Preface
--
In short, the Internet is a large network composed of sites and network devices , We visit the site through a browser , The site HTML、JS、CSS Code back to browser , The code is parsed by the browser 、 Rendering , Present us with colorful web pages ;
One 、 What is a reptile ?
If we compare the Internet to a big spider web , Data is stored in each node of the spider web , And a reptile is a little spider ,
Grab your prey along the Internet ( data ) A reptile means : Make a request to the website , A program that analyzes and extracts useful data after obtaining resources ;
Technically speaking, it's Through the program simulation browser request site behavior , Return the site to HTML Code /JSON data / binary data ( picture 、 video ) Climb to the local , Then extract the data you need , Store and use ;
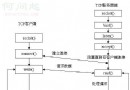
Two 、 Basic process of reptile :
How users access network data :
The way 1: Browser submit request ---> Download Web code ---> Parse to page
The way 2: Impersonate a browser to send a request ( Get web code )-> Extract useful data -> Stored in a database or file
What a reptile has to do is the way 2;
1、 Initiate request
Use http The library makes a request to the target site , Send a Request
Request contain : Request header 、 Requester, etc
Request Module defect : Cannot perform JS and CSS Code
2、 Get response content
If the server can respond normally , You get a Response
Response contain :html,json, picture , Video etc.
3、 Parsing content
analysis html data : Regular expressions (RE modular ), The third-party parsing library is as follows Beautifulsoup,pyquery etc.
analysis json data :json modular
Parse binary data : With wb Write to a file
4、 Save the data
database (MySQL,Mongdb、Redis)
file
3、 ... and 、http agreement Request and response
Request: Users will be their own information through the browser (socket client) Send to the server (socket server)
Response: Server receives request , Analyze the request information sent by users , Then return the data ( The returned data may contain other links , Such as : picture ,js,css etc. )
ps: The browser is receiving Response after , The content will be parsed to show the user , And the crawler sends the request in the simulation browser and then receives Response after , To extract useful data .
Four 、 request
1、 Request mode :
Common request methods :GET / POST
2、 Requested URL
url Global resource locator , Used to define a unique resource on the Internet for example : A picture 、 A file 、 A video can be used url Sole determination
url code
https://www.baidu.com/s?wd= picture
The picture will be encoded ( Look at the sample code )
The loading process of the web page is :
Load a web page , Usually load first document file ,
In parsing document When documenting , Encounter Links , Then the request to download the picture is initiated for the hyperlink
3、 Request header
User-agent: If there is no user-agent Client configuration , The server may regard you as an illegal user host;
cookies:cookie Used to save login information
Be careful : Generally, a reptile will add a request header
Parameters that the request header needs to be aware of :
(1)Referrer: Where is the source of the visit ( Some large websites , Will pass Referrer Do anti-theft chain strategy ; All reptiles should also pay attention to simulation )
(2)User-Agent: Visit the browser ( Add it or it will be treated as a crawler )
(3)cookie: Ask the head to take care of
4、 Request body
Request body If it is get The way , The request body has no content (get The request body of the request is placed in url In the following parameters , Can see directly ) If it is post The way , The body of the request is format data ps: 1、 Login window , File upload, etc , Information is attached to the request body 2、 Sign in , Enter the wrong username and password , And then submit , You can see that post, When you log in correctly, the page will usually jump , Can't capture post
5、 ... and 、 Respond to Response
1、 Response status code
200: On behalf of success
301: For jump
404: file does not exist
403: No access to
502: Server error
2、respone header
Parameters to be noted in response header :
(1)Set-Cookie:BDSVRTM=0; path=/: There may be more than one , To tell the browser , hold cookie preserved
(2)Content-Location: The server response header contains Location After returning to the browser , The browser will revisit another page
3、preview It's web source code
JSO data
Such as web page html, picture
Binary data, etc
6、 ... and 、 summary
1、 Summarize the reptile process :
Crawling ---> analysis ---> Storage
2、 Tools for reptiles :
Request Library :requests,selenium( It can drive the browser to parse and render CSS and JS, But there are performance disadvantages ( Useful and useless pages will be loaded );)
Parsing library : Regular ,beautifulsoup,pyquery
The repository : file ,MySQL,Mongodb,Redis
3、 Climb the school flower net
Basic Edition :
import re
import requests
respose\=requests.get('http://www.xiaohuar.com/v/')
# print(respose.status\_code)# The status code of the response
# print(respose.content) # Return byte information
# print(respose.text) # Return text content
urls=re.findall(r'class="items".\*?href="(.\*?)"',respose.text,re.S) #re.S Convert text information into 1 Line matching
url=urls\[5\]
result\=requests.get(url)
mp4\_url\=re.findall(r'id="media".\*?src="(.\*?)"',result.text,re.S)\[0\]
video\=requests.get(mp4\_url)
with open('D:\\\\a.mp4','wb') as f:
f.write(video.content)View Code
Function encapsulation
import re
import requests
import hashlib
import time
# respose=requests.get('http://www.xiaohuar.com/v/')
# # print(respose.status\_code)# The status code of the response
# # print(respose.content) # Return byte information
# # print(respose.text) # Return text content
# urls=re.findall(r'class="items".\*?href="(.\*?)"',respose.text,re.S) #re.S Convert text information into 1 Line matching
# url=urls\[5\]
# result=requests.get(url)
# mp4\_url=re.findall(r'id="media".\*?src="(.\*?)"',result.text,re.S)\[0\]
#
# video=requests.get(mp4\_url)
#
# with open('D:\\\\a.mp4','wb') as f:
# f.write(video.content)
#
def get\_index(url):
respose \= requests.get(url)
if respose.status\_code==200:
return respose.text
def parse\_index(res):
urls \= re.findall(r'class="items".\*?href="(.\*?)"', res,re.S) # re.S Convert text information into 1 Line matching
return urls
def get\_detail(urls):
for url in urls:
if not url.startswith('http'):
url\='http://www.xiaohuar.com%s' %url
result \= requests.get(url)
if result.status\_code==200 :
mp4\_url\_list \= re.findall(r'id="media".\*?src="(.\*?)"', result.text, re.S)
if mp4\_url\_list:
mp4\_url\=mp4\_url\_list\[0\]
print(mp4\_url)
# save(mp4\_url)
def save(url):
video \= requests.get(url)
if video.status\_code==200:
m\=hashlib.md5()
m.updata(url.encode('utf-8'))
m.updata(str(time.time()).encode('utf-8'))
filename\=r'%s.mp4'% m.hexdigest()
filepath\=r'D:\\\\%s'%filename
with open(filepath, 'wb') as f:
f.write(video.content)
def main():
for i in range(5):
res1 \= get\_index('http://www.xiaohuar.com/list-3-%s.html'% i )
res2 \= parse\_index(res1)
get\_detail(res2)
if \_\_name\_\_ == '\_\_main\_\_':
main()View Code
Concurrent Version ( If there is a total need to climb 30 A video , open 30 A thread to do , The time it takes is The slowest part of it takes time )
import re
import requests
import hashlib
import time
from concurrent.futures import ThreadPoolExecutor
p\=ThreadPoolExecutor(30) # establish 1 In the process pool , The number of threads to be accommodated is 30 individual ;
def get\_index(url):
respose \= requests.get(url)
if respose.status\_code==200:
return respose.text
def parse\_index(res):
res\=res.result() # After the process is executed , obtain 1 Objects
urls = re.findall(r'class="items".\*?href="(.\*?)"', res,re.S) # re.S Convert text information into 1 Line matching
for url in urls:
p.submit(get\_detail(url)) # For details page Commit to thread pool
def get\_detail(url): # Only download 1 A video
if not url.startswith('http'):
url\='http://www.xiaohuar.com%s' %url
result \= requests.get(url)
if result.status\_code==200 :
mp4\_url\_list \= re.findall(r'id="media".\*?src="(.\*?)"', result.text, re.S)
if mp4\_url\_list:
mp4\_url\=mp4\_url\_list\[0\]
print(mp4\_url)
# save(mp4\_url)
def save(url):
video \= requests.get(url)
if video.status\_code==200:
m\=hashlib.md5()
m.updata(url.encode('utf-8'))
m.updata(str(time.time()).encode('utf-8'))
filename\=r'%s.mp4'% m.hexdigest()
filepath\=r'D:\\\\%s'%filename
with open(filepath, 'wb') as f:
f.write(video.content)
def main():
for i in range(5):
p.submit(get\_index,'http://www.xiaohuar.com/list-3-%s.html'% i ).add\_done\_callback(parse\_index)
#1、 Let's start with the task of climbing the home page (get\_index) Asynchronously commit to the thread pool
#2、get\_index After the mission is completed , Through the callback letter add\_done\_callback() Number notifies the main thread , Task to complete ;
#2、 hold get\_index Execution results ( Note that the thread execution result is an object , call res=res.result() Method , To get the real execution results ), As a parameter to parse\_index
#3、parse\_index After the task is completed ,
#4、 Through the loop , Put the get details page again get\_detail() The task is submitted to the thread pool for execution
if \_\_name\_\_ == '\_\_main\_\_':
main()View Code
Related to knowledge : Multithreading, multiprocessing
Compute intensive tasks : Using multiple processes , Because it can Python Yes GIL, Multiple processes can take advantage of CPU Multi core advantage ;
IO Intensive task : Using multithreading , do IO Switching saves task execution time ( Concurrent )
Thread pool