一、數據無量綱化處理 (熱力圖)
1.數據無量綱化處理(僅介紹本文用到的方法):min-max歸一化
2.代碼展示
3.效果展示
二、皮爾斯系數相關(熱力圖)
1.數學知識
2.代碼展示
3.seaborn.heatmap屬性介紹
4效果展示
總結
一、數據無量綱化處理 (熱力圖)1.數據無量綱化處理(僅介紹本文用到的方法):min-max歸一化該方法是對原始數據進行線性變換,將其映射到[0,1]之間,該方法也被稱為離差標准化。
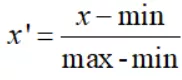
上式中,min是樣本的最小值,max是樣本的最大值。由於最大值與最小值可能是動態變化的,同時也非常容易受噪聲(異常點、離群點)影響,因此一般適合小數據的場景。此外,該方法還有兩點好處:
1) 如果某屬性/特征的方差很小,如身高:np.array([[1.70],[1.71],[1.72],[1.70],[1.73]]),實際5條數據在身高這個特征上是有差異的,但是卻很微弱,這樣不利於模型的學習,進行min-max歸一化後為:array([[ 0. ], [ 0.33333333], [ 0.66666667], [ 0. ], [ 1. ]]),相當於放大了差異;
2) 維持稀疏矩陣中為0的條目。
2.代碼展示import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as snsfrom sklearn.datasets import load_winewine = load_wine()data = wine.data # 數據lables = wine.target # 標簽feaures = wine.feature_namesdf = pd.DataFrame(data, columns=feaures) # 原始數據# 第一步:無量綱化def standareData(df): """ df : 原始數據 return : data 標准化的數據 """ data = pd.DataFrame(index=df.index) # 列名,一個新的dataframe columns = df.columns.tolist() # 將列名提取出來 for col in columns: d = df[col] max = d.max() min = d.min() mean = d.mean() data[col] = ((d - mean) / (max - min)).tolist() return data# 某一列當做參照序列,其他為對比序列def graOne(Data, m=0): """ return: """ columns = Data.columns.tolist() # 將列名提取出來 # 第一步:無量綱化 data = standareData(Data) referenceSeq = data.iloc[:, m] # 參考序列 data.drop(columns[m], axis=1, inplace=True) # 刪除參考列 compareSeq = data.iloc[:, 0:] # 對比序列 row, col = compareSeq.shape # 第二步:參考序列 - 對比序列 data_sub = np.zeros([row, col]) for i in range(col): for j in range(row): data_sub[j, i] = abs(referenceSeq[j] - compareSeq.iloc[j, i]) # 找出最大值和最小值 maxVal = np.max(data_sub) minVal = np.min(data_sub) cisi = np.zeros([row, col]) for i in range(row): for j in range(col): cisi[i, j] = (minVal + 0.5 * maxVal) / (data_sub[i, j] + 0.5 * maxVal) # 第三步:計算關聯度 result = [np.mean(cisi[:, i]) for i in range(col)] result.insert(m, 1) # 參照列為1 return pd.DataFrame(result)def GRA(Data): df = Data.copy() columns = [str(s) for s in df.columns if s not in [None]] # [1 2 ,,,12] # print(columns) df_local = pd.DataFrame(columns=columns) df.columns = columns for i in range(len(df.columns)): # 每一列都做參照序列,求關聯系數 df_local.iloc[:, i] = graOne(df, m=i)[0] df_local.index = columns return df_local# 熱力圖展示def ShowGRAHeatMap(DataFrame): colormap = plt.cm.hsv ylabels = DataFrame.columns.values.tolist() f, ax = plt.subplots(figsize=(15, 15)) ax.set_title('Wine GRA') # 設置展示一半,如果不需要注釋掉mask即可 mask = np.zeros_like(DataFrame) mask[np.triu_indices_from(mask)] = True # np.triu_indices 上三角矩陣 with sns.axes_style("white"): sns.heatmap(DataFrame, cmap="YlGnBu", annot=True, mask=mask, ) plt.show()data_wine_gra = GRA(df)ShowGRAHeatMap(data_wine_gra)3.效果展示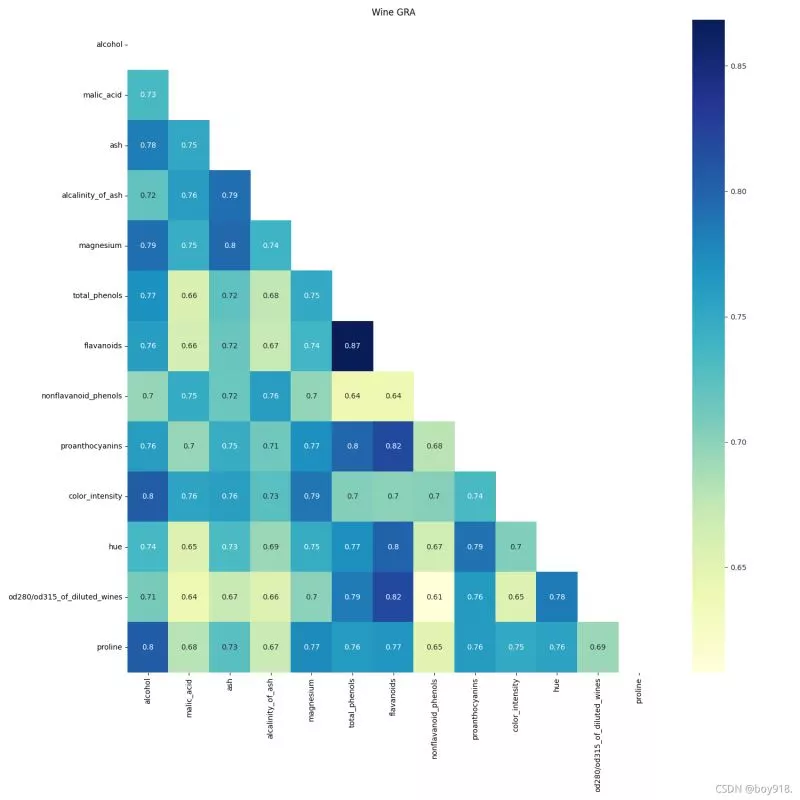
利用熱力圖可以看數據表裡多個特征兩兩的相似度。
相似度由皮爾遜相關系數度量。
兩個變量之間的皮爾遜相關系數定義為兩個變量之間的協方差和標准差的商:
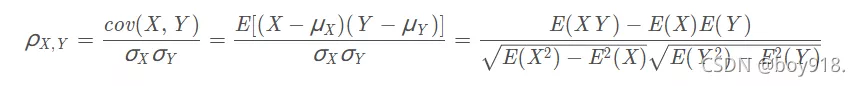
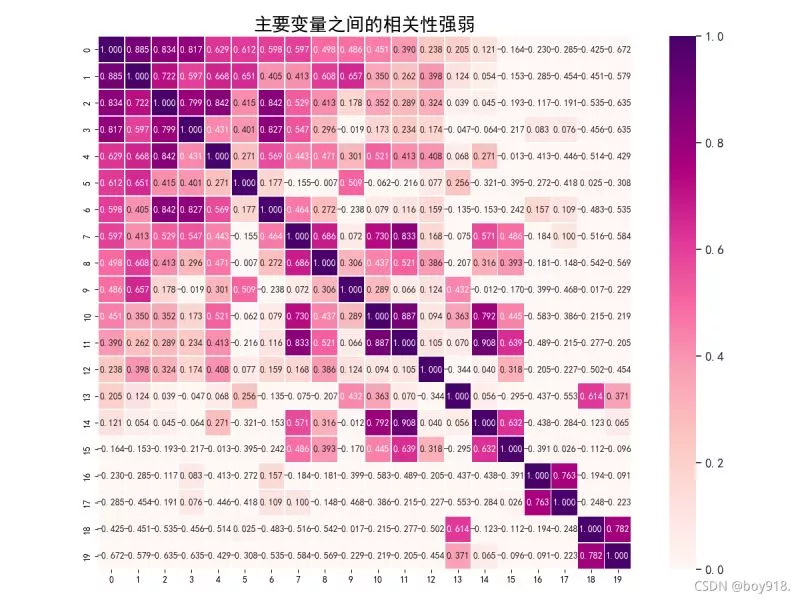
import pandas as pdimport numpy as npimport matplotlib.pyplot as pltimport seaborn as sns# ====熱力圖from matplotlib.ticker import FormatStrFormatterencoding="utf-8"data = pd.read_csv("tu.csv", encoding="utf-8") #讀取數據data.drop_duplicates()data.columns = [i for i in range(data.shape[1])]# 計算兩兩屬性之間的皮爾森相關系數corrmat = data.corr()f, ax = plt.subplots(figsize=(12, 9))# 返回按“列”降序排列的前n行k = 30cols = corrmat.nlargest(k, data.columns[0]).index# 返回皮爾遜積矩相關系數cm = np.corrcoef(data[cols].values.T)sns.set(font_scale=1.25)hm = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt=".3f", vmin=0, #刻度阈值 vmax=1, linewidths=.5, cmap="RdPu", #刻度顏色 annot_kws={"size": 10}, xticklabels=True, yticklabels=True) #seaborn.heatmap相關屬性# 解決中文顯示問題plt.rcParams['font.sans-serif'] = ['SimHei']plt.rcParams['axes.unicode_minus'] = False# plt.ylabel(fontsize=15,)# plt.xlabel(fontsize=15)plt.title("主要變量之間的相關性強弱", fontsize=20)plt.show()3.seaborn.heatmap屬性介紹1)Seaborn是基於matplotlib的Python可視化庫
seaborn.heatmap()熱力圖,用於展示一組變量的相關系數矩陣,列聯表的數據分布,通過熱力圖我們可以直觀地看到所給數值大小的差異狀況。
seaborn.heatmap(data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)2)參數輸出(均為默認值)
sns.heatmap( data, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor=‘white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels=‘auto', yticklabels=‘auto', mask=None, ax=None,)3)具體介紹
(1)熱力圖輸入數據參數4效果展示data:矩陣數據集,可以是numpy的數組(array),也可以是pandas的DataFrame。如果是DataFrame,則df的index/column信息會分別對應到heatmap的columns和rows,即df.index是熱力圖的行標,df.columns是熱力圖的列標
(2)熱力圖矩陣塊顏色參數vmax,vmin:分別是熱力圖的顏色取值最大和最小范圍,默認是根據data數據表裡的取值確定
(3)熱力圖矩陣塊注釋參數
cmap:從數字到色彩空間的映射,取值是matplotlib包裡的colormap名稱或顏色對象,或者表示顏色的列表;改參數默認值:根據center參數設定
center:數據表取值有差異時,設置熱力圖的色彩中心對齊值;通過設置center值,可以調整生成的圖像顏色的整體深淺;設置center數據時,如果有數據溢出,則手動設置的vmax、vmin會自動改變
robust:默認取值False;如果是False,且沒設定vmin和vmax的值,熱力圖的顏色映射范圍根據具有魯棒性的分位數設定,而不是用極值設定annot(annotate的縮寫):默認取值False;如果是True,在熱力圖每個方格寫入數據;如果是矩陣,在熱力圖每個方格寫入該矩陣對應位置數據
(4)熱力圖矩陣塊之間間隔及間隔線參數
fmt:字符串格式代碼,矩陣上標識數字的數據格式,比如保留小數點後幾位數字
annot_kws:默認取值False;如果是True,設置熱力圖矩陣上數字的大小顏色字體,matplotlib包text類下的字體設置;linewidths:定義熱力圖裡“表示兩兩特征關系的矩陣小塊”之間的間隔大小
(5)熱力圖顏色刻度條參數
linecolor:切分熱力圖上每個矩陣小塊的線的顏色,默認值是’white’cbar:是否在熱力圖側邊繪制顏色刻度條,默認值是True
(6)square:設置熱力圖矩陣小塊形狀,默認值是False
cbar_kws:熱力圖側邊繪制顏色刻度條時,相關字體設置,默認值是None
cbar_ax:熱力圖側邊繪制顏色刻度條時,刻度條位置設置,默認值是Nonexticklabels, yticklabels:xticklabels控制每列標簽名的輸出;yticklabels控制每行標簽名的輸出。默認值是auto。如果是True,則以DataFrame的列名作為標簽名。如果是False,則不添加行標簽名。如果是列表,則標簽名改為列表中給的內容。如果是整數K,則在圖上每隔K個標簽進行一次標注。 如果是auto,則自動選擇標簽的標注間距,將標簽名不重疊的部分(或全部)輸出
mask:控制某個矩陣塊是否顯示出來。默認值是None。如果是布爾型的DataFrame,則將DataFrame裡True的位置用白色覆蓋掉
ax:設置作圖的坐標軸,一般畫多個子圖時需要修改不同的子圖的該值
**kwargs:所有其他關鍵字參數都傳遞給 ax.pcolormesh。
到此這篇關於python熱力圖實現的文章就介紹到這了,更多相關python熱力圖實現內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!