資源下載地址:https://download.csdn.net/download/sheziqiong/85719088
新技術在 Visual Question Answering中的應用
摘要
Visual Question Answer (VQA) 是對視覺圖像的自然語言問答,作為視覺理解 (Visual Understanding) 的一個研究方向,連接著視覺和語言。問題的格式是給定一張圖片,並提出關於這張圖片的問題,獲得該問題的回答。
使用了BOW詞袋模型和Word To Vector單詞矩陣化的技術來分別處理label和輸入的單詞向量,及LSTM網絡和Attention機制,VIS+LSTM網絡結構,搭建了VQA問題的新模型。在我們的模型中,擁有3個LSTM網絡分別處理:文本,圖像,文本和圖像。在可視化輸出結果中,正確回答在Top5回答中的可能性很高。
關鍵詞: BOW Word To Vector LSTM Attention VIS+LSTM VQA
目錄
1 問題說明 1
1.1 問題背景 1
2 問題分析 1
3 猜想 1
4 模型的建立 1
4.1 模型概述 3
4.1.1 數據集的使用 3
4.2 VGG19模型 3
4.2.1 VGG19 效果分析 3
4.2.2 VGG19 參數分析 3
4.3 LSTM 模型 3
4.3.1 LSTM 效果分析 3
4.3.2 LSTM 參數分析 3
4.4 Word To Vector 模型 3
4.4.1 Word To Vector 效果分析 3
4.5 綜合模型分析 4
5 模型的效果 4
6 模型的提升 5
引用 6
1 問題說明
1.1問題背景
Visual Question Answer (VQA) 是對視覺圖像的自然語言問答,作為視覺理解 (Visual Understanding) 的一個研究方向,連接著視覺和語言,模型需要在理解圖像的基礎上,根據具體的問題然後做出回答。
隨著深度學習的不斷發展,我們對於VQA問題的解答也有了飛躍。從早期的VIS+LSTM模型[1]和它的變種VIS+雙向LSTM網絡,到目前興起的attention機制[2],還有諸如外鏈知識庫和Word To Vector的發展,無疑都大大推動了我們的研究。本文將使用包括但不僅僅是以上的幾種思路,設計我們自己的VQA模型,其中的創新之處在於,我們同時運用了多種新技術,使用了在不同維度上的感受器分別感受空間和實體,並將其巧妙地融合在一起。
2 問題分析
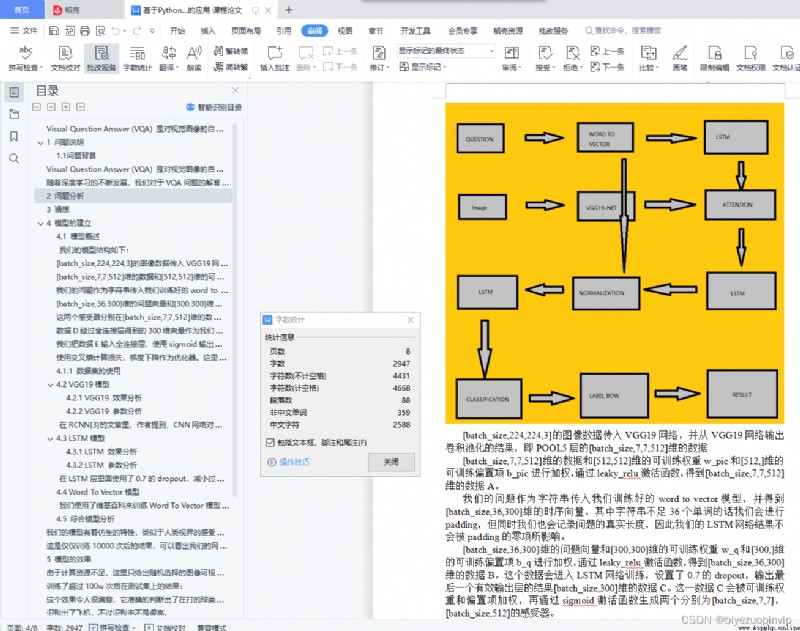
解決VQA問題需要NLP+CV的共同合作才能完成,因此我們的主體框架仍然緊緊圍繞視覺感知+自然語言處理的方向。
其中,我們使用一個訓練好的VGG19網絡作為視覺感受器,並使用LSTM網絡處理我們的問題。在LSTM處理之前,我們會使用Word To Vector的模型,使用維基百科的句子訓練詞向量,並建立字典,將每個英文單詞映射到一個300維的向量空間。
我們目前擁有的數據集是一個非常大型的數據集COCO-QA,它的訓練集有80000多張圖片,測試集有80000多張圖片,驗證集也有40000多張圖片,每張圖片有數量不等的問題,每個問題有10個回答,並且標注了每個回答的信心程度。
3 猜想
我們猜想LSTM網絡最後一個輸出層的結果包含的問題的信息可以很好地生成空間感受器和類別感受器,用於給圖像加入attention機制。這個attention我們加載到了圖像進入VGG19網絡後輸出的第一個全連接層前面的那個池化層上。我們希望這兩個感受器能夠感受到我們想要的物品和空間位置信息。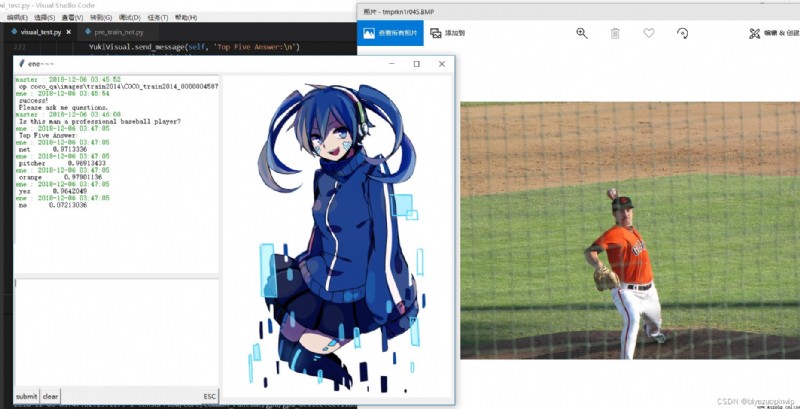



資源下載地址:https://download.csdn.net/download/sheziqiong/85719088