學會使用redis,使用python代碼又非常簡潔。劃重點:原來這貨就這點知識。並不難。
原文教程太冗余了:詳細教程
java版教程:JAVA教程
win7安裝redis需要首先下載客戶端:提取碼1234
然後解壓,運行文件夾中的以下服務端和客戶端:
然後在python終端或者anaconda終端,輸入:pip install redis安裝redis。
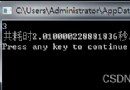
當服務端出現以下界面,說明服務端已經啟動了。端口號為6379.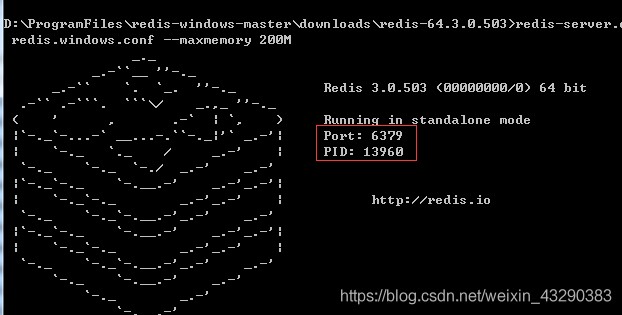
1、 搭建 好 開發環境,就可以掌握以下知識就夠了。
import redis # 導入redis 模塊
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
r.set('name', 'runoob') # 設置 name 對應的值
print(r.get('name')) # 取出鍵 name 對應的值
print(pool)
redis最常用的set和get方法已經如上圖了。
掌握常用命令即可,不常用的用的時候再查。
1.set(key, value),就是給name賦值為value。
r.set('name', 'runoob') # 設置 name 對應的值
2.setnx(key, value)
設置值,只有name不存在時,執行設置操作。
print(r.setnx('fruit1', 'banana')) # fruit1不存在,輸出為True
3.一次性設置多個值mset,一次性獲取多個值mget。
r.mset({
'k1': 'v1', 'k2': 'v2'})
print(r.mget("k1", "k2")) # 一次取出多個鍵對應的值
print(r.mget("k1"))
4、獲取指定序列字符串getrange(key, start, end),注意包含start和end,和python中的range函數不一樣。
r.set("en_name","luoji") # 字母
print(r.getrange("en_name", 0, 2)) # 取索引號是0-2 前3位的字節luo 切片操作
print(r.getrange("en_name", 0, -1)) # 取所有的字節 luoji 切片操作
5.計數函數(增加函數)
增加incr(self, name, amount=1)
同incrbyfloat(self, name, amount=1.0)。
減少decr(self, name, amount=1)。
假定我們對統計網頁點擊次數。如果使用關系數據庫來存儲點擊,可能存在大量的行級鎖爭用。所以,點擊數的增加使用redis的INCR命令最好不過了。
r.set("visit:12306:totals", 34634)
r.incr("visit:12306:totals")
r.incr("visit:12306:totals")
print(r.get("visit:12306:totals"))
輸出34636
6、append(key, value)
在redis name對應的值後面追加內容。
r.set("name","luoji") # 字母
r.append("name", "shuaige") # 在name對應的值luoji後面追加字符串shuaige
print(r.get("name"))
輸出:luojishuaige
1.hset(name, key,value),就是給name賦值為value。
hget(name,key)
r.hset("hash1", "k1", "v1")
r.hset("hash1", "k2", "v2")
print(r.hkeys("hash1")) # 取hash中所有的key
print(r.hget("hash1", "k1")) # 單個取hash的key對應的值
print(r.hmget("hash1", "k1", "k2")) # 多個取hash的key對應的值
2、hgetall(name)
獲取name對應hash的所有鍵值
print(r.hgetall("hash1"))
3、hlen(name)
獲取name對應的hash中鍵值對的個數.
4、hkeys(name)
獲取name對應的hash中所有的key的值
5、hvals(name)
獲取name對應的hash中所有的value的值
6、hexists(name, key)
檢查name對應的hash是否存在當前傳入的key
print(r.hlen("hash1"))
print(r.hkeys("hash1"))
print(r.hvals("hash1"))
print(r.hexists("hash1", "k4")) # False 不存在
7、hdel(name,*keys)
將name對應的hash中指定key的鍵值對刪除
r.hdel("hash1", "k1") # 刪除一個鍵值對
print(r.hgetall("hash1"))
8、hincrby(name, key, amount=1)
自增name對應的hash中的指定key的值,不存在則創建key=amount
r.hincrby("hash1", "k4", amount=1) # 不存在的話,value默認就是1
print(r.hgetall("hash1"))
9、hscan_iter(name, match=None, count=None)
利用實現分批去redis中獲取數據
參數:
match,匹配指定key,默認None 表示所有的key
for item in r.hscan_iter('hash1'):
print(item)
1.lpush(listname,values)
在listname中添加最左邊添加元素。
對應有rpush(listname,values)
在listname中添加最右邊添加元素。
r.lpush("list1", 11, 22, 33)
print(r.lrange('list1', 0, -1)) # 輸出33,22,11
r.rpush("list2", 111, 212, 313) # 表示從右向左操作
print(r.llen("list2")) # 列表長度
print(r.lrange("list2", 0, 3)) # 切片取出值,范圍是索引號0-3輸出111, 212, 313
2、r.lset(name, index, value)
對name對應的list中的某一個索引位置重新賦值
3、刪除(指定值進行刪除)
r.lrem(name, value, num)
在name對應的list中刪除指定的值
參數:
name,redis的name
value,要刪除的值
num, num=0,刪除列表中所有的指定值;
r.lrem("list2", "22",0) # 將列表中所有的"22"刪除
4、取值(根據索引號取值)
lindex(name, index)
在name對應的列表中根據索引獲取列表元素
print(r.lindex("list2", 0))
5.自定義增量迭代
由於redis類庫中沒有提供對列表元素的增量迭代,如果想要循環name對應的列表的所有元素,那麼就需要:
1、獲取name對應的所有列表
2、循環列表
但是,如果列表非常大,那麼就有可能在第一步時就將程序的內存撐爆,所有有必要自定義一個增量迭代的功能:
def list_iter(name):
""" 自定義redis列表增量迭代 :param name: redis中的name,即:迭代name對應的列表 :return: yield 返回 列表元素 """
list_count = r.llen(name)
for index in range(list_count):
yield r.lindex(name, index)
# 使用
for item in list_iter('list2'): # 遍歷這個列表
print(item)
1.新增
sadd(name,values)
name對應的集合中添加元素
2.獲取元素個數 類似於len
scard(name)
獲取name對應的集合中元素個數
3.獲取集合中所有的成員
smembers(name)
獲取name對應的集合的所有成員
r.sadd("set1", 33, 44, 55, 66) # 往集合中添加元素
print(r.scard("set1")) # 集合的長度是4
print(r.smembers("set1")) # 獲取集合中所有的成員
4、獲取集合中所有的成員,sscan(name)
返回一個元組,元組第二個成員是list的值。
print(r.sscan("set1"))
輸出:(0, [‘33’, ‘44’, ‘55’, ‘66’])
5、list可以做差、交、並集,這裡了解。
Set操作,Set集合就是不允許重復的列表,本身是無序的。
有序集合,在集合的基礎上,為每元素排序;元素的排序需要根據另外一個值來進行比較,
所以,對於有序集合,每一個元素有兩個值,即:值和權重,專門用來做排序。
1.新增
zadd(name, *args, **kwargs)
在name對應的有序集合中添加元素
2.獲取有序集合元素個數 類似於len
zcard(name)
獲取name對應的有序集合元素的數量
3、獲取有序集合的所有元素
r.zrange( name, start, end,
r.zadd("zset2", {
'm1': 22, 'm2': 44})
print(r.zcard("zset2")) # 集合長度
print(r.zrange("zset2", 0, -1)) # 獲取有序集合中所有元素
4、獲取所有元素–默認按照分數順序排序
zscan(name)
5 獲取所有元素–迭代器
zscan_iter(name)
print(r.zscan("zset2"))
for i in r.zscan_iter("zset2"): # 遍歷迭代器
print(i)
6、刪除–指定值刪除
zrem(name, values)
刪除name對應的有序集合中值是values的成員
r.zrem("zset2", "n3") # 刪除有序集合中的元素n3 刪除單個
1.刪除
delete(names)
根據刪除redis中的任意數據類型(string、hash、list、set、有序set)
r.delete("gender") # 刪除key為gender的鍵值對
2.檢查名字是否存在
exists(name)
檢測redis的name是否存在,存在就是True,False 不存在
print(r.exists("zset1"))
3.模糊匹配
keys(pattern=’’)
根據模型獲取redis的name
更多:
KEYS * 匹配數據庫中所有 key 。
print(r.keys("foo*"))
4.獲取類型
type(name)
獲取name對應值的類型
print(r.type("set1"))
5.查看所有元素
scan(cursor=0, match=None, count=None)
需要分類型。這裡注意
print(r.hscan("hash2"))
print(r.sscan("set3"))
print(r.zscan("zset2"))
6.查看所有元素–迭代器,需要分類型。
scan_iter(name, count=None)
for i in r.hscan_iter("hash1"):
print(i)
for i in r.sscan_iter("set3"):
print(i)
for i in r.zscan_iter("zset3"):
print(i)
redis默認在執行每次請求都會創建(連接池申請連接)和斷開(歸還連接池)一次連接操作,
如果想要在一次請求中執行多個命令,則可以使用pipline實現一次請求指定多個命令,並且默認情況下一次pipline 是原子性操作。
管道(pipeline)是redis在提供單個請求中緩沖多條服務器命令。減少服務器-客戶端之間反復的TCP數據庫包,從而大大提高了執行批量命令的效率。
import redis
import time
pool = redis.ConnectionPool(host='localhost', port=6379, decode_responses=True)
r = redis.Redis(connection_pool=pool)
pipe = r.pipeline() # 創建一個管道
pipe.set('name', 'jack')
pipe.set('role', 'sb')
pipe.sadd('faz', 'baz')
pipe.incr('num') # 如果num不存在則vaule為1,如果存在,則value自增1
pipe.execute()
print(r.get("name"))
print(r.get("role"))
print(r.get("num"))
管道的命令可以寫在一起,如:
pipe.set('hello', 'redis').sadd('faz', 'baz').incr('num').execute()
但是建議分開好看些。
(Redis) 是key-value 存儲系統,是跨平台的非關系型數據庫。
Redis 是一個開源的使用 ANSI C 語言編寫、遵守 BSD 協議、支持網絡、可基於內存、分布式、可選持久性的鍵值對(Key-Value)存儲數據庫,並提供多種語言的 API。
Redis 通常被稱為數據結構服務器,因為值(value)可以是字符串(String)、哈希(Hash)、列表(list)、集合(sets)和有序集合(sorted sets)等類型。