wusong '}
# print(a2 - a1) # {' Liu bei ', ' d ', ' Guan yu ', ' Zhou Yu ', ' Cao Cao '}
# 3. seek a1 and a2 All friends
# print(a1 | a2) # {' Wu Yong ', ' Song Jiang ', ' d ', ' Li Kui ', ' Cao Cao ', ' Jun-yi lu ', ' Liu bei ', ' Chaogai ', ' Wusong ', ' Guan yu ', ' Zhou Yu '}
# 4. seek a1 and a2 Their own unique friends , Exclude common friends
# print(a1 ^ a2) # {' Wusong ', ' Song Jiang ', ' Jun-yi lu ', ' Wu Yong ', ' Guan yu ', ' Zhou Yu ', ' Chaogai ', ' Liu bei ', ' Cao Cao ', ' d '}
# 5. Superset 、 A subset of
# s1 = {1, 2, 3, 4, 5, 6, 7}
# s2 = {3, 2, 1}
# print(s1 > s2) # True Judge s1 Is it right? s2 A set of parent ,s2 Is it right? s1 Subset
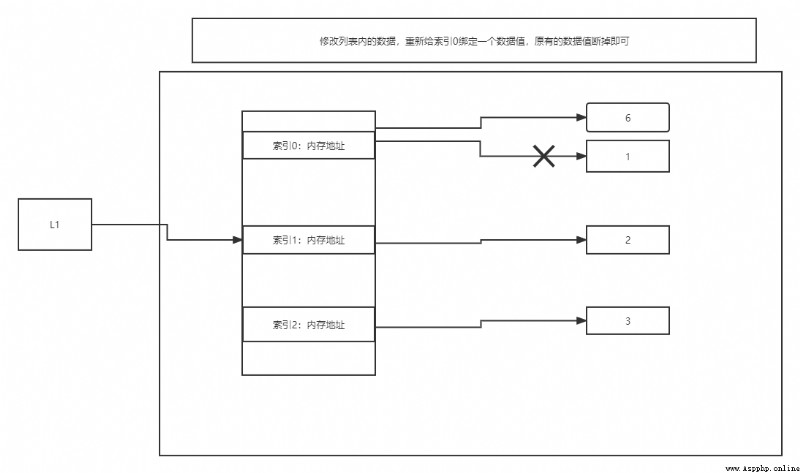
"""
Why do string calls to built-in methods generate new values The list calls built-in methods to change itself
"""
1. Variable type list
Value change ( Through built-in methods ) The memory address can remain unchanged
l1 = [11, 22, 33]
print(id(l1)) # 1931283911552
l1.append(44) # [11, 22, 33, 44]
print(id(l1)) # 1931283911552
2. Immutable type str int float
Value change ( Through built-in methods ) The memory address must have changed
s1 = '$hello$'
print(id(s1))
s1 = s1.strip('$')
print(id(s1))
# 1. Use the list to write an employee name management system
# Input 1 Execute the function of adding user name
# Input 2 Perform the view all user names function
# Input 3 Execute the function of deleting the specified user name
# ps: Think about how to make the program loop and perform different operations according to different instructions
# Tips : Loop structure + Branching structure
# Elevation : Whether it can be replaced by dictionary or nested use of data to complete more perfect employee management rather than a simple user name ( Write as you can
# No, it doesn't matter )
"""
Main function :[ Add users 、 To view the user 、 Delete user ]
"""
# 1. First define a list to store user name data
user_data_list = []
# 2. Circular printing management system function , And provide the function number
while True:
print("""
1. Add user name
2. View all user names
3. Delete the specified user name
""")
# 3. Get the function number that the user needs to perform
select = input(' Please enter the function number to be performed >>>:').strip()
# 4. Determine the function the user wants to perform
if select == '1':
# 5. Get the user name
username = input(' Please enter the user name you want to add >>>:').strip()
# 6. Determine whether the user name already exists , If it exists, the user will be prompted that it already exists and the judgment will be ended
if username in user_data_list:
print(' I'm sorry , This user name already exists , Unable to add ')
break
# 7. Create a temporary list to store user names
user_list = f'{username}'
# 8. Add to data list
user_data_list.append(user_list)
# 9. Prompt the user to add successfully
print(f'{username} Add success ')
elif select == '2':
print(user_data_list)
elif select == '3':
# 10. Get the user name you want to delete
delete_user = input(' Please enter the user name you want to delete >>>:')
# 11. Determine whether the current user name still exists
if delete_user not in user_data_list:
print(' This user name does not exist , Cannot delete ')
continue # If there is , Then end this cycle
# 12. Use the list built-in method to delete data
res = user_data_list.pop(1).strip()
print(' This user name has been deleted ')
else:
print(' Please enter the correct function number ')
# 2. Remove the following list and keep the original order of data values
# eg: [1, 2, 3, 2, 1] After de duplication [1, 2, 3]
# l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
# l1 = [2, 3, 2, 1, 2, 3, 2, 3, 4, 3, 4, 3, 2, 3, 5, 6, 5]
# l2 = set(l1)
# l1 = list(l2)
# print(l1) # [1, 2, 3, 4, 5, 6]
# 3. There are two sets ,pythons It's registration python A collection of student names for the course ,linuxs It's registration linux A collection of student names for the course
# pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
# linuxs = {'kermit', 'tony', 'gangdan'}
# 1. Find out and sign up python Sign up again linux A collection of student names for the course
# 2. Find out the name set of all registered students
# 3. Only sign up python The names of the participants in the course
# 4. Find out the students' name set without the two courses at the same time
# pythons = {'jason', 'oscar', 'kevin', 'ricky', 'gangdan', 'biubiu'}
# linuxs = {'kermit', 'tony', 'gangdan'}
#
# print(pythons & linuxs) # {'gangdan'}
# print(pythons | linuxs) # {'tony', 'biubiu', 'gangdan', 'oscar', 'kevin', 'kermit', 'ricky', 'jason'}
# print(pythons - linuxs) # {'jason', 'ricky', 'biubiu', 'oscar', 'kevin'}
# print(pythons ^ linuxs) # {'jason', 'kermit', 'oscar', 'kevin', 'ricky', 'biubiu', 'tony'}
 [Python app automation test practice part ④] - drive the night God simulator through appoum to complete the first automation script - view the address book
[Python app automation test practice part ④] - drive the night God simulator through appoum to complete the first automation script - view the address book
Wanyeji Faint thunder , Cloud