DataFrame.drop_duplicates(self, subset=None, keep='first', inplace=False)[source]
一共有三個參數,subset、keep和inplace
subset : column label or sequence of labels, optional
Only consider certain columns for identifying duplicates, by default use all of the columns
subset參數用來設置以哪些列的重復作為重復的標准,參數為列標簽,如果不設置該值,則默認為以所有列作為重復的判斷條件。
keep : {
‘first’, ‘last’, False}, default ‘first’
first : Drop duplicates except for the first occurrence.
last : Drop duplicates except for the last occurrence.
False : Drop all duplicates.
keep可以設置為三個參數,默認為first
first表示保留第一次出現的記錄
last表示保留最後一次出現的記錄
False表示把所有重復的刪除
inplace : boolean, default False
Whether to drop duplicates in place or to return a copy
inplace可以設置為True或False,默認為False
True表示原地去重,會改變dataframe
False表示會返回一個新的dataframe,不會改變原來的變量
import pandas as pd
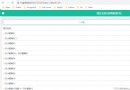
data = pd.DataFrame([[1, 'Wang', 20], [2, 'Li', 20], [1, 'Wang', 21], [1, 'Wang', 20]], columns=['id', 'name', 'age'])
數據為
id name age
0 1 Wang 20
1 2 Li 20
2 1 Wang 21
3 1 Wang 20
很顯然第0條和第3條記錄重復,使用默認用法即可去除
print(data.drop_duplicates())
結果是
id name age
0 1 Wang 20
1 2 Li 20
2 1 Wang 21
很顯然是保留了第0條記錄,而去除了第3條記錄,可通過設置keep參數為last使其保留後一條參數
print(data.drop_duplicates(keep='last'))
結果是
id name age
1 2 Li 20
2 1 Wang 21
3 1 Wang 20
同時對於數據集
id name age
0 1 Wang 20
1 2 Li 20
2 1 Wang 21
3 1 Wang 20
認為id和name相同即為重復的話,可以使用
print(data.drop_duplicates(['id', 'name']))
得到
id name age
0 1 Wang 20
1 2 Li 20
如果想把重復的數據都刪除,則使用
print(data.drop_duplicates(['id', 'name'], keep=False))
得到
id name age
1 2 Li 20