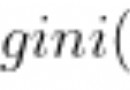
from askWeb.index import AskUrl
import datetime
# Crawl the website URL
from database import database
from utils import utils
import asyncio,aiohttp
# Grab the website
#urlName The websites
#url Website path
#requestType Request type
# Website type
async def getUrlContent(urlName, url, requestType="get", webType=1):
# Starting time
startTime = datetime.datetime.now()
print(" Grab " + urlName + " Start timing ...........")
await AskUrl(url).handleGetYourContent(requestType, webType)
# End time
endTime = datetime.datetime.now()
lastTime = str((endTime - startTime).seconds)
print(" Grab "+urlName+" Total use time :" + lastTime)
# The initial path of today's hot list
# "https://tophub.today"
if __name__ == "__main__":
startTime = datetime.datetime.now()
urlArr = [
{
"urlName": "b Station hot list ",
"url": "https://www.bilibili.com/v/popular/rank/all",
"requestType": "get",
"type": 1,
},
{
"urlName": " Microblog hot list ",
"url": "https://tophub.today/n/KqndgxeLl9",
"requestType": "get",
"type": 6,
},
{
"urlName": " Wechat hot list ",
"url": "https://tophub.today/n/WnBe01o371",
"requestType": "get",
"type": 5,
},
{
"urlName": " Tiktok video ",
"url": "https://tophub.today/n/WnBe01o371",
"requestType": "get",
"type": 4,
},
{
"urlName": "CSDN Comprehensive hot list ",
"url": "https://blog.csdn.net/phoenix/web/blog/hot-rank",
"requestType": "get",
"type": 3,
},
{
"urlName": "IT Information hot list ",
"url": "https://it.ithome.com/",
"requestType": "get",
"type": 2,
},
]
# Task list
task_list = []
# enumerate Function combines a traversable data object into an index sequence
for key, value in enumerate(urlArr):
future = asyncio.ensure_future(getUrlContent(value["urlName"], value["url"], value["requestType"], value["type"]))
task_list.append(future)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(task_list))
# Need to sign out loop.close Because the mission was closed while it was still executing , So I just log out loop.close. If you have a better way , You can leave a message in the comment area
# loop.close()
# End time
endTime = datetime.datetime.now()
# Time of use
lastTime = str((endTime - startTime).seconds)
print(" Total use time :" + lastTime)
To upload the database, you need to cancel the comment , And change it to the field of your own database
import ssl
import time
from urllib.error import HTTPError
import aiohttp
from bs4 import BeautifulSoup # Web page parsing get data
import requests
import urllib3
from urllib import request
from http import cookiejar
from utils import utils
import database.database
import random
import json
urllib3.disable_warnings()
ssl._create_default_https_context = ssl._create_unverified_context
# Visit the website class
class AskUrl():
## Class initialization
def __init__(self, url):
self.dealSql = database.database.ConnectSql()
self.url = url
# Get random userAgent
def handleRandomUserAgent(self):
allUserAgent = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:70.0) Gecko/20100101 Firefox/70.0",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.63 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.67 Safari/537.36 OPR/87.0.4390.45 (Edition Campaign 34)",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.42 Safari/537.36 Edg/103.0.1264.21"
,
]
return allUserAgent[random.randint(0, 3)]
# Get website cookie
def getWebCookie(self):
# Make a statement cookiejar Object instance save cookie
cookie = cookiejar.CookieJar()
# utilize urllib Medium request In the database HTTPCookieProcessor Method creation cookie processor
handler = request.HTTPCookieProcessor(cookie)
# adopt cookieHandler establish opener
opener = request.build_opener(handler)
print(self.url)
# Open the web page
try:
opener.open(self.url)
except HTTPError as e:
print(" Capture websites cookie Error message :%s" % e)
return ""
cookieStr = ""
for item in cookie:
cookieStr = cookieStr + item.name + "=" + item.value + ";"
return cookieStr[:-1]
# Asynchronous coroutine
# Visit website
async def visitWeb(self, method, param="", header="", session=""):
# Turn off request warning
requests.packages.urllib3.disable_warnings()
proxies = {
"http": None,
"https": None,
}
if header == "":
cookie = self.getWebCookie()
# print(cookie,"cookiecookiecookie")
header = {
"Cache-Control": "no-cache",
"Cookie": cookie,
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,"
"application/signed-exchange;v=b3;q=0.9",
'User-Agent': self.handleRandomUserAgent(),
}
if method == 'get':
async with await session.get(self.url, data=param and param or {
}, headers=header) as resp:
page_text = await resp.content.read(999999999999999)
else:
async with await session.post(self.url, data=param and param or "", headers=header) as resp:
page_text = await resp.content.read(999999999999999)
# Encoding format conversion , Prevent Chinese miscoding
page_text.decode("utf-8", "ignore")
# Instantiation beautifulSoup object , You need to load the page source code data into the object
soup = BeautifulSoup(page_text, 'html.parser')
# print(soup)
return soup
# Grab header information and title
def handleGetWebTitleAndLogo(self):
# 1. Instantiation beautifulSoup object , You need to load the page source code data into the object
soup = self.visitWeb("get")
try:
webTitle = soup.select("title") # Website title
webTitle = webTitle and webTitle[0].text or ""
except HTTPError as e:
webTitle = ""
print(" Website Title error message :%s" % e)
try:
webLogo = soup.select("link[type='image/x-icon']") # Website logo
webLogo = webLogo and webLogo[0].get("href") or ""
except HTTPError as e:
webLogo = ""
print(" Website logo Error message :%s" % e)
try:
webDescription = soup.select("meta[name='description']") # Website description
webDescription = webDescription and webDescription[0].get("content") or ""
except HTTPError as e:
webDescription = ""
print(" Website description error message :%s" % e)
try:
webKeywords = soup.select("meta[name='keywords']") # Website keywords
webKeywords = webKeywords and (
webKeywords[0].get("content") is None and "" or webKeywords[0].get("content")) or ""
except HTTPError as e:
webKeywords = ""
print(" Website keyword error information :%s" % e)
return {
"webTitle": webTitle, "webLogo": webLogo, "webDescription": webDescription, "webKeywords": webKeywords}
# Get the data you want Filter website content
# type Crawl site types
async def handleGetYourContent(self, requestType="get", type=1, params=""):
""" aiohttp: send out http request 1. Create a love you ClientSession object 2. adopt ClientSession Sent by the other party get,post,put Login request 3.await Wait asynchronously for the result to return ( Program pending ) """
async with aiohttp.ClientSession() as session:
# 1. Instantiation beautifulSoup object , You need to load the page source code data into the object
soup = await self.visitWeb(requestType, params, session=session)
if type == 1:
await self.handleGrabBliWeb(soup)
elif type == 2:
await self.handleItHomeWeb(soup)
elif type == 3:
await self.handleGetCsdnWeb(soup)
elif type == 4:
await self.handleGetDyVideoWeb(soup)
elif type == 5:
await self.handleGetWeChatWeb(soup)
elif type == 6:
await self.handleGetWeiBoWeb(soup)
print(' Operation is completed ')
# Microblogging Trending
async def handleGetWeiBoWeb(self, soup, num=1, page=0):
# 2. Get the data in the list through the tag
li_list = soup.select(".table")[0].select("tbody>tr")
# Loop through list data
for item in li_list:
href = item.select(".al a")[0].get("href") # Access path
title = item.select(".al a")[0].text # title
hotData = item.select("td")[2].text
# res = self.dealSql.handleInsert(table="g_hot_list", title=title, url=href, hot_num=hotData, type=5,
# add_time=utils.FormatDate(), update_time=utils.FormatDate())
res = True
if res:
data = " The first %s Bar inserted successfully : title : %s Traffic volume : %s Access path :%s" % (num, title, hotData, href)
print(data)
else:
data = " The first %s Bar insertion failed "
print(data)
# time.sleep(1)
num += 1
# Wechat hot list
async def handleGetWeChatWeb(self, soup, num=1):
# 2. Get the data in the list through the tag
li_list = soup.select(".table")[0].select("tbody>tr")
# Loop through list data
for item in li_list:
href = item.select(".al a")[0].get("href") # Access path
title = item.select(".al a")[0].text # title
hotData = item.select("td")[2].text
hotData = hotData.split(" ")[0] # degree of heat
# res = self.dealSql.handleInsert(table="g_hot_list", title=title, url=href, hot_num=hotData, type=5,
# add_time=utils.FormatDate(), update_time=utils.FormatDate())
res = True
if res:
data = " The first %s Bar inserted successfully : title : %s Traffic volume : %s Access path :%s" % (num, title, hotData, href)
print(data)
else:
data = " The first %s Bar insertion failed "
print(data)
# time.sleep(1)
num += 1
# Tiktok short video hot list
async def handleGetDyVideoWeb(self, soup, num=1):
# 2. Get the data in the list through the tag
li_list = soup.select(".table")[0].select("tbody>tr")
# Loop through list data
for item in li_list:
href = item.select(".al a")[0].get("href") # Access path
title = item.select(".al a")[0].text # title
hotData = item.select("td")[2].text # degree of heat
# res = self.dealSql.handleInsert(table="g_hot_list", title=title, url=href, hot_num=hotData, type=4,
# add_time=utils.FormatDate(), update_time=utils.FormatDate())
res = True
if res:
data = " The first %s Bar inserted successfully : title : %s Traffic volume : %s Access path :%s" % (num, title, hotData, href)
print(data)
else:
data = " The first %s Bar insertion failed "
print(data)
# time.sleep(1)
num += 1
# csdn Articles are hot
async def handleGetCsdnWeb(self, soup, num=1, page=0):
# 2. adopt API Get the data in the list
# String to array
li_list = json.loads(str(soup),strict=False)["data"]
# Loop through list data
for item in li_list:
href = item["articleDetailUrl"] # Access path
title = item["articleTitle"] # Access title
hotData = item["hotRankScore"] # degree of heat
# res = self.dealSql.handleInsert(table="g_hot_list", title=title, url=href, hot_num=hotData, type=3,
# add_time=utils.FormatDate(), update_time=utils.FormatDate())
res = True
if res:
data = " The first %s Bar inserted successfully : title : %s Heat quantity :%s Access path :%s" % (num, title, hotData, href)
print(data)
else:
data = " The first %s Bar insertion failed "
print(data)
# time.sleep(1)
num += 1
if page < 4:
curPage = page + 1
async with aiohttp.ClientSession() as session:
soup = await self.visitWeb("get", {
"page": curPage, "pageSize": 25, "type": ""}, session=session)
return await self.handleGetCsdnWeb(soup, num, curPage)
# b Station hot list
async def handleGrabBliWeb(self, soup, num=1):
# 2. Get the data in the list through the tag
li_list = soup.select(".rank-list-wrap>ul>li")
# Loop through list data
for item in li_list:
href = item.select(".info a")[0].get("href") # Access path
title = item.select(".info a")[0].text # title
# "".join() Remove the space
hotData = "".join(item.select(".info .detail-state .data-box")[0].text.split()) # Play volume
if href.find("//", 0) >= 0:
href = href.split("//")[1]
# res = self.dealSql.handleInsert(table="g_hot_list", title=title, url=href, hot_num=hotData, type=1,
# add_time=utils.FormatDate(), update_time=utils.FormatDate())
res = True
if res:
data = " The first %s Bar inserted successfully : title : %s Traffic volume : %s Access path :%s" % (num, title, hotData, href)
print(data)
else:
data = " The first %s Bar insertion failed "
print(data)
# time.sleep(1)
num += 1
# it Home hot list
async def handleItHomeWeb(self, soup, num=1, nexPage=1):
# first page
if nexPage == 1:
# 2. Get the data in the list through the tag
li_list = soup.select(".fl>ul>li")
# After the second page
else:
li_list = soup.select("li")
# Loop through list data
for item in li_list:
href = item.select("a[class='img']")[0].get("href") # Access path
title = item.select("a[class='img']")[0].select("img")[0].get("alt") # title
# res = self.dealSql.handleInsert(table="g_hot_list", title=title, url=href, type=2,
# add_time=utils.FormatDate(), update_time=utils.FormatDate())
res = True
if res:
data = " The first %s Bar inserted successfully : title : %s Access path :%s" % (num, title, href)
print(data)
else:
data = " The first %s Bar insertion failed "
print(data)
# print(data)
# time.sleep(1)
num += 1
if nexPage == 1:
nexPageUrl = "https://it.ithome.com/category/domainpage"
header = {
"Cache-Control": "no-cache",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9"}
param = {
"domain": "it", "subdomain": "", "ot": int(time.time()) * 1000}
async with aiohttp.ClientSession() as session:
resData = await AskUrl(nexPageUrl).visitWeb("post", param=param, header=header, session=session)
# Convert when getting data json Data needs to be set strict=False, Otherwise, the report will be wrong
soup = BeautifulSoup(json.loads(str(resData),strict=False)["content"]["html"], 'html.parser')
return await self.handleItHomeWeb(soup, num, nexPage + 1)
import time
## Time shift
def FormatDate(timeNow="",fmt="%Y-%m-%d %H:%M:%S"):
if timeNow=="":
# Get the current time
timeNow = int(time.time())
# convert to localtime
time_local = time.localtime(timeNow)
# Convert to a new time format (2016-05-09 18:59:20)
dt = time.strftime(fmt, time_local)
return dt
# 2022-1-1 Turn to time stamp
def time_to_str(val):
return int(time.mktime(time.strptime(val, "%Y-%m-%d")))
# Current timestamp
def cur_time_to_str():
return int(time.mktime(time.localtime(time.time())))
You need to fill in your own ip,mysql account number , password
# Linked database class
class ConnectSql():
# Member attribute
# link myql Of ip Address
__host = "xxxx"
# link mysql Account number
__user = "xxxx"
# link mysql Password
__passwd = "xxxxx"
# mysql Port number
__port = 3306
# Database name
__db = "xxxx"
# Character encoding
__charset = "utf8"
cur = ""
# Constructors // Class initialization information
def __init__(self):
try:
# Connect to database
self.conn = pymysql.connect(host=self.__host,user=self.__user, password=self.__passwd,port=self.__port,database=self.__db,charset= self.__charset)
self.cur = self.conn.cursor() # Generate cursor object
except pymysql.Error as e:
print(" link error :%s" % e)
# Destroy object , Free up space memory
def __del__(self):
print(" destroy ")
# Close the database
def closedatabase(self):
# If the data is open , Then close ; Otherwise, there is no operation
if self.conn and self.cur:
self.cur.close()
self.conn.close()
return True
# perform execute Method , Returns the number of rows affected
def handleExcute(self, sql):
try:
self.cur.execute(sql) # Execute inserted sql sentence
self.conn.commit() # Commit to database execution
count = self.cur.rowcount
if count > 0:
return True
else:
return False
except TypeError:
print(" Wrong content :", TypeError)
# perform mysql Failure , Transaction rollback
self.conn.rollback()
self.closedatabase()
return False
# perform sql sentence
# Execute source generation sql sentence
def dealMysql(self, dataSql):
self.handleExcute(dataSql)
# insert data
def handleInsert(self, **params):
table = "table" in params and params["table"] or ""
sql = "INSERT INTO %s(" % table
del params["table"]
fields = ""
values = ""
for k, v in params.items():
fields += "%s," % k
# Judge data type , Insert the corresponding data
if type(v) == type("test"):
values += "'%s'," % v
elif type(v) == type(1):
values += "%s," % v
fields = fields.rstrip(',')
values = values.rstrip(',')
sql = sql + fields + ")values(" + values + ")"
print(sql, "handleUpdate")
return self.handleExcute(sql)
# Delete data
def handleDel(self, **params):
table = "table" in params and params["table"] or ""
where = "where" in params and params["where"] or ""
sql = "DELETE FROM %s WHERE %s " % (table, where)
print(sql, "handleUpdate")
return self.handleExcute(sql)
# Edit the data
def handleUpdate(self, **params):
table = "table" in params and params["table"] or ""
where = "where" in params and params["where"] or ""
params.pop("table")
params.pop("where")
sql = "UPDATE %s SET " % table
for k, v in params.items():
# Judge data type , Insert the corresponding data
if type(v) == type("test"):
sql += "%s='%s'" % (k, v)
elif type(v) == type(1):
sql += "%s=%s" % (k, v)
sql += "WHERE %s" % where
print(sql, "handleUpdate")
return self.handleExcute(sql)
# Query multiple data
def handleFindAllData(self, **params):
# table fields where order limit
table = "table" in params and params["table"] or ""
where = "where" in params and "WHERE " + params["where"] or ""
field = "field" in params and params["field"] or "*"
order = "order" in params and "ORDER BY " + params["order"] or ""
sql = "SELECT %s FROM %s %s %s %s" % (field, table, where, order)
print(sql, "handleFindAllData")
return self.handleExcute(sql)
# Query single data
def handleFindOneData(self, **params):
# table fields where order limit
table = "table" in params and params["table"] or ""
where = "where" in params and "WHERE " + params["where"] or ""
field = "field" in params and params["field"] or "*"
order = "order" in params and "ORDER BY " + params["order"] or ""
sql = "SELECT %s FROM %s %s %s %s LIMIT 1" % (field, table, where, order)
print(sql,"handleFindOneData")
return self.handleExcute(sql)
Project source download address :https://download.csdn.net/download/qq_36977923/85762109?spm=1001.2014.3001.5501
Step on pit No easy , also Greek at various position Big Guy the a One Next \textcolor{gray}{ It's not easy to step on the pit , I also hope you guys can support } Step on pit No easy , also Greek at various position Big Guy the a One Next
individual people Lord page : \textcolor{green}{ Personal home page :} individual people Lord page : Silent tubule
individual people network standing : \textcolor{green}{ Personal website :} individual people network standing : Silent tubule
Technology Technique hand over flow Q Q Group : 837051545 \textcolor{green}{ Technical communication QQ Group :837051545} Technology Technique hand over flow QQ Group :837051545
spot Fabulous , you Of recognize can yes I gen do Of dynamic force ! \textcolor{green}{ give the thumbs-up , Your recognition is the driving force of my creation !} spot Fabulous , you Of recognize can yes I gen do Of dynamic force !
️ closed hidden , you Of green look at yes I No force Of Fang towards ! \textcolor{green}{ Collection , Your favor is the direction of my efforts !} closed hidden , you Of green look at yes I No force Of Fang towards !
️ review On , you Of It means see yes I Into the Step Of goods rich ! \textcolor{green}{ Comment on , Your opinion is the wealth of my progress !} review On , you Of It means see yes I Into the Step Of goods rich !
If you don't understand, you can leave a message , I should see a reply
If there is a mistake , Your advice are most welcome