這個姿勢筆記,比較雜亂,記錄學習過程的。
第7章。數據清洗
"""
Series的map方法可以接受一個函數或含有映射關系的字典型對象,
使用map是一種實現元素級轉換以及其他數據清理工作的便捷方式。
map 是一個常用的函數,可以使用它,對變量重新賦值,比如這樣的。
"""
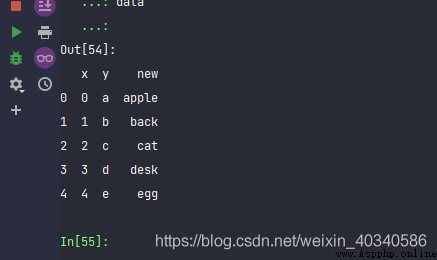
data = pd.DataFrame({'x':range(5), 'y':list('abcde')})
data
char2word = {
'a':'apple',
'b':'back',
'c':'cat',
'd':'desk',
'e':'egg'
}
data['new'] = data['y'].map(char2word)
data可以得到。
'''
lower 和 title 可以大小寫
'''
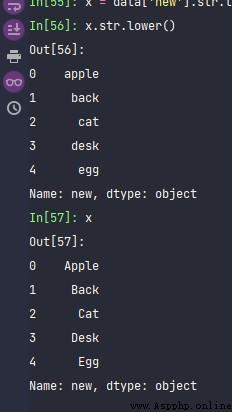
x = data['new'].str.title()
x.str.lower()
######################### ############ replace #########################
data = pd.Series([1., -999., 2., -999., -1000., 3.])
data
import numpy as np
data.replace(-999, np.nan)
data.replace([-999, -1000], np.nan)
data.replace([-999, -1000], [np.nan, 0])
data.replace({-999: np.nan, -1000: 0})
'''
replace 接受 單個值,列表, 字典,那麼這樣接受不?
'''
'''
data
data.replace([{-999, 2:0}, 3:333])
data.replace([[-999,3], 2], [np.nan, 0])
### 這樣不行data.map({-999:2})
dat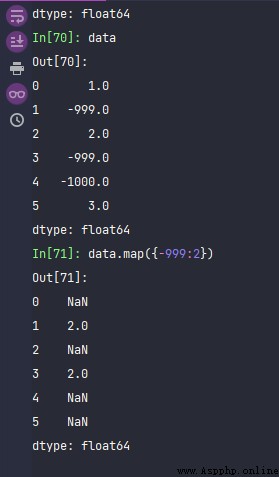
如果用replace, 那麼沒有對應值的就會被替換成缺失值。
data.map({'-999':np.nan})
結果就會全都是缺失值,因為其他的也是沒有對應,都變成缺失。
rename 方法。
########################
########### 重命名 軸索引
########################
data = pd.DataFrame(np.arange(12).reshape((3, 4)),
index=['Ohio', 'Colorado', 'New York'],
columns=['one', 'two', 'three', 'four'])
data
transfom = lambda x: x[:4].upper()
'''
這個函數可以取單詞的前4個字母,然後轉換成大寫。
'''
data.index.map(transfom)
'''
transorm是一個函數。
'''
data.index = data.index.map(transfom)
data
data.rename(index=str.title, columns=str.upper)
#### 可以這樣直接寫,挺方便的。
# 比如
frame = pd.DataFrame(np.arange(12).reshape(3, 4),
index = ['apple', 'basketboall', 'celebrate'],
columns = ['xmanufact', 'killing', 'zicker', 'tankre'])
frame
'''
這裡又一個 range的坑
'''
np.arange(12).reshape(3, 4)
np.asarray(range(12)).reshape(3, 4) # 這樣才行。
range(12).reshape(3, 4) # 這裡用range 就會報錯,因為,range不會產生 array, np.arange,才會產生有結構的sarray
#繼續
transfom
frame.index.map(transfom)
frame.index = frame.index.map(transfom)
frame
frame
"""
這裡 frame 已經修改了,
如果想要創建數據集的轉換版(而不是修改原始數據),比較實用的方法是 rename:
書中說,
"""
frame.rename(index = str.title, columns = str.upper)
############特別說明一下,rename可以結合字典型對象實現對部分軸標簽的更新:
frame
frame.rename(index = {'APPL':'huawei'}, columns = {'killing':'bill'})
data.rename(
index={'OHIO': "INDIANA"},
columns={'three': 'peekaboo'}
)
data
data.rename(index={'OHIO': "INDIANA"}, columns={'three': 'peekaboo'}, inplace=True)
data
'''
這裡的rename 的方法很有趣, 可以直接接受一個 mapper, 像這樣的,frame.rename(index = str.title, columns = str.upper)
就是制定, 行的索引,按照字符串處理, 都變成大寫的。列的索引都按照字符串處理,都變成大寫的。
'''
然後是離散化方法, 就是使用cut
cut函數,
###########################################
################## 7.2 離散化和面元劃分
###########################################
ages = [20, 22, 25, 27, 21, 23, 37, 31, 61, 45, 41, 32]
ages
bins = [18, 25, 35, 60, 100]
cats = pd.cut(ages, bins)
'''44
pandas返回的是一個特殊的Categorical對象。結
它的底層含有一個表示不同分類名稱 的類型數組,以及一個codes屬性中的年齡數據的標簽
'''
# cats
cats.codes
cats.categories
# cats
# cats.keys()
# cats
# type(cats)
# pd.cut()
# cats.categories
# cats
# cats.Length
# cats.tolist()
# cats.ordered
pd.value_counts(cats)
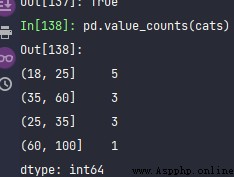
這個比較簡單,可以再加一個 labels選項。也可以不加。
############### 過濾異常值
'''
7.2 檢測和過濾異常值
'''
data = pd.DataFrame(np.random.randn(1000, 4))
data.describe()
col = data[2]
col
col[np.abs(col) > 3]
data
data.head()
data.columnnames =['a', 'b', 'c', 'd']
###################
# columnnames 不會改變列的名字, 那會改變什麼呢?
data
data.columns = ['a', 'b', 'c', 'd']
data[data['a'] > 3].idxmax()
data['a'] > 3
data[data['a'] > 3]
c = data['c']
c.idxmax()
c
data['c'].nlargest()
c.argmax(2)
np.argpartition(c, )
x = np.array([4, 3, 2, 1])
np.argpartition(x, 3)[0]
np.argpartition(x, 3)
np.argpartition(x,3)
np.argpartition(x,2)
np.argpartition(x,5)
np.argwhere(x, 3)
data[(np.abs(data)> 3).any(1)]
data[data>3].any(1)
(data>3).any(1)
######################### 看來必須用上面的方式寫,
data[(data>3.5).any(1)]