一、請求對象的定制—User-Agent反爬機制
請求對象的定制:由於urlopen方法中沒有字典類型的數據存儲,所以headers不能直接存儲進去
請求對象的定制的目的:是為了解決反爬的第一種手段User-Agent.
import urllib.request
url = 'https://cn.bing.com/search?q=CSDN'
# url的組成
# http/https --> 協議
# www.baidu.com --> 主機
# 端口號--> http : 80 https : 443 mysql : 3306
# 路徑 --> search
# 參數 --> q=CSDN (?之後)
# 錨點 --> #
headers = {
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 請求對象的定制
# 由於urlopen方法中沒有字典類型的數據存儲,所以headers不能直接存儲進去
request = urllib.request.Request(url = url , headers = headers) # 此時需要指定參數名,若不指定無法做到實參與形參的一一對應
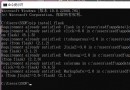
response = urllib.request.urlopen(request)
content = response.read().decode('utf8')
print(content)
二、get請求的quote方法
將 ‘周傑倫’ 轉換成unicode編碼的格式 --> 依賴於urllib.parse
import urllib.parse
# 將 周傑倫 轉換成unicode編碼的格式 --> 依賴於urllib.parse
name = urllib.parse.quote('周傑倫')
print(name)
import urllib.request
import urllib.parse
url = 'https://www.baidu.com/s?wd=' # https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 將 周傑倫 轉換成unicode編碼的格式 --> 依賴於urllib.parse
name = urllib.parse.quote('周傑倫')
print(name)
url = url + name
print(url)
#請求對象的定制
request = urllib.request.Request(url= url ,headers = headers)
response = urllib.request.urlopen(request)
content = response.read().decode()
print(content)
三、get請求的urlencode方法
import urllib.parse
data = {
'wd': '周傑倫',
'sex':'男',
'location':'中國台灣省'
}
a = urllib.parse.urlencode(data)
print(a)

步驟:
1.獲取請求資源路徑
2.請求對象的定制
3.模擬浏覽器向服務器發送請求
4.獲取網頁源碼數據
5.輸出
import urllib.parse
import urllib.request
base_url = 'https://www.baidu.com/s?'
data = {
'wd': '周傑倫',
'sex':'男',
'location':'中國台灣省'
}
new_url = urllib.parse.urlencode(data)
# 獲取請求資源路徑
url = base_url + new_url
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
# 請求對象的定制
request = urllib.request.Request(url = url , headers = headers)
# 模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(request)
# 獲取網頁源碼數據
content = response.read().decode('utf-8')
print(content)
四、post請求百度翻譯案例
# post請求
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/sug'
headers = {
'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
}
data = {
'kw' : 'spider'
}
# post請求的參數 必須進行編碼
data = urllib.parse.urlencode(data).encode('utf-8')
# post請求的參數不會拼接在url後面,而是需要放在請求對象定制的參數中
# post請求的參數必須要進行編碼
request = urllib.request.Request(url= url ,data=data,headers=headers)
# 模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(request)
# 獲取響應的數據
content = response.read().decode('utf-8')
print(content)
# post請求方式的參數必須編碼 data = urllib.parse.urlencode(data)
# 編碼之後,必須調用encode()方法 data = urllib.parse.urlencode(data).encode('utf-8')
# 參數是放在請求對象定制的方法中 request = urllib.request.Request(url= url ,data=data,headers=headers)
# 將字符串變成json對象
import json
obj = json.loads(content)
print(obj)
{
"errno":0,"data":[{
"k":"spider","v":"n. \u8718\u86db; \u661f\u5f62\u8f6e\uff0c\u5341\u5b57\u53c9; \u5e26\u67c4\u4e09\u811a\u5e73\u5e95\u9505; \u4e09\u811a\u67b6"},{
"k":"Spider","v":"[\u7535\u5f71]\u8718\u86db"},{
"k":"SPIDER","v":"abbr. SEMATECH process induced damage effect revea"},{
"k":"spiders","v":"n. \u8718\u86db( spider\u7684\u540d\u8bcd\u590d\u6570 )"},{
"k":"spidery","v":"adj. \u50cf\u8718\u86db\u817f\u4e00\u822c\u7ec6\u957f\u7684; \u8c61\u8718\u86db\u7f51\u7684\uff0c\u5341\u5206\u7cbe\u81f4\u7684"}]}
{
'errno': 0, 'data': [{
'k': 'spider', 'v': 'n. 蜘蛛; 星形輪,十字叉; 帶柄三腳平底鍋; 三腳架'}, {
'k': 'Spider', 'v': '[電影]蜘蛛'}, {
'k': 'SPIDER', 'v': 'abbr. SEMATECH process induced damage effect revea'}, {
'k': 'spiders', 'v': 'n. 蜘蛛( spider的名詞復數 )'}, {
'k': 'spidery', 'v': 'adj. 像蜘蛛腿一般細長的; 象蜘蛛網的,十分精致的'}]}
五、post請求百度詳細翻譯案例
# post請求百度詳細翻譯
import urllib.request
import urllib.parse
url = 'https://fanyi.baidu.com/v2transapi?from=en&to=zh'
headers = {
# 'user-agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44'
# 'Accept':' */*',
# # 'Accept-Encoding':' gzip, deflate, br',
# 'Accept-Language':' zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 'Acs-Token':' 1655794810538_1655870963719_doKLwiFB8fBU4raSo3DyVeE1j9Kcfar9eZ7/KCCkYi/xVTDeTcb5b1ZVsJLMLyWCRoSk7D9QXGzMwPMrG3k9/KF+lripnq/IT/lKZRFtsx2mgqAQFfmEOVpOyCMUk/ysqeKlDRLQxm9QGT+ZmbMxC8YUGkIvL2BYvUlZiUToEScm+WalBblg8MnDH6ZQdV4xk5vDhekXq2xi/5qMufx5qP0PAghdX4ubcP9wlHGUuJdRgkw+14HDZLZTNuiVAU4iP+qn59DPLkMrtA7dbX+0mgm2nU6WbWNyZDgSVGFkv1jv/09OOEiCngeNxqkpRMVrDEQY2PusrEb0aJxuyf7Ly5xbZlXqoYHAJ+cv2UYoItE=',
# 'Connection':' keep-alive',
# 'Content-Length':' 135',
# 'Content-Type':' application/x-www-form-urlencoded; charset=UTF-8',
'Cookie: BAIDUID_BFESS=4AE41A61F199E97DFDEC24D9C529DC45:FG=1; BIDUPSID=40188254DB80FE4D23CEB3A62ECAE855; PSTM=1655736944; BAIDUID=40188254DB80FE4D6469C246B7564749:FG=1; ZFY=7IyWFSZJ9Jg6dusQDydJfYyIgD9iZLLDKF:AcE24Fi94':'C; ariaDefaultTheme=undefined; RT="z=1&dm=baidu.com&si=d0sjqupvsj&ss=l4mvs3fg&sl=w&tt=evz&bcn=https%3A%2F%2Ffclog.baidu.com%2Flog%2Fweirwood%3Ftype%3Dperf&ld=9vue&ul=9ysu&hd=9yw5"; BDORZ=B490B5EBF6F3CD402E515D22BCDA1598; delPer=0; PSINO=6; H_PS_PSSID=36553_36673_36454_31253_34813_36165_36569_36074_36520_26350_36467_36311; BA_HECTOR=212k80a00580ah2h801hb4vm914; Hm_lvt_64ecd82404c51e03dc91cb9e8c025574=1655866475; APPGUIDE_10_0_2=1; REALTIME_TRANS_SWITCH=1; FANYI_WORD_SWITCH=1; HISTORY_SWITCH=1; SOUND_SPD_SWITCH=1; SOUND_PREFER_SWITCH=1; Hm_lpvt_64ecd82404c51e03dc91cb9e8c025574=1655870954; ab_sr=1.0.1_ZjcyNDAwOWM1ZGNhNTQ5YTVlZjdkMmFkZDU1MjJlZDBjOThhYzQ3OWUwZmE1N2VhNmVhNjA4MDM4Mzg4MTVmNzA3YzZjNDUxNzI5MGM1ZTNlZWM0NTQ5MzhkYzdjZDExMjgxMmRmZjRlYTdjYjAwNWJhMTVhNmVjNmI1YTZjMmE3N2MzN2M1MGZkOWU3MDMxZTViZmNiMGJkYTNkMWNiZA==',
# 'Host':' fanyi.baidu.com',
# 'Origin: https':'//fanyi.baidu.com',
# 'Referer: https':'//fanyi.baidu.com/?aldtype=16047',
# 'sec-ch-ua':' " Not A;Brand";v="99", "Chromium";v="102", "Microsoft Edge";v="102"',
# 'sec-ch-ua-mobile':' ?0',
# 'sec-ch-ua-platform':' "Windows"',
# 'Sec-Fetch-Dest':' empty',
# 'Sec-Fetch-Mode':' cors',
# 'Sec-Fetch-Site':' same-origin',
# 'User-Agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/102.0.5005.124 Safari/537.36 Edg/102.0.1245.44',
# 'X-Requested-With':' XMLHttpRequest',
}
data = {
'from' : 'en',
'to': 'zh',
'query': 'love',
'transtype': 'realtime',
'simple_means_flag': '3',
'sign': '198772.518981',
'token': 'f49e30e81d08ca57c8404ba16285a065',
'domain': 'common',
}
# post請求的參數 必須進行編碼
data = urllib.parse.urlencode(data).encode('utf-8')
# 請求對象的定制
request = urllib.request.Request(url=url,data=data,headers=headers)
# 模擬浏覽器向服務器發送請求
response = urllib.request.urlopen(request)
# 獲取響應的數據
content = response.read().decode('utf-8')
import json
obj = json.loads(content)
print(obj)