最近發現周圍的很多小伙伴們都不太樂意使用pandas,轉而投向其他的數據操作庫,身為一個數據工作者,基本上是張口pandas,閉口pandas了,故而寫下此系列以讓更多的小伙伴們愛上pandas。
系列文章說明:
系列名(系列文章序號)——此次系列文章具體解決的需求
平台:
windows 10
python 3.8
pandas >=1.2.4
最近在互聯網遨游時偶然發現一道很有趣的pandas實例訓練題目,題目距今已發布很久,也已經有人為此解答過了,說:有一組數據,每列分別記錄著樣品的各個指標情況,欲對每個數據各個指標進行計算,求各個樣品之間的指標差值的絕對值的總和最小的對應的幾個樣品,如:a樣品:[10.0, 9.0, 7.5, 8.6],b樣品:[11.2, 8.7, 6.4, 5.5]之間的相似度計算為:|10.0-11.2|+|9.0-8.7|+|7.5-6.4|+|8.6-5.5|。
對應位置相減取絕對值後再相加,為每個樣品對其余樣品進行計算,求得所有樣品的與其相似度最小的5個其他樣品。
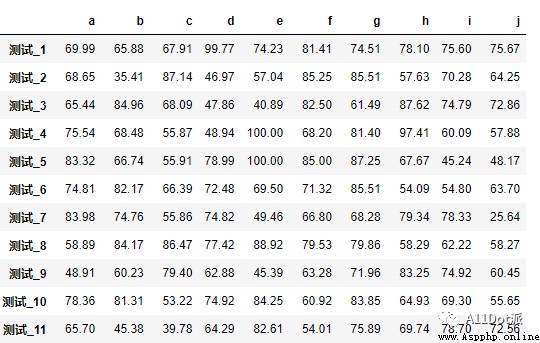
根據上述描述,構造一組隨機數據:
import numpy as np
import pandas as pd
np.random.seed(2022)
data = np.clip(np.random.normal(loc=70, scale=15, size=600).round(2), 0, 100).reshape(60, 10)
df = pd.DataFrame(data, columns=list('abcdefghij'), index=[f'測試_{i}' for i in range(1, 61)])數據大小為:60*10,浮點型類型。
方法一:笛卡爾積
先計算每個樣品的交叉數據,再分組獲取組內排名在上的5個數據。
這個方法是該題目下方解答者大佬的方法,其使用的方法進行笛卡爾乘積非常有意思。
df = df.reset_index().rename(columns={'index': '名稱'})
# 設置輔助列
df['one'] = 1
# merge自身,以one列作為key參數合並數據框
df_merge = pd.merge(left=df, right=df, left_on='one', right_on='one')原數據大小為60*10,乘積後為3600行,內存占用大小相比處理前大了不少,如果數據過大,在處理方面,耗時上會顯著增加。
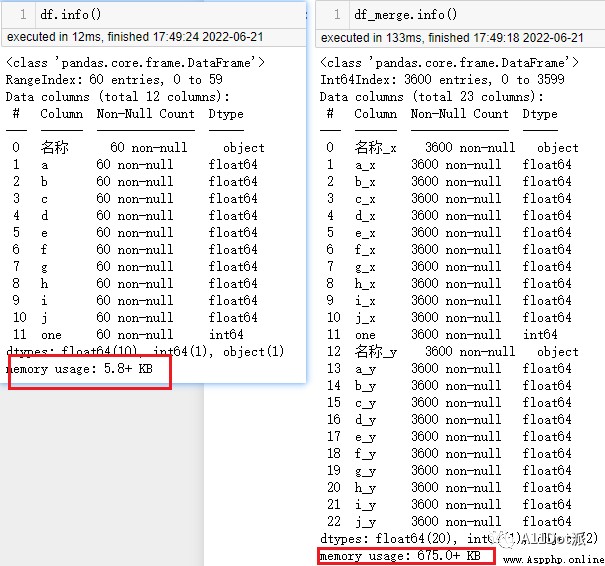
暫且不考慮數據量的影響,繼續處理。
# 剔掉名稱列和one列
columns = list(df.columns)
columns.remove('名稱')
columns.remove('one')
def sim_fun(row):
sim_value = 0.0
for col in columns:
sim_value += abs(round(row[col+'_x'] - row[col+'_y'], 2))
return round(sim_value, 2)
# 求出每個樣品之間的相似值
df_merge['sim'] = df_merge.apply(sim_fun, axis=1)
df_merge = df_merge[df_merge['名稱_x'] != df_merge['名稱_y']].copy()
# 獲取每個樣品與其相似值最小的5個樣品
def get_top_sims(df_sub):
df_sort = df_sub.sort_values('sim').head(5)
names = ','.join(df_sort['名稱_y'])
sims = ','.join(df_sort['sim'].astype(str))
return pd.Series({'names': names, 'sims': sims})
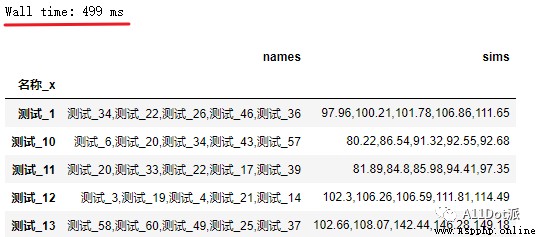
df_result = df_merge.groupby('名稱_x').apply(get_top_sims)通過復現解答大佬的代碼如上,順利返回了相似度前五的數據框。可以看到在60條數據中使用笛卡爾積進行計算,耗用時間是可以接受的。
方法二:將每一行數據與原數據直接相減,利用pandas特性求和
在方法一中能注意到數據處理上稍有繁瑣,將數據擴容再處理,且數據的差值為逐個計算。仔細理解數據,可以利用數組的廣播特性進行處理。
def get_sims(s):
# 注意:此處的df為全局變量
df_sim = (df - s).abs().sum(axis=1).round(2)
df_sim.pop(s.name)
df_sim = df_sim.sort_values(ascending=False).head(5).astype(str)
return pd.Series({'names': ','.join(df_sim.index), 'sims': ','.join(df_sim.values)})
# apply按行遍歷數據,使其他行與該行進行數據計算
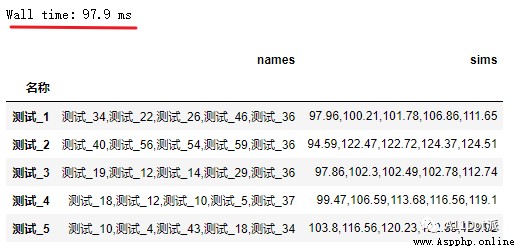
df_result = df.apply(get_sims, axis=1)使用廣播的特性將方法一中的函數優化為get_sims函數,在計算效率上也大大提高。
本文通過了解題目目的及其他解答者的想法,根據自身掌握的pandas技巧對題目進行分析處理,在一定程度上減少數據計算的冗余度,滿足數據需求,如對本文有不理解之處,盡可發言表述自己的想法。
獨樂樂不如眾樂樂。
於二零二二年六月二十一日作