一、全部代碼展示
二、解釋
1.with closing
with用法(實現上下文管理)
closing用法(完美解決上述問題)
2.文件流stream
3.response.headers['content-length']
4.response.iter_content()
5.\r和%
三、結果展示
四、總結
前言:
在爬取並下載網頁上的視頻的時候,我們需要實時進度條,這可以幫助我們更直觀的看到視頻的下載進度。
一、全部代碼展示from contextlib import closingfrom requests import geturl = 'https://v26-web.douyinvod.com/57cdd29ee3a718825bf7b1b14d63955b/615d475f/video/tos/cn/tos-cn-ve-15/72c47fb481464cfda3d415b9759aade7/?a=6383&br=2192&bt=2192&cd=0%7C0%7C0&ch=26&cr=0&cs=0&cv=1&dr=0&ds=4&er=&ft=jal9wj--bz7ThWG4S1ct&l=021633499366600fdbddc0200fff0030a92169a000000490f5507&lr=all&mime_type=video_mp4&net=0&pl=0&qs=0&rc=ank7OzU6ZnRkNjMzNGkzM0ApNmY4aGU8MzwzNzo3ZjNpZWdiYXBtcjQwLXNgLS1kLTBzczYtNS0tMmE1Xi82Yy9gLTE6Yw%3D%3D&vl=&vr='with closing(get(url, stream=True)) as response: chunk_size = 1024 # 單次請求最大值 # response.headers['content-length']得到的數據類型是str而不是int content_size = int(response.headers['content-length']) # 文件總大小 data_count = 0 # 當前已傳輸的大小 with open('文件名.mp4', "wb") as file: for data in response.iter_content(chunk_size=chunk_size): file.write(data) done_block = int((data_count / content_size) * 50) # 已經下載的文件大小 data_count = data_count + len(data) # 實時進度條進度 now_jd = (data_count / content_size) * 100 # %% 表示% print("\r [%s%s] %d%% " % (done_block * '█', ' ' * (50 - 1 - done_block), now_jd), end=" ")注:上面的url已過期,需要各位自己去找網頁上的視頻url
二、解釋1.with closing我們在日常讀取文件資源時,經常會用到with open() as f:的句子。
但是使用with語句的時候是需要條件的,任何對象,只要正確實現了上下文管理,就可以使用with語句,實現上下文管理是通過__enter__和__exit__這兩個方法實現的。
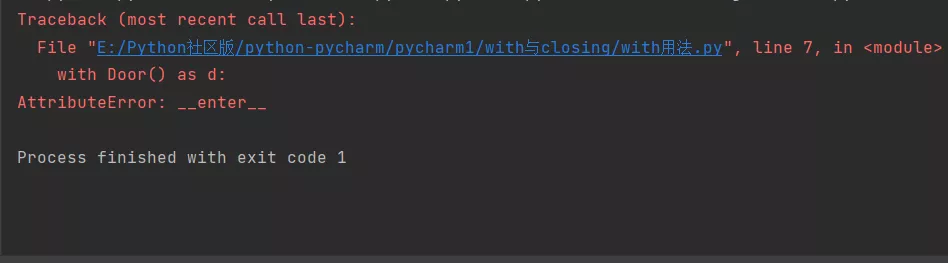
with用法(沒有實現上下文管理)
class Door(): def open(self): print('Door is opened') def close(self): print('Door is closed')with Door() as d: d.open() d.close()結果報錯了:
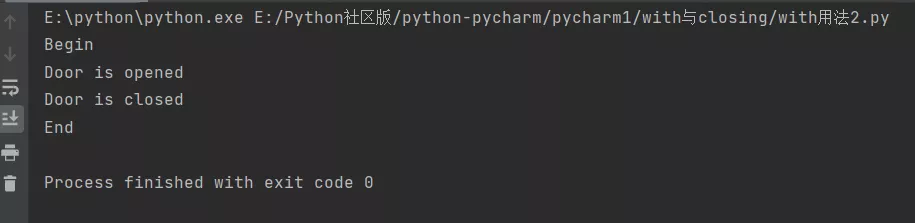
用__enter__和__exit__實現了上下文管理
class Door(): def open(self): print('Door is opened') def close(self): print('Door is closed')with Door() as d: d.open() d.close()結果沒報錯:
一個對象沒有實現上下文,我們就不能把它用於with語句。這個時候,可以用contextlib中的
closing()來把該對象變為上下文對象。
class Door(): def __enter__(self): print('Begin') return self def __exit__(self, exc_type, exc_value, traceback): if exc_type: print('Error') else: print('End') def open(self): print('Door is opened') def close(self): print('Door is closed')with Door() as d: d.open() d.close()例如:用with語句使用requests中的get(url)
也就是本文中的案例,使用with closing()下載視頻(在網頁中)
2.文件流stream想象一下,如果把文件讀取比作向池子裡抽水,同步會阻塞程序,異步會等待結果,如果池子非常大呢?
因此有了文件流,它就好比你一邊抽一邊取,不用等池子滿了再用,
所以對於一些大型文件(幾個G的視頻)一般會用到這個參數。(對小型文件也可以使用)
3.response.headers['content-length']這表示獲取文件的總大小,但是它得到的結果的數據類型是str而不是int,因此需要進行數據類型轉換。
4.response.iter_content()該方法一般用於從網上下載文件和網頁(需要用到requests.get(url))
其中chunk_size表示單次請求最大值。
5.\r和%\r表示回車(回到行首)
%是一種占位符
而對於%%,第一個%起到了轉義的作用,使結果輸出為百分號%
三、結果展示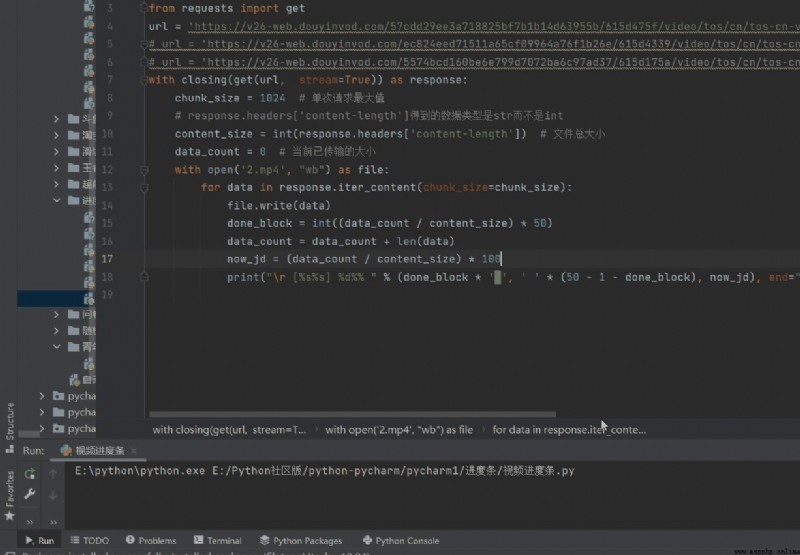
我之前看了許多的進度條,這些進度條都能動,但是滿足不了根據文件內容進行加載(裡面的參數要麼都定死了,要麼就與文件大小無關),不能做到真正的交互功能,這次的進度條就很好的展示了,大家可以去試試!!
這次下載視頻展示進度條是爭對一個url,大家可以將它加到你的爬蟲的循環中,這樣就能在爬每個視頻的時候展示實時進度條了!!
到此這篇關於如何實現python爬蟲爬取視頻時實現實時進度條顯示的文章就介紹到這了,更多相關python爬取顯示進度條內容請搜索軟件開發網以前的文章或繼續浏覽下面的相關文章希望大家以後多多支持軟件開發網!