數據集:diabetes.csv
參考書:《Machine Learning Mastery With Python Understand Your Data, Create Accurate Models and work Projects End-to-End》
獲取鏈接:https://github.com/aoyinke/ML_learner
from pandas import read_csv
path = "diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path,names=names,skiprows=1)
# 觀察數據的前5行
print(data.head())
# 觀察數據的維度
print(data.shape)
"""
preg plas pres skin test mass pedi age class
0 6 148 72 35 0 33.6 0.627 50 1
1 1 85 66 29 0 26.6 0.351 31 0
2 8 183 64 0 0 23.3 0.672 32 1
3 1 89 66 23 94 28.1 0.167 21 0
4 0 137 40 35 168 43.1 2.288 33 1
(768, 9) 768行,9列
"""
# 觀測每種數據的類型
print(types)
"""
preg int64
plas int64
pres int64
skin int64
test int64
mass float64
pedi float64
age int64
class int64
"""
from pandas import set_option
set_option('display.width', 100)
set_option('precision', 3)
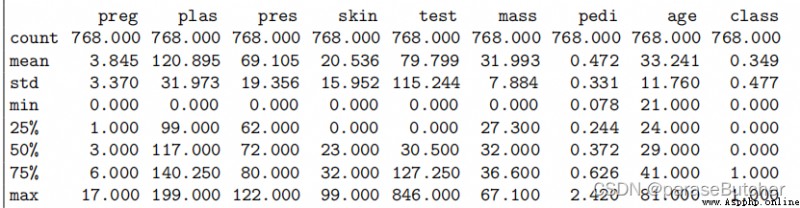
description = data.describe()
print(description)
class_counts = data.groupby('class').size()
print(class_counts)
"""
class
0 500
1 268
"""
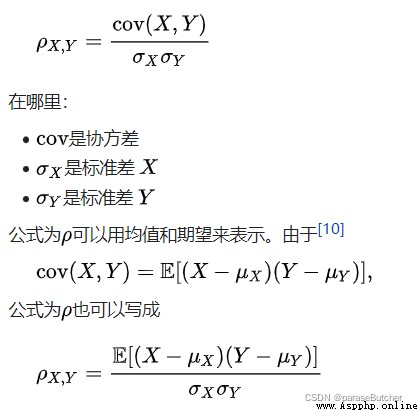
from pandas import set_option,read_csv
data = read_csv(filename, names=names)
set_option('display.width', 100)
set_option('precision', 3)
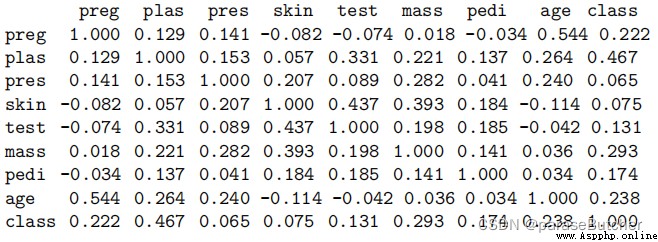
correlations = data.corr(method='pearson')
print(correlations)
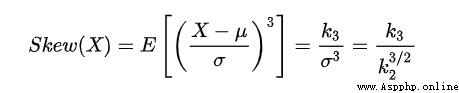
公式中,Sk——偏度;E——期望;μ——平均值;μ3——3階中心矩;σ——標准差。 在一般情形下,當統計數據為右偏分布時,Sk>0,且Sk值越大,右偏程度越高;
當統計數據為左偏分布時,Sk< 0,且Sk值越小,左偏程度越高。當統計數據為對稱分布時,顯然有Sk= 0。
所以我們應該注意處理skew較大(絕對值)的變量
skew = data.skew()
print(skew)
"""
preg 0.901674
plas 0.173754
pres -1.843608
skin 0.109372
test 2.272251
mass -0.428982
pedi 1.919911
age 1.129597
class 0.635017
"""
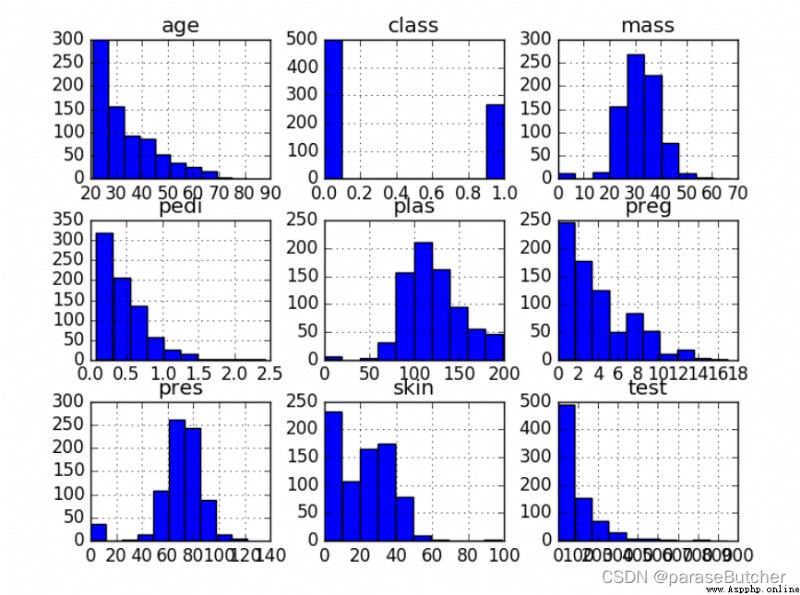
# Univariate Histograms
from matplotlib.pyplot as plt
from pandas import read_csv
path = "diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(path , names=names,skiprows=1)
data.hist()
plt.show()
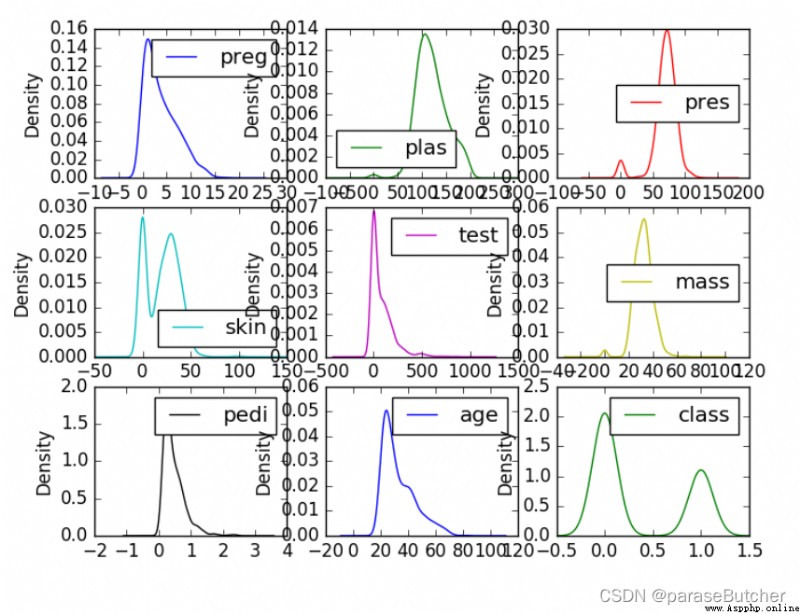
密度圖是快速了解每個屬性分布的另一種方法
data.plot(kind=?density?, subplots=True, layout=(3,3), sharex=False)
plt.show()
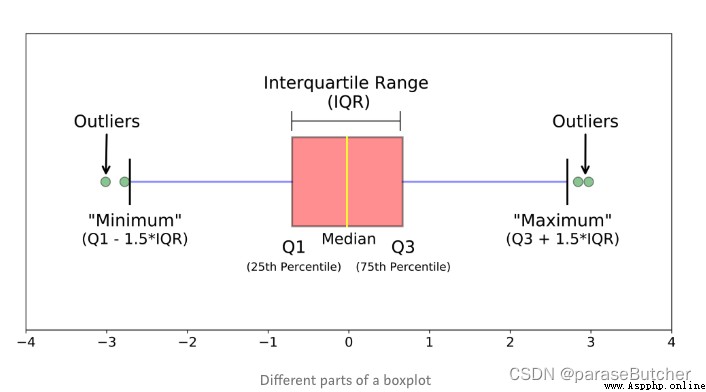
總結:
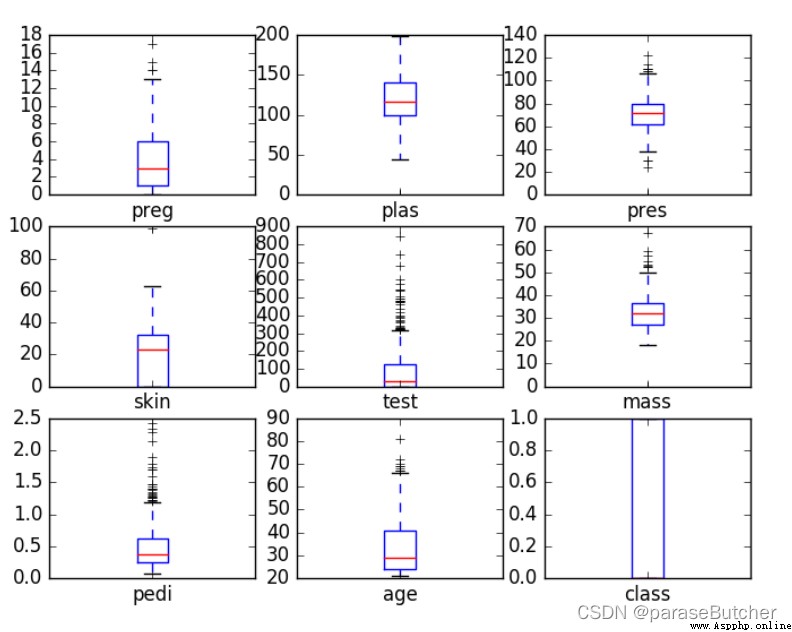
箱線圖是針對連續型變量的,解讀時候重點關注平均水平、波動程度和異常值。
當箱子被壓得很扁,或者有很多異常的時候,試著做對數變換。
當只有一個連續型變量時,並不適合畫箱線圖,直方圖是更常見的選擇。
箱線圖最有效的使用途徑是作比較,配合一個或者多個定性數據,畫分組箱線圖
data.plot(kind=‘box’, subplots=True, layout=(3,3), sharex=False, sharey=False)
plt.show()
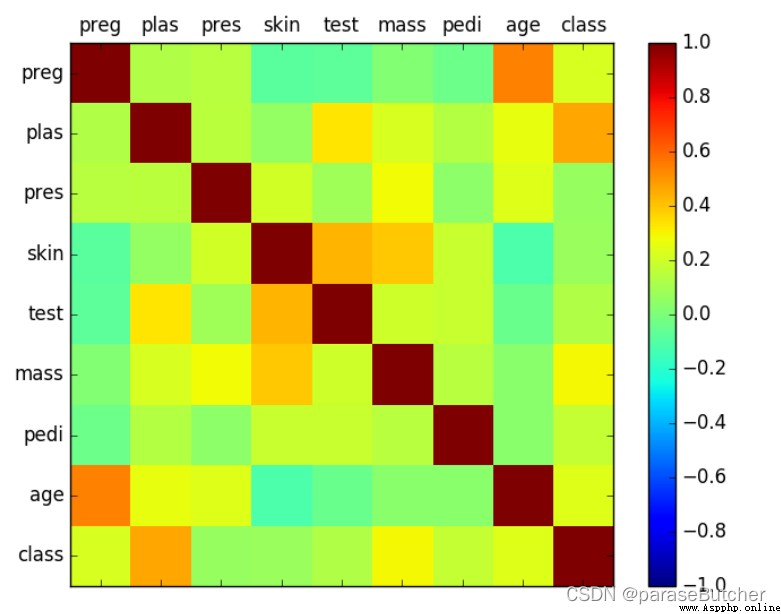
import matplotlib.pyplot as plt
import numpy as np
from pandas import read_csv
path = "diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
correlations = data.corr(method='pearson') # 得到皮爾遜相關系數
# plot correlation matrix
fig = plt.figure() # 相當於拿到一張畫布
ax = fig.add_subplot(1,1,1) # 創建一個一行一列的子圖
cax = ax.matshow(correlations, vmin=-1, vmax=1)
fig.colorbar(cax) # 將色彩變化條(右邊那一豎著的)添加到圖中
ticks = np.arange(0,9,1)
# ticks = [0 1 2 3 4 5 6 7 8] 構造一個0-8,step=1的np數組
ax.set_xticks(ticks)
ax.set_yticks(ticks)
ax.set_xticklabels(names) # 打上index,默認采用數字
ax.set_yticklabels(names)
plt.show()
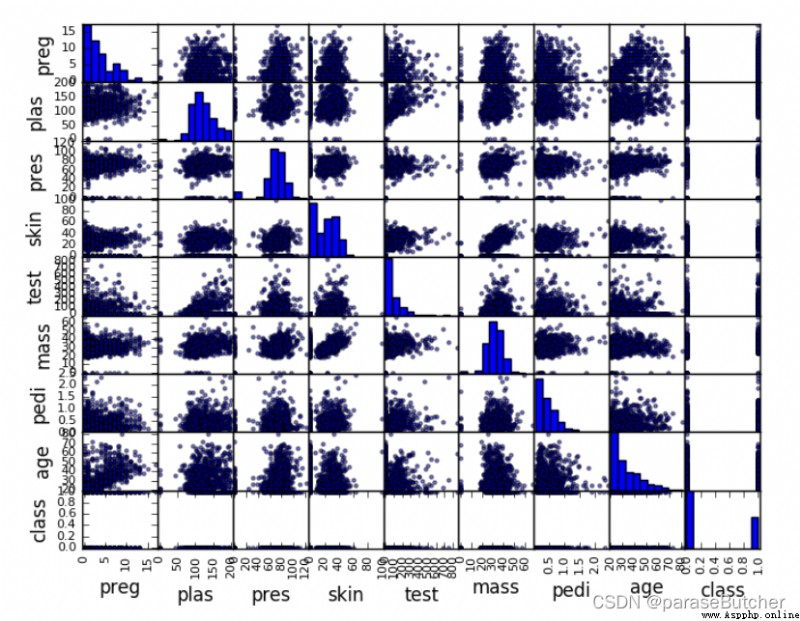
from matplotlib.pyplot as plt
from pandas import read_csv
from pandas.tools.plotting import scatter_matrix
path = "diabetes.csv"
names = ['preg', 'plas', 'pres', 'skin', 'test', 'mass', 'pedi', 'age', 'class']
data = read_csv(filename, names=names)
scatter_matrix(data)
plt.show()
Summary:
Stay hugry, stay foolish.