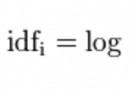I annotated his block diagram , Easy to understand , The red circle is yolo_block, The dark red annotation is the output of the previous module , Please check the code
YOLOv3 Compared with the previous yolo1 and yolo2, Great improvement , The main improvement directions are :
**1、 Residual networks are used Residual, The residual convolution is performed once 3X3 Convolution of , Then save the convolution layer, Do it again 1X1 Of convolution and once 3X3 Convolution of , And add this result to layer As a final result , The characteristic of residual network is easy to optimize , And it can improve the accuracy by increasing the depth . Its internal residual block uses jump connection , It alleviates the problem of gradient disappearance caused by increasing depth in depth neural network .
2、 Extracting multi feature layer for target detection , Three feature layers are extracted ( Pink block diagram ), its shape Respectively (13,13,75),(26,26,75),(52,52,75) The last dimension is 75 Because the graph is based on voc Data sets , Its class is 20 Kind of ,yolo3 Only exist for each feature layer 3 A priori box , So the final dimension is 3x25.
3、 It uses deconvolution UmSampling2d Design , Deconvolution is opposite to convolution in the forward and back propagation of neural network structure , It can extract more and better features **
\# l2 Regularization
def \_batch\_normalization\_layer(self, input\_layer, name = None, training = True, norm\_decay = 0.99, norm\_epsilon = 1e-3):
'''
Introduction
------------
Extracted from the convolution layer feature map Use batch normalization
Parameters
----------
input\_layer: Input four dimensions tensor
name: batchnorm The name of the layer
trainging: Is it a training process
norm\_decay: Calculate when forecasting moving average Decay rate at
norm\_epsilon: Variance plus minimal number , Prevent dividing by 0 The situation of
Returns
-------
bn\_layer: batch normalization After processing feature map
'''
bn\_layer = tf.layers.batch\_normalization(inputs = input\_layer,
momentum = norm\_decay, epsilon = norm\_epsilon, center = True,
scale = True, training = training, name = name)
return tf.nn.leaky\_relu(bn\_layer, alpha = 0.1)
\# This is used for convolution
def \_conv2d\_layer(self, inputs, filters\_num, kernel\_size, name, use\_bias = False, strides = 1):
"""
Introduction
------------
Use tf.layers.conv2d Reduce the weight and offset matrix initialization process , And the operation of adding offset term after convolution
After convolution, we need to batch norm, Finally using leaky ReLU Activation function
According to the convolution step , If the convolution step is 2, Then the image is downsampled
such as , The size of the input picture is 416\*416, The convolution kernel size is 3, if stride by 2 when ,(416 - 3 + 2)/ 2 + 1, The calculation result is 208, It is equivalent to the pool layer treatment
So you need to stride Greater than 1 When , Go ahead with one padding operation , Use all around padding One dimension replaces 'same' The way
Parameters
----------
inputs: The input variable
filters\_num: Number of convolution nuclei
strides: Convolution step
name: Convolution layer name
trainging: Is it a training process
use\_bias: Whether to use the offset term
kernel\_size: Convolution kernel size
Returns
-------
conv: After convolution feature map
"""
conv = tf.layers.conv2d(
inputs = inputs, filters = filters\_num,
kernel\_size = kernel\_size, strides = \[strides, strides\], kernel\_initializer = tf.glorot\_uniform\_initializer(),
padding = ('SAME' if strides == 1 else 'VALID'), kernel\_regularizer = tf.contrib.layers.l2\_regularizer(scale = 5e-4), use\_bias = use\_bias, name = name)
return conv
\# This is used for convolution of residuals
\# The residual convolution is performed once 3X3 Convolution of , Then save the convolution layer
\# Do it again 1X1 Of convolution and once 3X3 Convolution of , And add this result to layer As a final result
def \_Residual\_block(self, inputs, filters\_num, blocks\_num, conv\_index, training = True, norm\_decay = 0.99, norm\_epsilon = 1e-3):
"""
Introduction
------------
Darknet Residual of block, similar resnet Two layer convolution structure of , We adopt 1x1 and 3x3 Convolution kernel , Use 1x1 To reduce channel Dimensions
Parameters
----------
inputs: The input variable
filters\_num: Number of convolution nuclei
trainging: Is it a training process
blocks\_num: block The number of
conv\_index: To facilitate the loading of pre training weights , Uniformly named serial numbers
weights\_dict: Load the weight of the pre training model
norm\_decay: Calculate when forecasting moving average Decay rate at
norm\_epsilon: Variance plus minimal number , Prevent dividing by 0 The situation of
Returns
-------
inputs: The result of residual network processing
"""
# In the input feature map Length and width dimension of padding
inputs = tf.pad(inputs, paddings=\[\[0, 0\], \[1, 0\], \[1, 0\], \[0, 0\]\], mode='CONSTANT')
layer = self.\_conv2d\_layer(inputs, filters\_num, kernel\_size = 3, strides = 2, name = "conv2d\_" + str(conv\_index))
layer = self.\_batch\_normalization\_layer(layer, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
for \_ in range(blocks\_num):
shortcut = layer
layer = self.\_conv2d\_layer(layer, filters\_num // 2, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index))
layer = self.\_batch\_normalization\_layer(layer, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
layer = self.\_conv2d\_layer(layer, filters\_num, kernel\_size = 3, strides = 1, name = "conv2d\_" + str(conv\_index))
layer = self.\_batch\_normalization\_layer(layer, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
layer += shortcut
return layer, conv\_index
#---------------------------------------#
\# Generate \_darknet53 And reverse convolution
#---------------------------------------#
def \_darknet53(self, inputs, conv\_index, training = True, norm\_decay = 0.99, norm\_epsilon = 1e-3):
"""
Introduction
------------
structure yolo3 The use of darknet53 Network structure
Parameters
----------
inputs: Model input variables
conv\_index: Convolution layer No , Easy to load pre training weights by name
weights\_dict: Pre training weights
training: Is it training
norm\_decay: Calculate when forecasting moving average Decay rate at
norm\_epsilon: Variance plus minimal number , Prevent dividing by 0 The situation of
Returns
-------
conv: after 52 The result of layer convolution calculation , Enter the picture as 416x416x3, Then the output result at this time shape by 13x13x1024
route1: Back to page 26 Layer convolution calculation results 52x52x256, For subsequent use
route2: Back to page 43 Layer convolution calculation results 26x26x512, For subsequent use
conv\_index: Convolution layer count , It is convenient to use when loading the pre training model
"""
with tf.variable\_scope('darknet53'):
# 416,416,3 -> 416,416,32
conv = self.\_conv2d\_layer(inputs, filters\_num = 32, kernel\_size = 3, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
# 416,416,32 -> 208,208,64
conv, conv\_index = self.\_Residual\_block(conv, conv\_index = conv\_index, filters\_num = 64, blocks\_num = 1, training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
# 208,208,64 -> 104,104,128
conv, conv\_index = self.\_Residual\_block(conv, conv\_index = conv\_index, filters\_num = 128, blocks\_num = 2, training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
# 104,104,128 -> 52,52,256
conv, conv\_index = self.\_Residual\_block(conv, conv\_index = conv\_index, filters\_num = 256, blocks\_num = 8, training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
# route1 = 52,52,256
route1 = conv
# 52,52,256 -> 26,26,512
conv, conv\_index = self.\_Residual\_block(conv, conv\_index = conv\_index, filters\_num = 512, blocks\_num = 8, training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
# route2 = 26,26,512
route2 = conv
# 26,26,512 -> 13,13,1024
conv, conv\_index = self.\_Residual\_block(conv, conv\_index = conv\_index, filters\_num = 1024, blocks\_num = 4, training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
# route3 = 13,13,1024
return route1, route2, conv, conv\_index
\# Output two network results
\# The first is to 5 After sub convolution , For the next deconvolution , The convolution process is 1X1,3X3,1X1,3X3,1X1
\# The second is to 5+2 Sub convolution , As a feature layer , The convolution process is 1X1,3X3,1X1,3X3,1X1,3X3,1X1
def \_yolo\_block(self, inputs, filters\_num, out\_filters, conv\_index, training = True, norm\_decay = 0.99, norm\_epsilon = 1e-3):
"""
Introduction
------------
yolo3 stay Darknet53 Based on the extracted feature layer , Also added for 3 In different proportions feature map Of block, This can improve the detection rate of small objects
Parameters
----------
inputs: Input characteristics
filters\_num: Number of convolution nuclei
out\_filters: The number of convolution kernels of the final output layer
conv\_index: Convolution layer No , Easy to load pre training weights by name
training: Is it training
norm\_decay: Calculate when forecasting moving average Decay rate at
norm\_epsilon: Variance plus minimal number , Prevent dividing by 0 The situation of
Returns
-------
route: Returns the previous result of the last convolution layer
conv: Returns the result of the last layer of convolution
conv\_index: conv Layer count
"""
conv = self.\_conv2d\_layer(inputs, filters\_num = filters\_num, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
conv = self.\_conv2d\_layer(conv, filters\_num = filters\_num \* 2, kernel\_size = 3, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
conv = self.\_conv2d\_layer(conv, filters\_num = filters\_num, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
conv = self.\_conv2d\_layer(conv, filters\_num = filters\_num \* 2, kernel\_size = 3, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
conv = self.\_conv2d\_layer(conv, filters\_num = filters\_num, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
route = conv
conv = self.\_conv2d\_layer(conv, filters\_num = filters\_num \* 2, kernel\_size = 3, strides = 1, name = "conv2d\_" + str(conv\_index))
conv = self.\_batch\_normalization\_layer(conv, name = "batch\_normalization\_" + str(conv\_index), training = training, norm\_decay = norm\_decay, norm\_epsilon = norm\_epsilon)
conv\_index += 1
conv = self.\_conv2d\_layer(conv, filters\_num = out\_filters, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index), use\_bias = True)
conv\_index += 1
return route, conv, conv\_index
\# Return the contents of the three feature layers
def yolo\_inference(self, inputs, num\_anchors, num\_classes, training = True):
"""
Introduction
------------
structure yolo Model structure
Parameters
----------
inputs: Input variables of the model
num\_anchors: Every grid cell Responsible for testing anchor Number
num\_classes: Number of categories
training: Whether it is training mode
"""
conv\_index = 1
# route1 = 52,52,256、route2 = 26,26,512、route3 = 13,13,1024
conv2d\_26, conv2d\_43, conv, conv\_index = self.\_darknet53(inputs, conv\_index, training = training, norm\_decay = self.norm\_decay, norm\_epsilon = self.norm\_epsilon)
with tf.variable\_scope('yolo'):
#--------------------------------------#
# Get the first feature layer :conv2d\_59
#--------------------------------------#
# conv2d\_57 = 13,13,512,conv2d\_59 = 13,13,255(3x(80+5))
conv2d\_57, conv2d\_59, conv\_index = self.\_yolo\_block(conv, 512, num\_anchors \* (num\_classes + 5), conv\_index = conv\_index, training = training, norm\_decay = self.norm\_decay, norm\_epsilon = self.norm\_epsilon)
#--------------------------------------#
# Get the second feature layer :conv2d\_67
#--------------------------------------#
conv2d\_60 = self.\_conv2d\_layer(conv2d\_57, filters\_num = 256, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index))
conv2d\_60 = self.\_batch\_normalization\_layer(conv2d\_60, name = "batch\_normalization\_" + str(conv\_index),training = training, norm\_decay = self.norm\_decay, norm\_epsilon = self.norm\_epsilon)
conv\_index += 1
# unSample\_0 = 26,26,256
unSample\_0 = tf.image.resize\_nearest\_neighbor(conv2d\_60, \[2 \* tf.shape(conv2d\_60)\[1\], 2 \* tf.shape(conv2d\_60)\[1\]\], name='upSample\_0')
# route0 = 26,26,768
route0 = tf.concat(\[unSample\_0, conv2d\_43\], axis = -1, name = 'route\_0')
# conv2d\_65 = 52,52,256,conv2d\_67 = 26,26,255
conv2d\_65, conv2d\_67, conv\_index = self.\_yolo\_block(route0, 256, num\_anchors \* (num\_classes + 5), conv\_index = conv\_index, training = training, norm\_decay = self.norm\_decay, norm\_epsilon = self.norm\_epsilon)
#--------------------------------------#
# Get the third feature layer :conv2d\_75
#--------------------------------------#
conv2d\_68 = self.\_conv2d\_layer(conv2d\_65, filters\_num = 128, kernel\_size = 1, strides = 1, name = "conv2d\_" + str(conv\_index))
conv2d\_68 = self.\_batch\_normalization\_layer(conv2d\_68, name = "batch\_normalization\_" + str(conv\_index), training=training, norm\_decay=self.norm\_decay, norm\_epsilon = self.norm\_epsilon)
conv\_index += 1
# unSample\_1 = 52,52,128
unSample\_1 = tf.image.resize\_nearest\_neighbor(conv2d\_68, \[2 \* tf.shape(conv2d\_68)\[1\], 2 \* tf.shape(conv2d\_68)\[1\]\], name='upSample\_1')
# route1= 52,52,384
route1 = tf.concat(\[unSample\_1, conv2d\_26\], axis = -1, name = 'route\_1')
# conv2d\_75 = 52,52,255
\_, conv2d\_75, \_ = self.\_yolo\_block(route1, 128, num\_anchors \* (num\_classes + 5), conv\_index = conv\_index, training = training, norm\_decay = self.norm\_decay, norm\_epsilon = self.norm\_epsilon)
return \[conv2d\_59, conv2d\_67, conv2d\_75\]