Python It's basically a bunch of dictionaries packed with grammar sugar .
-Lalo Martins, Early digital nomads and Python Experts
Of all the Python Dictionaries are used in programs . Even if it is not used directly in the code , It is also used indirectly , because dict The type is Python A foundation for implementation . Classes and instances are not issued 、 Module namespace and function keyword parameters are the core of memory and dictionary representation Python structure .__builtins__.__dict__ All built-in types are stored 、 Objects and functions .
Because of its great role ,Python The dictionary is highly optimized , And it's still improving .Python The engine behind the high-performance dictionary is the hash table .
Other built-in types based on hash tables are set and frozenset. They provide more than collections in other popular programming languages API And operators . say concretely ,Python Set realizes all basic operations in set theory , Such as union 、 intersection 、 Subset test, etc . With their help , We express the algorithm in a more declarative way , Avoid a large number of nested loops and conditional statements .
The following is an overview of this chapter :
dicts And modern grammar of mapping , Including enhanced unpacking and pattern matching .dict A variation of the .set and frozenset type . The following sections explain building 、 High level syntax for unpacking and handling mappings . Some of these features are not new to the language , But for the reader, it may be the first time to hear . Some of the syntax requires the use of Python 3.9( For example, pipeline operators |) or Python 3.10( Such as match/case). Let's start with an excellent and ancient feature .
from Python 2.7 Start , List derivation and generative expression are carried out dict The derived type ( as well as set The derived type , I'll explain later ) The adaptation of . The dictionary derivation receives... From any iteration object key:value To construct a dict example . example 3-1 Demonstrates the use of dict The derivation constructs two dictionaries from the same tuple list .
example 3-1: Examples of dictionary derivation
>>> dial_codes = [ # dial_codes Key value pairs iteratable objects can be passed directly to dict Constructors , however ...
... (880, 'Bangladesh'),
... (55, 'Brazil'),
... (86, 'China'),
... (91, 'India'),
... (62, 'Indonesia'),
... (81, 'Japan'),
... (234, 'Nigeria'),
... (92, 'Pakistan'),
... (7, 'Russia'),
... (1, 'United States'),
... ]
>>> country_dial = {country: code for code, country in dial_codes} # ... Key value intermodulation is performed here :country As the key ,code Value
>>> country_dial
{'Bangladesh': 880, 'Brazil': 55, 'China': 86, 'India': 91, 'Indonesia': 62,
'Japan': 81, 'Nigeria': 234, 'Pakistan': 92, 'Russia': 7, 'United States': 1}
>>> {code: country.upper() # Pair... By name country_dial Sort , Key value intermodulation , Values are capitalized , And then use code < 70 To filter
... for country, code in sorted(country_dial.items())
... if code < 70}
{55: 'BRAZIL', 62: 'INDONESIA', 7: 'RUSSIA', 1: 'UNITED STATES'}
If you can use list derivation , It is natural to use dictionary derivation . If not , The wide spread of deductive grammar shows that there are many benefits to using it fluently .
PEP 448— Unpacking overview supplement since Python 3.5 Started to enhance the support for two kinds of mapping unpacking .
First, you can use... For more than one parameter in a function call **. It can be used when the key of all parameters is a string and unique ( Because duplicate keyword parameters are allowed ).
>>> def dump(**kwargs):
... return kwargs
...
>>> dump(**{'x': 1}, y=2, **{'z': 3})
{'x': 1, 'y': 2, 'z': 3}
Secondly, in dict Literal is used internally **, It can also be used many times .
>>> {'a': 0, **{'x': 1}, 'y': 2, **{'z': 3, 'x': 4}}
{'a': 0, 'x': 4, 'y': 2, 'z': 3}
Duplicate keys appear in the above example , This is allowed . The latter will override the former , You can see in this example x Value .
This syntax can also be used to merge mappings , But there are other ways . Please listen to the following text .
Python 3.9 Supported in | and |= Merge mapping . It's very logical , These two categories are also set union operators .
Use | Operator new mapping :
>>> d1 = {'a': 1, 'b': 3}
>>> d2 = {'a': 2, 'b': 4, 'c': 6}
>>> d1 | d2
{'a': 2, 'b': 4, 'c': 6}
translator's note : mapping (mapping) Is a data type consisting of a set of keys and associated values . at present Python The only built-in mapping type is the dictionary .
This article will use Python 3.9 and Python3.10, Of course, you can install the latest version , Or install multiple versions locally Python, But it can also be done through Docker To test ( You can use the corresponding version of by specifying the image version Python, The following defaults to the latest version )
docker run -d --name python-alpine python:alpine watch "date >> /var/log/date.log" docker exec -it python-alpine sh # You can also exit after use docker run -it python:alpine sh
Generally, the type of the new mapping is the same as that of the left item , The above example is d1, However, if there is a user-defined type, it can also be the type of the second item , stay The first 16 Chapter The operator overloading rules section in the will explain .
Update existing mappings in place to use |=. Continue with the previous example , In the previous example d1 No modification occurred , But not in the following example :
>>> d1
{'a': 1, 'b': 3}
>>> d1 |= d2
>>> d1
{'a': 2, 'b': 4, 'c': 6}
Tips: : If maintenance is required Python 3.8 Or earlier ,PEP 584— Add union operator Of motivation Several methods of merging mapping types are summarized in the section .
Let's learn about mapping pattern matching .
match/case Statement supports mapping object bodies . The mapping pattern is similar to dictionary literals , But it can match any instance or collections.abc.Mapping Virtual subclass of .
stay The first 2 Chapter in , We only discuss the patterns of sequences , But different types of patterns can be merged 、 Embedded . With the help of deconstruction , Pattern matching is a powerful tool for handling structural records such as mapping and sequence nesting , Usually used to read JSON API And semi-structured patterns (schema) database , Such as MongoDB、EdgeDB or PostgreSQL. example 3-2 Demonstrated in .get_creators The simple type prompt in indicates that a dictionary was received , Returned a list .
example 3-2:creator.py: get_creators() Extract the creator name from the media record
def get_creators(record: dict) -> list:
match record:
case {'type': 'book', 'api': 2, 'authors': [*names]}: # Match any band 'type': 'book', 'api' :2 And mapping sequence 'authors' Key mapping . Return with a new list
return names
case {'type': 'book', 'api': 1, 'author': name}: # Match any band 'type': 'book', 'api' :2 And mapping objects 'authors' Key mapping . Return the object inside the list .
return [name]
case {'type': 'book'}: # Other belt 'type': 'book None of the mappings for are valid , Throw out ValueError
raise ValueError(f"Invalid 'book' record: {record!r}")
case {'type': 'movie', 'director': name}: # Match any band 'type': 'movie', 'api' :2 And mapping a single object 'director' Key mapping . Return the object inside the list
return [name]
case _: # Others are invalid , Throw out ValueError
raise ValueError(f'Invalid record: {record!r}')
example 3-2 It is a good demonstration of how to deal with JSON Such semi-structured data :
'type': 'movie')'api': 2'), Convenient for the future only API Evolution of case Clauses handle invalid records of specific types ( Such as 'book'), And exception trapping So let's see get_creators How to handle specific document tests :
>>> b1 = dict(api=1, author='Douglas Hofstadter',
... type='book', title='Gödel, Escher, Bach')
>>> get_creators(b1)
['Douglas Hofstadter']
>>> from collections import OrderedDict
>>> b2 = OrderedDict(api=2, type='book',
... title='Python in a Nutshell',
... authors='Martelli Ravenscroft Holden'.split())
>>> get_creators(b2)
['Martelli', 'Ravenscroft', 'Holden']
>>> get_creators({'type': 'book', 'pages': 770})
Traceback (most recent call last):
...
ValueError: Invalid 'book' record: {'type': 'book', 'pages': 770}
>>> get_creators('Spam, spam, spam')
Traceback (most recent call last):
...
ValueError: Invalid record: 'Spam, spam, spam'
Note that the ordering of keys in the schema is not important , image b2 It doesn't matter that the ordered dictionary in .
Different from the sequence pattern , The mapping only needs a partial match to succeed . In document testing b1 and b2 contain 'title' Key in all 'book' None of the patterns , But it can still match successfully .
No need to use **extra To match other key value pairs , But if you want to capture with a dictionary , You can add... Before a variable name **. This variable must be the last one in the schema , Not allowed **_, Because it's a bit of icing on the cake . A simple example :
>>> food = dict(category='ice cream', flavor='vanilla', cost=199)
>>> match food:
... case {'category': 'ice cream', **details}:
... print(f'Ice cream details: {details}')
...
Ice cream details: {'flavor': 'vanilla', 'cost': 199}
stay Automatically process keyless return values In the next section, we will learn defaultdict And others through __getitem__( namely d[key]) To query the key mapping , Because it creates missing items in real time , So the execution was successful . In pattern matching , Only in match The matching will succeed only when the key required by the statement exists .
Tips: : Automatic processing of missing keys is not triggered , The reason is that pattern matching always uses
d.get(key, sentinel)Method , The defaultsentinelIs a special tag value that cannot appear in user data .
Grammar and structure, for the time being , Let's learn about mapping API.
collections.abc Module provides Mapping and MutableMapping Abstract base class , describe dict And similar types of interfaces . See chart 3-1.
The main value of the abstract base class is the standard interface for recording and unified mapping , And the types that need to support mapping are mapped in the code isinstance As a condition when testing :
>>> my_dict = {}
>>> isinstance(my_dict, abc.Mapping)
True
>>> isinstance(my_dict, abc.MutableMapping)
True
Tips: : Using abstract base classes
isinstanceIt is usually better to check whether the function parameter isdictThe type is better , Because you can use other mapping types . We will be in The first 13 Chapter Discuss in detail
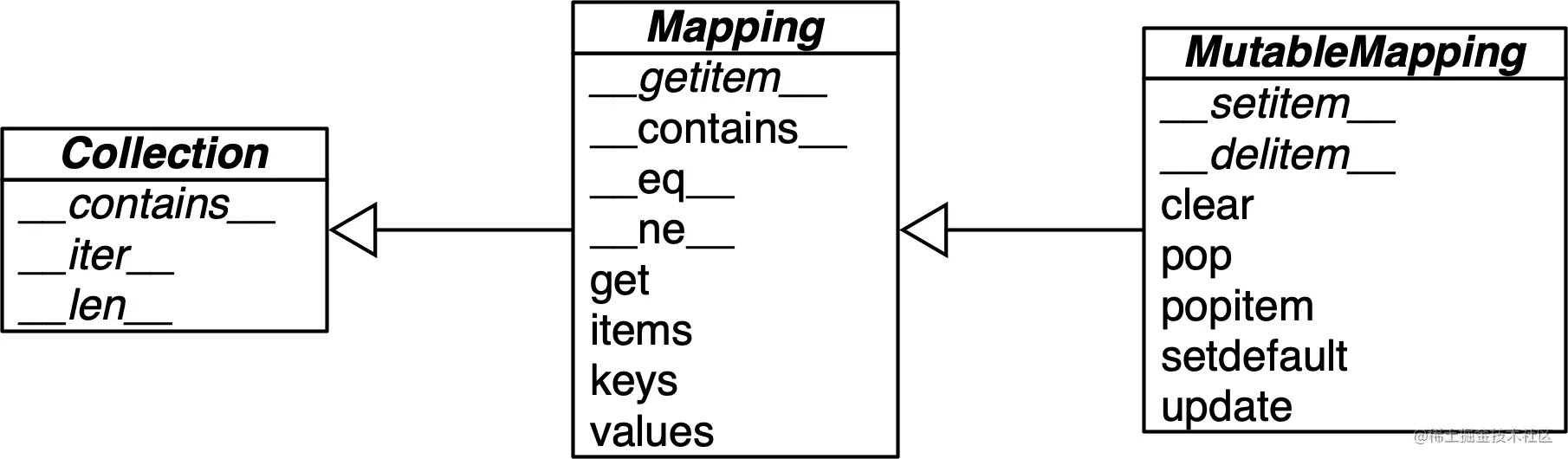
chart 3-1:collections.abc in MutableMapping And its parent class UML Class diagram ( The inheritance arrow points from the child class to the parent class , The names in italics are abstract classes and abstract methods )
To implement custom mapping , Inherit collections.UserDict Or packaged by combination dict It will be easier than these subclasses of the abstract base class .collections.UserDict Class and all concrete mapping classes in all standard libraries encapsulate the basic dict, Then build... From the hash table . therefore , Keys of these types must be hashable objects ( There is no such requirement for value , For keys only ). If you need to review the concept of hashable , The next section will explain .
Here is Python glossary The definition of hashable objects omitted in .
An object can be hashed, which means that the hash code will not change during its life cycle ( Use
__hash__()Method ), And can be compared with other objects ( Use__eq__()Method ). Equal hashable objects must have consistent hash codes .
Data types and common immutable types str And bytes Are hashable objects . Container types are hashable when they are immutable and the objects they contain are immutable .frozenset It must be hashable , Because every element it contains must be hashable by definition .tuple Hash only if all elements are hashable . See tuples tt、tl and tf:
>>> tt = (1, 2, (30, 40))
>>> hash(tt)
-3907003130834322577
>>> tl = (1, 2, [30, 40])
>>> hash(tl)
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: unhashable type: 'list'
>>> tf = (1, 2, frozenset([30, 40]))
>>> hash(tf)
5149391500123939311
In different machine architectures 、 Different Python The hash code of the object on the version will be different , For security reasons, salt will be added during hash operation . The hash code of the correctly implemented object is only guaranteed to be in the same Python Consistent throughout the process .
The default user-defined type is hashable , Because its hash code is id(), And through object Class inheritance __eq__() Method can compare the id. If the object implements a custom __eq__(), Consider its own state , Only in __hash__() Only objects with the same hash code are hashable . In practical use , This requires __eq__() and __hash__() Consider only instance properties that never change during the life of the object .
Now let's review Python The most commonly used mapping types API:dict、defaultdict and OrderedDict.
The basics of mapping API Quite rich . surface 3-1 Is shown in dict And two variants defaultdict and OrderedDict Method of implementation , Both are collections Defined in module .
surface 3-1: Mapping type dict、 collections.defaultdict and collections.OrderedDict Methods ( Common object methods are omitted for simplicity ); Optional parameters are placed in […] in
notes :
[a] default_factory It's not a way , But in defaultdict The callable property set set set by the end user during initialization
[b] OrderedDict.popitem(last=False) Delete the child item inserted first ( First in, first out ). In the new version Python 3.10b3 in dict or defaultdict Keyword parameters are not supported last
[c] stay The first 16 Chapter The reverse operator is explained in
d.update(m) Deal with the first parameter m The way of the duck is a major case of the duck type : First of all to see m Is there a keys Method , If so, it is considered as a mapping . otherwise update() Will be downgraded to yes m To iterate , Assume that its children are (key, value Yes .
A subtle mapping approach is setdefault(). It avoids redundant key queries when the values of children need to be updated in place . The next section explains how to use .
follow Python Of Fast failure philosophy (fail-fast ), visit d[k] stay k An error is thrown when the key does not exist .Python Programmers know d.get(k, default) yes d[k] An alternative , Used for default value ratio processing KeyError More convenient scenarios . But when you get a variable value and want to update , There's a better way .
Suppose you write a script to index text , Generate a mapping where the word is the value in the key list , See Example 3-3.
Example 3-3: Example 3-4 In dealing with Python Part of the output of Zen , Each line shows the word and its position in the list (line_number, column_number)
$ python3 index0.py zen.txt
a [(19, 48), (20, 53)]
Although [(11, 1), (16, 1), (18, 1)]
ambiguity [(14, 16)]
and [(15, 23)]
are [(21, 12)]
aren [(10, 15)]
at [(16, 38)]
bad [(19, 50)]
be [(15, 14), (16, 27), (20, 50)]
beats [(11, 23)]
Beautiful [(3, 1)]
better [(3, 14), (4, 13), (5, 11), (6, 12), (7, 9), (8, 11), (17, 8), (18, 25)]
...
Example 3-4 Is a sub optimal version , Exhibition dict.get Not the best way to handle missing keys . This example is modified from Alex Martelli An example of .
Example 3-4:index0.py Use dict.get obtain 、 Update the word list in the index ( For a better solution, see Example 3-5)
"""Build an index mapping word -> list of occurrences"""
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
# Ugly code , To illustrate a point of view
occurrences = index.get(word, []) # obtain word The location of , Return when you can't find it []
occurrences.append(location) # Append new position when it appears
index[word] = occurrences # The changed occurrences Add to index In the dictionary , This will in index For a second search
# Display alphabetically
for word in sorted(index, key=str.upper): # Yes sorted Of key= Parameter does not call str.upper, Just passing a reference to the method , such sorted The function can use it to normalize word sorting
print(word, index[word])
Example 3-4 In dealing with occurrences Three lines of code can use one line dict.setdefault Replace . Example 3-5 Closer to Alex Martelli Code for .
Example 3-5:index.py Use dict.setdefault obtain 、 Update the word list in the index , contrast Example 3-4
"""Build an index mapping word -> list of occurrences"""
import re
import sys
WORD_RE = re.compile(r'\w+')
index = {}
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index.setdefault(word, []).append(location) # Get appears word A list of , Set to... When not found [];setdefault Returns the value , Therefore, there is no need to search twice when updating
# Display alphabetically
for word in sorted(index, key=str.upper):
print(word, index[word])
let me put it another way , The result of the following line :
my_dict.setdefault(key, []).append(new_value)
It is consistent with the following results :
if key not in my_dict:
my_dict[key] = []
my_dict[key].append(new_value)
But the latter kind of code will be right key Perform at least two searches ( When not found, it is 3 Time ), and setdefault Only one query was made .
Related processing keyless queries ( More than just inserting ) Will be discussed in the next section .
Sometimes it is more convenient to return a single value when searching for a nonexistent key for a mapping . There are two main ways : One is to use defaultdict Replace dict. The other is to establish dict Or subclasses of other mapping types , add to __missing__ Method . These two methods will be discussed below .
collections.defaultdict Instance is in use d[k] Syntax searches for keys that do not exist create a child with default values as needed . Example 3-6 Use defaultdict Provide another elegant solution to deal with Example 3-5 Word indexing task in .
The principle is as follows : In instantiation defaultdict when , Pass a nonexistent key to __getitem__ A callable method that generates default values is provided .
for example , Assumed use dd = defaultdict(list) Create a default value Dictionary , If dd There is no 'new-key',dd['new-key'] Will complete the following steps :
list() Create a new list 'new-key' Key to insert the list dd The default value generated by this callable method is in the instance as default_factory Property to store .
Example 3-6:index_default.py: Use defaultdict Replace setdefault Method
"""Build an index mapping word -> list of occurrences"""
import collections
import re
import sys
WORD_RE = re.compile(r'\w+')
index = collections.defaultdict(list) # Use list Constructor creation default_factory Default dictionary
with open(sys.argv[1], encoding='utf-8') as fp:
for line_no, line in enumerate(fp, 1):
for match in WORD_RE.finditer(line):
word = match.group()
column_no = match.start() + 1
location = (line_no, column_no)
index[word].append(location) # If index There is no word, Would call default_factory To generate missing values , This example assigns an empty list to index[word] And back to , therefore .append(location) Can maintain success
# Display alphabetically
for word in sorted(index, key=str.upper):
print(word, index[word])
If provided default_factory, Will throw the missing key KeyError.
Warning : Only when it comes to
__getitem__When the call provides a default valuedefaultdictOfdefault_factoryWill call , Invalid for other methods . for example , hypothesisddIt's adefaultdict,kIs a nonexistent key ,dd[k]Would calldefault_factoryCreate default values , butdd.get(k)Still return toNone,k in ddbyFalse.
call default_factory To make the defaultdict The mechanism for normal operation is __missing__ Method , In the next section, we discuss .
The underlying method for mapping missing keys is aptly named __missing__. This method is not in dict In the base class , but dict Can sense it : If dict Subclasses provide __missing__ Method , The standard dict.__getitem__ It will be called when the key cannot be found , Instead of throwing KeyError.
Suppose you want to convert all mapped keys to strings at lookup time . The actual case is the equipment library of the Internet of things , One belt can be used I/O Pin programmable panel ( Like raspberry pie or Arduino) use my_board.pins Attribute Board Class represents , This attribute is the mapping between the physical pin identifier and the pin software object . The physical pin identifier may be numeric or "A0"、"P9_12" Such a string . For consistency , best board.pins All keys in are strings , But it is also very convenient to find by numbers , Such as my_arduino.pin[13], So beginners don't want to Arduino Of 13 On the pin LED Flashing and having problems . Example 3-7 Demonstrates how this type of mapping can be used .
Example 3-7: When searching for non string keys , When not found StrKeyDict0 Convert it to a string
Use `d[key]` Mark the test to get the subitem :
>>> d = StrKeyDict0([('2', 'two'), ('4', 'four')])
>>> d['2']
'two'
>>> d[4]
'four'
>>> d[1]
Traceback (most recent call last):
...
KeyError: '1'
Use `d.get(key)` Mark the test to get the subitem :
>>> d.get('2')
'two'
>>> d.get(4)
'four'
>>> d.get(1, 'N/A')
'N/A'
`in` Operator test
>>> 2 in d
True
>>> 1 in d
False
Example 3-8 Implements the transfer of pre test documents StrKeyDict0 class
Tips: : A better way to create user-defined mapping types is to use
collections.UserDictSubclass substitutiondict( stay Example 3-9 Will do this in ). Use heredictSubclasses are just for demonstration__missing__Built in bydict.__getitem__Method to support .
Example 3-8:StrKeyDict0 Convert non string keys to strings when querying ( Parameters Example 3-7)
class StrKeyDict0(dict): # StrKeyDict0 Inherit dict
def __missing__(self, key):
if isinstance(key, str): # see key Is it a string . If so and does not exist , Throw out KeyError
raise KeyError(key)
return self[str(key)] # adopt key Construct string , Search again
def get(self, key, default=None):
try:
return self[key] # get Method by using self[key] Agent to __getitem__, This is given. __missing__ Opportunities to work
except KeyError:
return default # If it throws KeyError,__missing__ Failed , So back to default
def __contains__(self, key):
return key in self.keys() or str(key) in self.keys() # Search for unmodified keys ( Instances may contain non string keys ), Then search for strings constructed with keys
Take a moment to think about what will happen in __missing__ The implementation needs to be tested isinstance(key, str).
Do not perform this test , stay str(k) For existing keys k Is it a string __missing__ Methods are running normally . But if str(k) If it doesn't exist , Will enter infinite loop . stay __missing__ Last line ,self[str(key)] Would call __getitem__, Pass in str key , This will call again __missing__.
You need to use __contains__ To maintain consistency in the example , because k in d The operation will call it , But from dict Inherited methods are not downgraded to call __missing__. stay __contains__ There is a detail in the implementation of : We didn't press Pythonic The way (k in my_dict) Lookup key , because str(key) in self It'll loop __contains__. By explicitly in self.keys() To avoid this problem .
image k in my_dict.keys() This search is even for very large mappings in Python 3 Is also very efficient , because dict.keys() Return a view , Similar to collection , We will be in Collection operation of dictionary view In this section . however , please remember k in my_dic The same task was accomplished , It's faster because you don't have to use attribute queries to find .keys Method .
Example 3-8 In the __contains__ Internal use self.keys() There are special reasons . Check for unchanged keys (key in self.keys()) Can guarantee the correctness , because StrKeyDict0 It is not mandatory that all key types of the dictionary must be str. The only purpose of this simple example is to make the search more “ friendly ” Instead of forcing types .
Warning : User defined classes derived from the standard are in
__getitem__、getor__contains__Is not necessarily used in the implementation of__missing__As a backup method , It will be explained in the next section .
Consider the following scenarios and the impact of missing key queries :
dict Subclass
dict Subclasses only implement __missing__ There is no other way . At this time , Only to d[k] call __missing__, It will use from dict Inherit in __getitem__ Method .
collections.UserDict Subclass
Similarly UserDict Subclasses only implement __missing__ There is no other way . Inherited from UserDict Of get Method call __getitem__. This means that... May be called __missing__ To deal with it d[k] and d.get(k) Lookup .
With the most simplified __getitem__ Of abc.Mapping Subclass
abc.Mapping Minimal subclass implementation of __missing__ And the required abstract methods , Contains no calls to __missing__ Of __getitem__ The implementation of the . Does not trigger in this class __missing__ Method .
With call __missing__ Of __getitem__ Of abc.Mapping Subclass
abc.Mapping Minimal subclass implementation of __missing__ And the required abstract methods , Contains calls to __missing__ Of __getitem__ The implementation of the . Calling d[k], d.get(k) and k in d A missing key will trigger __missing__ Method .
See missing.py The demonstration of the above scenario in the sample code .
The above four scenarios are minimization implementations . If the subclass implements __getitem__、get and __contains__, Then you can choose whether to use the __missing__. The purpose of this section is to show what you should pay attention to when creating a standard library mapping subclass __missing__ Use , Because these base classes support different behaviors by default .
Don't forget setdefault and update The behavior of is also influenced by key queries . Last , according to __missing__ The logic of , It may be necessary to __setitem__ To avoid inconsistencies or unexpected behavior . We will be in Use UserDict replace dict Parturient See the example in the section .
So far we have explained dict and defaultdict Mapping type , But there are other mapping implementations in the standard library , Let's discuss .
This section provides an overview of the mapping types included in the standard library ,defaultdict stay defaultdict: Handle nonexistent keys Has been discussed in , Skip here .
Python 3.6 Built in dict The key of , Use OrderedDict The main reason for this is to write for earlier versions Python Backward compatible code .Python The documentation for dict and OrderedDict The difference between , Quote the following ( Rearranged by the relevance used by the date ):
OrderedDict Detection of matching sort by equivalent operation of .OrderedDict Of popitem() Methods have different signatures . It receives optional parameters for specifying the pop-up item .OrderedDict There is one move_to_end() Method , Effectively relocate elements to endpoints .dict The mapping operation is well designed . The tracking insertion sequence is placed in the secondary position .OrderedDict Designed to handle reordering operations . Space efficiency 、 The iteration speed and the performance of update operation are placed in the second place .OrderedDict The processing of frequency heavy sorting operation is better than dict. This makes it suitable for tracking the latest visits ( Such as LRU cache ).ChainMap The instance stores the mapping list that can be searched together . The lookup is performed in the order mapped in the construct call , Finding the key in the map is success . for example :
>>> d1 = dict(a=1, b=3)
>>> d2 = dict(a=2, b=4, c=6)
>>> from collections import ChainMap
>>> chain = ChainMap(d1, d2)
>>> chain['a']
1
>>> chain['c']
6
ChainMap The instance does not copy the input mapping , But keep its pointer . Yes ChainMap The update or insert of only affects the first input mapping . Continue to use the previous example :
>>> chain['c'] = -1
>>> d1
{'a': 1, 'b': 3, 'c': -1}
>>> d2
{'a': 2, 'b': 4, 'c': 6}
ChainMap Useful for implementing language compilers with nested scopes , Each of these mappings represents a scope context , From the innermost scope to the outermost scope .collections Document ChainMap object There are several in this section ChainMap Use example of , Including by Python Code snippet inspired by the basic rules of variable query in :
import builtins
pylookup = ChainMap(locals(), globals(), vars(builtins))
Example 18-14 For implementing the schema programming language subset interpreter ChainMap Subclass .
This is a map that stores integer counts per key . Update existing keys or add calculations . This can be used to count hashable objects or multiple collections ( Later in this section ).Counter Realized + and - Operator to sum , There are other useful ways , Such as most_common([n]), Return to the former n Sort list and number of the most common tuples ; See Official documents . Here is how to count the letters in a word Counter:
>>> ct = collections.Counter('abracadabra')
>>> ct
Counter({'a': 5, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.update('aaaaazzz')
>>> ct
Counter({'a': 10, 'z': 3, 'b': 2, 'r': 2, 'c': 1, 'd': 1})
>>> ct.most_common(3)
[('a', 10), ('z', 3), ('b', 2)]
Attention key 'b' and 'r' Both are the third , but ct.most_common(3) Only 3 Statistics .
To use with multiple sets collections.Counter, Suppose each key in the collection is an element , Count the number of occurrences of this element in the collection .
In the standard library shelve Modules provide persistent storage of mappings , Map to a string key pair with pickle Serialized in binary format Python object . When you realize that pickle cans need to be stored on shelves, you will find shelve The name is logical .
Module level functions shelve.open Return to one shelve.Shelf example , This is a result of dbm Simple key values supported by the module DBM database , It includes the following features :
shelve.Shelf yes abc.MutableMapping Subclasses of , Therefore, it provides the basic methods that mapping types should have .shelve.Shelf Provided some I/O Management , Such as sync and close.Shelf The instance is a context manager , So you can use with Code block to ensure that it is closed after use .pickle Serializable objects .shelve、dbm and pickle The documentation of provides more details and some warnings .
Warning : In the simplest use case
pickleIs very simple to use , But there are some shortcomings . The use involvespickleRead before you read the proposal Ned Batchelder Of “Pickle9 sin ”.Ned Other serialization formats to consider are mentioned .
Can be used directly OrderedDict、 ChainMap、Counter and Shelf, But it can also be customized by subclasses . By comparison ,UserDict Only as the base class to be inherited .
It is best to inherit collections.UserDict Instead of dict To create a new mapping type . stay Example 3-8 in StrKeyDict0 Inheritance recognizes the need to ensure that all keys added to the map are stored as strings .
Use UserDict replace dict The main reason for subclassing is that there are some built-in implementation shortcuts that ultimately force overloaded methods , And through inheritance UserDict There is no problem .
Be careful UserDict Not inherited from dict, Instead, a combination is used : It has a built-in dict example , be known as data, Stores the actual children . This avoids using __setitem__ This method has unexpected loops , And simplify __contains__ The coding , contrast Example 3-8.
With UserDict, Give Way StrKeyDict( example 3-9) Than StrKeyDict0( example 3-8) More concise , But there's more to it : It stores all keys in a string , Avoid meaningful behavior when building or updating instances by including non string key data .
example 3-9: In the insert 、 When updating and searching StrKeyDict Always update non string keys to str
import collections
class StrKeyDict(collections.UserDict): # StrKeyDict Inherit UserDict
def __missing__(self, key): # __missing__ And example 3-8 In the same
if isinstance(key, str):
raise KeyError(key)
return self[str(key)]
def __contains__(self, key): # __contains__ It's simpler : We can assume that all stored keys are strings , Then check that the self.data, Without having to like StrKeyDict0 Call as in self.keys()
return str(key) in self.data
def __setitem__(self, key, item): # __setitem__ Will all key Convert to string . Can be represented to self.data Property is easier to override
self.data[str(key)] = item
because UserDict Inherit abc.MutableMapping, The rest will be StrKeyDict The method of becoming a perfect mapping is inherited from UserDict、MutableMapping or Mapping. Although the latter is an abstract base class , But there are some useful concrete methods . The following methods are worth mentioning :
MutableMapping.update
This powerful method can be called directly , But also by __init__ Used to load instances from other mappings , from (key, value) For iteratable objects to keyword parameters . Because of its use self[key] = value Add child , Will eventually call our __setitem__ Realization .
Mapping.get
stay StrKeyDict0( example 3-8) in , We need to write our own get To return and __getitem__ Same result , But in example 3-9 We inherited Mapping.get, The implementation and StrKeyDict0.get Exactly the same as ( See Python Source code ).
Tips: :Antoine Pitrou Write the PEP 455- Add a key translation dictionary to the container And the use of
TransformDictenhancecollectionsPatches for modules , This is more thanStrKeyDictA more general , Keep the provided keys until the transformation is applied .PEP 455 stay 2015 year 5 Month rejected , See Raymond Hettinger Of Reject the message . To experienceTransformDict, I will issue18986 in Pitrou The patch is extracted as a separate module ( See 03-dict-set/transformdict.py).
We know that there are immutable sequence types , What about immutable mapping ? There is no such thing in the standard library , But there is a double . Let's talk about .
The mapping types provided by the standard library are all mutable , But sometimes you need to prevent users from accidentally modifying the mapping . You can find real cases , stay __missing__ Method The image mentioned in the section Pingo Such a hardware programming library :board.pins The mapping represents the actual... On the device GPIO( General input output ) Pin . At this time , Prevent inadvertent updates board.pins It would be very useful , Because the hardware cannot be changed by the software , Therefore, changes in the mapping will make the real device inconsistent .
types The module provides a file named MappingProxyType The wrapper class , Returns... When a mapping is given mappingproxy example , It is read-only but can dynamically proxy to the original mapping . That is to say, the update of the original mapping is in mappingproxy You can see , But it can't be modified . See Example 3-10 Simple demonstration in .
Example 3-10:MappingProxyType adopt dict Build a read-only mappingproxy
>>> from types import MappingProxyType
>>> d = {1: 'A'}
>>> d_proxy = MappingProxyType(d)
>>> d_proxy
mappingproxy({1: 'A'})
>>> d_proxy[1] # stay d_proxy Can be seen in d
'A'
>>> d_proxy[2] = 'x' # Unable to get d_proxy Make changes
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'mappingproxy' object does not support item assignment
>>> d[2] = 'B'
>>> d_proxy # d_proxy Is dynamic ,d All the changes in
mappingproxy({1: 'A', 2: 'B'})
>>> d_proxy[2]
'B'
>>>
This is how you might actually use it in a hardware programming scenario :Board The subclass constructor will directly fill a private mapping through the pin object , And by pressing mappingproxy Implementation of public .pins Attributes are exposed to API client . In this way, the client cannot accidentally add 、 Delete or modify pins .
Next, we will explain the view , Without unnecessary data copying , Allow for dict High performance computing .
dict Example method .keys()、.values() and .items() Return names respectively dict_keys、dict_values and dict_items Instance class of . These dictionary views are right dict A read-only projection of the internal data structure used in the implementation . They avoid Python 2 Return from the original dict Memory pressure such as returning a copy list of existing data in the target , It also replaces the old method that returns iterators .
Example 3-11 It shows some basic operations supported by all dictionary views .
Example 3-11:.values() Returns a view of values in the dictionary
>>> d = dict(a=10, b=20, c=30)
>>> values = d.values()
>>> values
dict_values([10, 20, 30]) # Of the view object repr Show its contents
>>> len(values) # Query the length of the view
3
>>> list(values) # Views are iterative , So it's easy to create lists from them
[10, 20, 30]
>>> reversed(values) # View implementation __reversed__, Returns a custom iterator
<dict_reversevalueiterator object at 0x10e9e7310>
>>> values[0] # have access to [] To get the individual items in the view
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: 'dict_values' object is not subscriptable
The view object is a dynamic proxy . If the source dictionary is updated , You can immediately see the changes through the existing view . Continue to use Example 3-11:
>>> d['z'] = 99
>>> d
{'a': 10, 'b': 20, 'c': 30, 'z': 99}
>>> values
dict_values([10, 20, 30, 99])
dict_keys、dict_values and dict_items Is the inner class : stay __builtins__ And standard library modules , Even if you get its pointer , Nor can it be used in Python Create a view from zero in code :
>>> values_class = type({}.values())
>>> v = values_class()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
TypeError: cannot create 'dict_values' instances
dict_values Class is the simplest dictionary view , It only implements __len__、__iter__ and __reversed__ Special methods . In addition to these methods ,dict_keys and dict_items Some collection methods are also implemented , Almost and frozenset Classes . After the assembly , We will be in Set operation of dictionary view In the next section dict_keys and dict_items.
Now let's learn from dict Some rules and tips generated by the underlying implementation .
Python The hash table implementation of the dictionary is very efficient , But it is important to understand the actual effect of this design :
__hash__ and __eq__ Method .dict More compact memory layout , This is in 3.7 Become an official language feature in .__init__ Create instance properties outside method . The last tip on instance properties comes from Python The default behavior of is to store instance properties in a special __dict__ Properties of the , It is a dictionary attached to each instance . Since the Python 3.3 Implemented in the PEP 412— Key sharing Dictionary , Class can share common hash tables , Store with classes . Commonly used hash tables are in __init__ When returning, the first instance of the class has the same property name , By each new instance __dict__ share . Of each instance __dict__ A simple array of pointers can then store only its own property values . stay __init__ Add the instance attribute to force Python For the instance __dict__ Create hash table ( This is a Python 3.3) Default behavior for all previous instances ). according to PEP 412, This optimization reduces the cost of object-oriented programming 10% To 20% Memory usage .
The details of compact layout and key sharing optimization are very complex . Read more The internal principles of sets and dictionaries .
Let's move on to the explanation of the collection .
Assemble in Python China is not new , But the utilization rate is still not high .set Types and their immutable siblings frozenset The first is Python 2.3 The standard library appears as a module , stay Python 2.6 Promoted to a built-in type .
notes : In this book , We use sets to refer to
setandfrozenset. In the specific discussionsetClass time , I use fixed width fonts :set.
A collection is a unique set of objects . The basic usage is to delete duplicates :
>>> l = ['spam', 'spam', 'eggs', 'spam', 'bacon', 'eggs']
>>> set(l)
{'eggs', 'spam', 'bacon'}
>>> list(set(l))
['eggs', 'spam', 'bacon']
Tips: : If you want to delete duplicates but keep the sorting of the first occurrence of each item , You can use a common dictionary to implement , Such as :
>>> dict.fromkeys(l).keys() dict_keys(['spam', 'eggs', 'bacon']) >>> list(dict.fromkeys(l).keys()) ['spam', 'eggs', 'bacon']
Collection elements must be hashable .set The type is not hashable , Therefore, it is not possible to use embedded set Instance to build set. but frozenset Is hashable , So in set Can be used in frozenset.
In addition to mandatory uniqueness , Set type implements many set operations with intermediate operators , So let's give two sets a and b,a | b Back to Union ,a & b Calculate the intersection ,a - b Calculate the difference set , and a ^ b Is the bisection difference . The rational use of set operations will reduce Python The amount of code and execution time of the program , meanwhile ( By removing loops and conditional logic ) Simplified code reading and reasoning .
for example , Suppose there is a large collection of email addresses (haystack) And a small set of addresses (needles), Need to calculate haystack How many needles. With the help of set Intersection (& Operator ), You can use just one line of code ( See Example 3-12).
Example 3-12:haystack in needles Number of occurrences , Both are collection types
found = len(needles & haystack)
If you do not use the intersection operator , You need to write Example 3-13 To complete Example 3-12 The task of
found = 0
for n in needles:
if n in haystack:
found += 1
example 3-12 Than example 3-13 It runs faster . and example 3-13 Applies to all iteration objects needles and haystack, but example 3-12 Both are required to be sets . But if you don't have a collection , It can be built in real time , See Example 3-14.
Example 3-14: Calculation haystack in needles Number of occurrences , The code applies to any iteration type
found = len(set(needles) & set(haystack))
# Another way :
found = len(set(needles).intersection(haystack))
Of course Example 3-14 There is some overhead in building collections in , But if needles or haystack It's not a collection , Example 3-14 The cost of is still less than Example 3-13.
The code in the above example is available 0.3 Milliseconds or so 10,000,000 Project haystack Search for 1,000 Elements - Equivalent to elements, about 0.3 Microsecond .
In addition to extremely fast member testing ( With the help of the underlying hash table ),set and frozenset Built in types provide a wealth of API Used to create a new set , Or modify the existing set. We'll talk about operations later , But first, let's talk about grammar .
set Literal grammar ({1}、{1, 2} etc. ) Just like data markers , But there is an important difference : There is no air set Literal mark of , So you have to write set().
Grammatical Oddities : Don't forget to create an empty
set, You should use a constructor with no argumentsset(). If write{}, It creates an empty dictionary ,Python 3 It's the same with China .
stay Python 3 in , The standard string representation of the collection uses {…} Mark , Except for empty sets :
>>> s = {1}
>>> type(s)
<class 'set'>
>>> s
{1}
>>> s.pop()
1
>>> s
set()
{1, 2, 3} Such literal set syntax is not only faster , Than calling a constructor ( Such as set([1, 2, 3])) More readable . The reason why the latter is slower is to calculate it ,Python Need to find set Name to get the constructor , Then build the list , Finally, it is passed to the constructor . contrary , Handle {1, 2, 3} Such a literal amount ,Python Run a special bytecode BUILD_SET.
Express frozenset Literal quantities have no special syntax , Must be created by calling the constructor .Python 3 The standard string representation in is similar to frozenset Construct method calls . Note the output in the console :
>>> frozenset(range(10))
frozenset({0, 1, 2, 3, 4, 5, 6, 7, 8, 9})
When it comes to grammar , The idea of list derivation is also applied to sets .
Set derivation (setcomps) stay Python 2.7 And Dictionary derivation Added together . See Example 3-15.
Example 3-15: structure Unicode The name contains the word “SIGN” Of Latin-1 Character set
>>> from unicodedata import name # adopt unicodedata Import name Get character names
>>> {chr(i) for i in range(32, 256) if 'SIGN' in name(chr(i),'')} # structure 32 To 255 The code name contains the word “SIGN” Set of characters
{'§', '=', '¢', '#', '¤', '<', '¥', 'µ', '×', '$', '¶', '£', '',
'°', '+', '÷', '±', '>', '¬', '', '%'}
Every time Python The output order of processing is different , The reason is that What is a hashable object Salt hash discussed in .
Put grammar aside , Let's think about the behavior of collections .
set and frozenset Types are implemented through hash tables . This has the following effect :
__hash__ and __eq__ Method .See The internal principles of sets and dictionaries Learn more .
Let's review the large number of operations provided by sets .
chart 3-2 Gives an overview of the methods available in variable and immutable sets . Many of them are special methods of overloading operators , Such as & and >=. surface 3-2 It shows the mathematical set operation in Python There are corresponding operators or methods in . Note that some operators and methods are modified in the original target set ( Such as &=、difference_update etc. ). This kind of operation has no meaning in the ideal world of data sets , stay frozenset Is not implemented in .
Tips: : surface 3-2 The intermediate operator in requires that both operands are sets , But other methods accept one or more iteratible parameters . for example , Generate 4 A collection of
a、b、canddUnion , You can calla.union(b, c, d), amongaMust be a collection , butb、canddIt can be any iteratable type that generates hash items . If you need to pass 4 Union of iterated objects to create a new set , Do not update existing collections , We can write{*a, *b, *c, *d}, Thanks to Python 3.5 Introduced PEP 448— Other unpacking specifications .
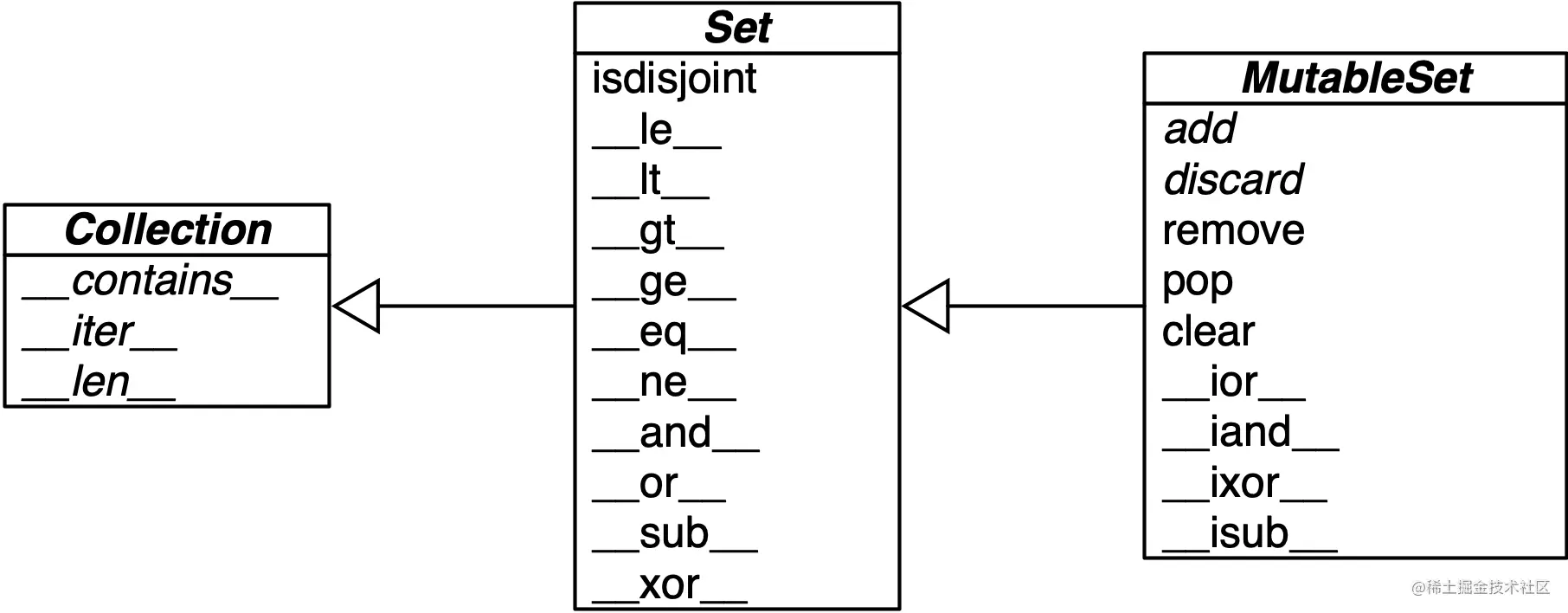
chart 3-2:MutableSet And its collections.abc Simplification of the parent class in UML Class diagram ( The names in italics are abstract classes and abstract methods , The inverse operator method is omitted for simplicity )
surface 3-2: Mathematical set operation : These methods either generate a new set or update the original target set when the set changes
surface 3-3 Enumerate set verbs : return True or False Operator and method of .
surface 3-3: Set comparison operators and methods that return Boolean values
Except for operators and methods derived from mathematical set theory , The collection types that implement other utility methods are summarized as surface 3-4.
surface 3-4: Other set methods
This completes the overview of collection features . stay Dictionary view Has promised , Let's explain why the two types of dictionaries behave similarly frozenset.
surface 3-5 The dictionary method is shown .keys() and .items() The returned view object is the same as frozenset Amazing similarities .
surface 3-5: from frozenset、dict_keys and dict_items Method of implementation
frozenset | dict_keys | dict_items | describe | | -------------------------- | --------- | --------- | ---------- | ------------------ | | s.and(z) | ● | ● | ● | s & z (s and z Intersection ) | | s.rand(z) | ● | ● | ● | reverse & operation | | s.contains() | ● | ● | ● | e in s | | s.copy() | ● | | | s The shallow copy | | s.difference(it, …) | ● | | | s And iteratable objects it Equal difference set | | s.intersection(it, …) | ● | | | s And iteratable objects it And so on | | s.isdisjoint(z) | ● | ● | ● | s and z Disjoint ( There is no common element ) | | s.issubset(it) | ● | | | s Is an iterable object it Subset | | s.issuperset(it) | ● | | | s Is an iterable object it Superset | | s.iter() | ● | ● | ● | obtain s The iterator | | s.len() | ● | ● | ● | len(s) | | s.or(z) | ● | ● | ● | s | z (s and z Union ) | | s.ror() | ● | ● | ● | reverse | operation | | s.reversed() | | ● | ● | Get... In reverse order s The iterator | | s.rsub(z) | ● | ● | ● | In reverse - operation | | s.sub(z) | ● | ● | ● | s - z (s and z The difference between the set ) | | s.symmetric_difference(it) | ● | | | s & set(it) The complement of | | s.union(it, …) | ● | | | s And iteratable objects it Union of etc | | s.xor() | ● | ● | ● | s ^ z (s and z Equivalent difference of ) | | s.rxor() | ● | ● | ● | In reverse ^ operation
In especial dict_keys and dict_items Special methods are implemented to support powerful set operations & ( intersection ), | ( Combine ), - ( Combine ), and ^ ( Equal difference ).
for example , Use & It's easy to get key names that appear in both dictionaries :
>>> d1 = dict(a=1, b=2, c=3, d=4)
>>> d2 = dict(b=20, d=40, e=50)
>>> d1.keys() & d2.keys()
{'b', 'd'}
Be careful & The return value of set. Even better, the set operators in the dictionary view are fully compatible set example . Look at the following example :
>>> s = {'a', 'e', 'i'}
>>> d1.keys() & s
{'a'}
>>> d1.keys() | s
{'a', 'c', 'b', 'd', 'i', 'e'}
Warning :
dict_itemsA view can be used as a collection only if all elements in the dictionary can be hashed . For non hashable valuesdict_itemsWhen a view performs a set operation, it throwsTypeError: unhashable type 'T',TIs a type that does not conform to the rule value .
and dict_keys Always available as a collection , Because every key is hashable by definition .
Using the set operator to view the contents of the code dictionary will save a lot of loops and conditional judgments . Give Way Python It's efficient C Serve you !
That is all about this chapter .
The dictionary is Python Important sections of . After years of development , conversant {k1: v1, k2: v2} Literal syntax has been enhanced to support ** Unpack 、 Pattern matching and dictionary derivation .
Except for the basic dict, The standard library also provides convenience 、 Easy to use special mapping , Such as defaultdict、ChainMap and Counter, All in collections Module . With new dict Realization ,OrderedDict No longer as useful as it used to be , However, it should still be placed in the standard library for backward compatibility , also dict There are some characteristics that do not exist , If you have considered == Sorting in comparison operation . At the same time collections There is also UserDict, Easy to use base class for creating custom mappings .
The two main methods that exist in most mappings are setdefault and update.setdefault Method to update a child item that stores a variable value , for example , stay list Value dictionary , Avoid searching for the same key name .update Allow other mappings 、 Provide (key, value Batch insert or rewrite subitems of the iteratable objects and keyword parameters of . The mapping constructor also uses update, Allow instances to pass through mappings 、 Iterative object or keyword parameter initialization . from Python 3.9 Start , We can also use |= Operator update mapping , as well as | Operator creates a new by combining two mappings .
mapping API A smart hook for is __missing__ Method , Allow us to use d[k] Syntax call __getitem__ Custom behavior when key not found .
collections.abc The module provides Mapping and MutableMapping Abstract base classes as standard interfaces , Useful for runtime type checking .types Module MappingProxyType Create an immutable facade that you do not want to accidentally change the mapping .Set and MutableSet Also abstract the base class .
The dictionary view is Python 3 A great addition to , In addition to the Python 2 in .keys()、.values() and .items() Memory load , These methods were then adopted at the target dict Copy the data in the instance to build the list . Besides dict_keys and dict_items Class supports frozenset The most useful operators and methods in .