最近發現周圍的很多小伙伴們都不太樂意使用pandas,轉而投向其他的數據操作庫,身為一個數據工作者,基本上是張口pandas,閉口pandas了,故而寫下此系列以讓更多的小伙伴們愛上pandas。
系列文章說明:
系列名(系列文章序號)——此次系列文章具體解決的需求
平台:
windows 10
python 3.8
pandas >=1.2.4
最近在看一本關於使用pandas進行數據處理的書,於2020年出版,其中有一段對在線零售商品的統計數據處理部分,每個訂單每個商品是單獨記錄,所以在只關心訂單時會發現有多個同樣的訂單號存在,此篇討論如何統計每月的訂單量。數據讀取如下:
import pandas as pd
df = pd.read_csv('Online_Retail.csv.zip', parse_dates=['InvoiceDate'])
df_new = df.dropna().copy()
# 拆出月份
df_new['YearMonth'] = df_new['InvoiceDate'].map(lambda x: 100 * x.year + x.month)ps: 數據獲取方式,後台回復【零售】。

(406829, 9)
由於只關心訂單號,重復的訂單號會使數據統計不准確,需要將訂單號去重後再統計。
方式一:書中使用unique後再統計。
df_new.groupby('InvoiceNo')['YearMonth'].unique().value_counts().sort_index()pandas從2020年發展至今已更新多次,此前書中方法可能無法執行,如此處會產生如下報錯,原因為unique()執行後每行數據為列表類型,value_counts不能處理。

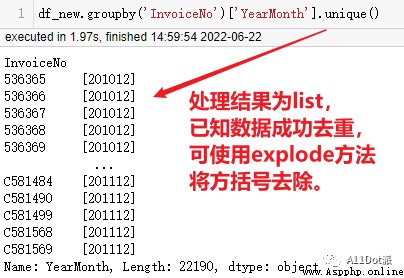
將代碼更改如下就可以完成需求。
df_new.groupby('InvoiceNo')['YearMonth'].unique().explode().value_counts().sort_index()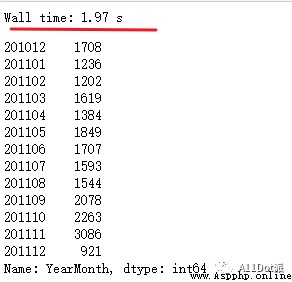
(手動水印:原創CSDN宿者朽命,https://blog.csdn.net/weixin_46281427?spm=1011.2124.3001.5343 ,公眾號A11Dot派)
方式二:對groupby結果使用value_counts去重再統計。
df_new.groupby('InvoiceNo')['YearMonth'].value_counts().reset_index(name='count')['YearMonth'].value_counts().sort_index()第一個value_counts的作用就是對YearMonth去重,需要的列名已作為索引,通過reset_index將索引重置為列數據,再對YearMonth進行value_counts統計每月的訂單量。
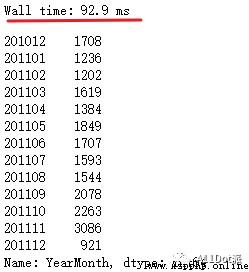
在同一台電腦上,這一方法比書中提到的方法要快,可能unique在處理上需要消耗一定時間,然而這種處理卻把思想弄復雜了,pandas去重處理可以直接使用drop_duplicates。
方式三:drop_duplicates去重後統計。
df_new[['InvoiceNo', 'YearMonth']].drop_duplicates()['YearMonth'].value_counts().sort_index()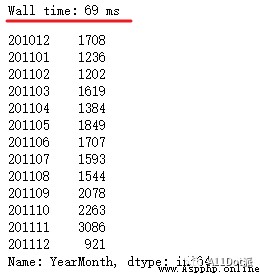
對比前兩種方法,代碼簡短了不少,處理時間也減少了。
本篇通過引入書中例子,復現書中代碼,結合現有數據處理方法,逐步優化代碼處理方式,闡述各個方法的異同點,完成數據需求。源數據可通過文章開頭處獲取。
靜觀天色,曉聽風雨。
於二零二二年六月二十二日作