針對特殊功能的優化建議 -- 搜索
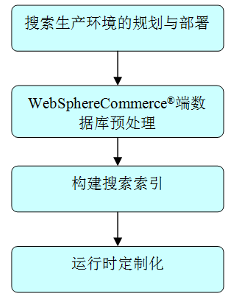
搜索新特性是 Commerce V7 FEP2 期間引入 WebSphere Commerce 產品的功能特性,可以提供大數據集下 具有良好可拓展性的快速搜索功能。搜索新特性提供了一個完整整合的第三方搜索引擎的運行時框架,並圍繞 該框架提供了包括產品目錄搜索、業務管理等其他功能共同構成了一個完整的解決方案。由於搜索框架提供功 能豐富的擴展性,未來的新功能特性都可以選擇基於該框架來開發,因此如何更好的優化搜索性能就顯得更加 重要。由於 WebSphere Commerce 產品中默認集成了基於 Lucene 庫開發的 Solr 搜索引擎,如無特別指明 ,本文提供的搜索引擎優化建議是針對 Solr 給出的。本章節將按照如下圖 1 所示按步驟介紹各部分的優化 過程。為簡略起見,下文將 WebSphere Commerce 簡稱為 Commerce。
圖 1. 搜索運行時環 境部署步驟
搜索生產環境規劃與部署的優化
WebSphere Commerce 站點拓撲規劃
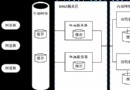
Commerce 搜索新特性整合了開源免費的搜索引擎 Solr,將之部署為一個獨立的 WAS 應用,所以在對整個 Commerce 站點做容量規劃時需要將該應用所需的服務器資源考慮在內。通常建議考慮采用水平方式,獨立服 務器運行 Solr 應用,這樣可以避免對 Commerce 應用所在服務器的容量有所影響。這種拓撲所帶來的成本, 除了所需額外服務器資源外,是需要消耗一部分內網網絡帶寬來傳輸 Commerce 與 Solr 應用之間的請求與響 應的數據,考慮企業內網網速及帶寬情況,應是可以承受的。或者考慮垂直方式將 Solr 應用放在同一個 Commerce 所在服務器的一個獨立 JVM 中。這樣可以節省服務器成本已經內網帶寬,但占用消耗同一服務器容 量。
Solr 應用同時還需要 Web 服務器支持,通常我們建議部署獨立的 Web 服務器給 Solr 集群使用 ,這樣做的好處是避免共用 Commerce 的 Web 服務器所帶來的安全性潛在風險,以及 Solr 查詢請求需要額 外經過防火牆而導致的性能問題,但獨立部署新的 Web 服務器需要額外的硬件采購,包括負載均衡等方面的 考慮,這一點需要在客戶實施環境具體情況具體分析來做決策。
Solr 應用拓撲規劃
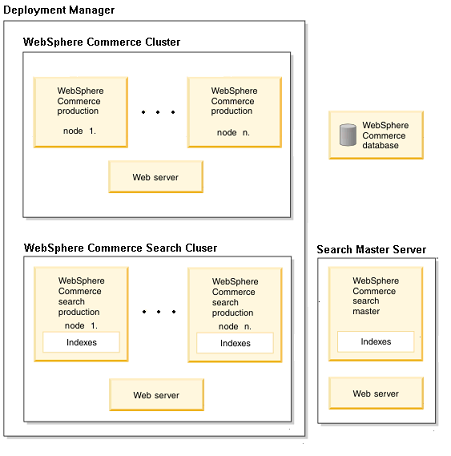
在大型站點上,通常會有幾千或上萬並發訪問量,單獨一個 Solr 運行時 Java 虛擬機很難保證處理這麼 多訪問的性能,因此可以對 Solr 采用與 Commerce 類似的水平或者垂直 WAS 服務器擴展,並將之合並到一 個集群中。並且通過配置單一主服務節點控制搜索索引數據在集群中的同步,如圖 2 所示。主節點只用於索 引建立更新目的,Commerce 生產環境並不訪問主節點,而是只訪問從節點。每次主節點產生了更新都會被所 有從節點檢測到而被"拉"過去完成數據的復制更新。
圖 2. Solr 主從配置示意圖
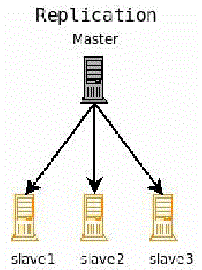
圖 3. Solr 集群結構示意 圖
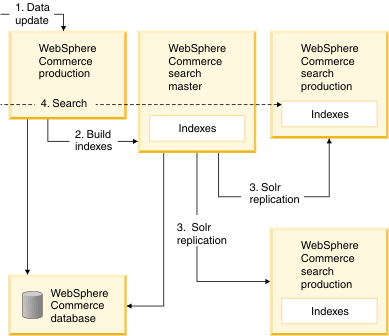
圖 4. Commerce 站點拓撲 規劃
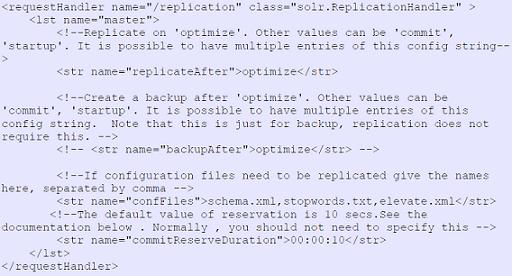
主服務節點與從屬節點的配置樣例 如下圖所示。
圖 5. 從屬 Solr 節點配置例圖
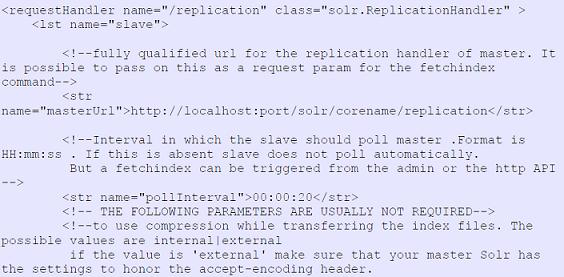
圖 6. Commerce 站點拓撲 規劃
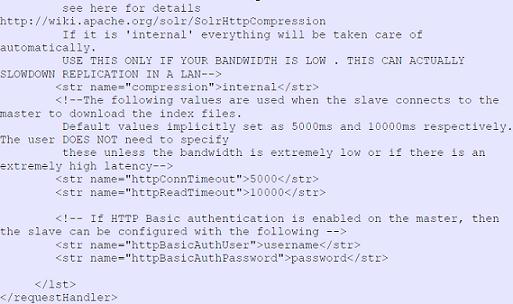
圖 7. 主 Solr 節點配置 例圖
HTTP 服務器網絡參數優化
所有服務請求處理是通過 HTTP 服務器轉發到 WAS,會對 HTTP 服務器的並發連接數及其他方面有優化 要求。在 Commerce 站點中每個訪問商店頁面的入站請求除占用一個 HTTP 連接來處理頁面響應外,還需要占 用連接來處理 Search 請求,因此需要對 HTTP 服務器進行適當調優。
Solr 應用與 Commerce 共用同一個 HTTP 服務器進程
HTTP 服務器允許的並發數 = 同時在線訪問數× 2 + N
Solr 應用與 Commerce 使用不同 HTTP 服務器進程
Solr HTTP 服務器允許的並發數 = Commerce HTTP 服務器並發數 + N
上邊兩種情況的表達式中,N 表示用作管理目的的訪問所使用的 Solr 訪問數,通常這被用作進行搜 索索引數據的建立與更新,多個 Solr 節點間為同步索引而發生的通信等。該值需要根據情況不同做適當考慮 ,通常一個小型站點維持 10-20 的值應該是合理而足夠的。建議 Solr 部署中使用與 Commerce 不同的 Web 服務器,避免相互間影響和服務器資源競爭。
Commerce 端網絡參數優化
Commerce 作為 Solr 應用的客戶端,也有參數控制其網絡調優,這些參數放置在 Commerce 運行時環 境配置文件 wc-search.xml 下,如下例。通過"name"屬性可以找到相應正在使用的配置。
運行時網絡參數配置樣例
<_config:server
name="AdvancedConfiguration">
<_config:common-http URL="http://localhost:9080/solr/"
allowCompression="true"connectionTimeout="5000"
defaultMaxConnectionsPerHost="600"followRedirects="false"
maxRetries="1"maxTotalConnections="600"
retryTimeInterval="6"soTimeout="5000"/>
</_config:server>
其中:
"connectionTimout"為網絡連接超時門限值,"soTimeout"是為建立網絡 socket 連 接時的超時門限值。當生產環境訪問壓力不大時,可以適當縮短這兩個值,避免出現頁面響應時間過長的問題 ,通常 3-5 秒較為理想。如果並發訪問壓力大而導致經常出現超時錯誤,可以考慮增大這兩個值。
"defaultMaxConnectionPerHost"是每個主機所允許的最大連接數,而 "maxTotalConnections"是總計最大連接數。當 Commerce 端與 Solr 均為單獨服務器,且是一一 對應,則兩參數可以設置為相同。在集群環境下"maxTotalConnections"要大於 "defaultMaxConnectionPerHost"。這兩個參數值與上節 HTTP 服務器參數調整同樣,要考慮可能 出現的並發訪問量,過小的設置會出現拒絕訪問錯誤。
"maxRetires"控制當到 Solr 請求出錯時重試的次數,"retryTimeInterval"為控制 重試的間隔。這裡建議不要將"retryTimeInterval"設置過大,避免後續請求因為等待重試間隔而 出現拒絕訪問錯誤。
Java 虛擬機參數優化
根據 Solr 運行時特性,其 Java 虛擬機參數的優化主要集中在 JVM 堆內存大小上。需要設置足夠大小來 確保 Solr 各項邏輯的運行效率。根據生產環境下可能涉及到 Solr 應用的邏輯,該項參數優化需要考慮如下 幾點:
建立搜索索引時候批量處理的數據庫記錄對象大小
搜索索引數據集大小。建議在條件允許下將盡可能多的索引數據放置在文件系統緩存中。首先查看 <solr 主目錄 >/solr.xml,檢查每個 solr core 的 instanceDir 屬性,之後在查看 instanceDir/data 目錄的大小來估計索引數據的大小
Solr 運行時的數據緩存大小
Solr 數據結構定義的復雜程度及其所決定的文檔對象大小
Solr 運行時 Java 虛擬機堆內存大小在創建實例時默認定義為 512MB ~ 1024MB,實際上線前需要打開虛 擬機詳細垃圾回收日志選項 (-verboseGC),通過在站點上監測分析 Java 虛擬機的垃圾回收日志來進一步調 優。一般將垃圾回收執行影響維持低於 5% 可以認為達到最優。
Commerce 端數據庫預處理
Commerce 中每種業務對象模型所對應的數據庫模型會分散在幾張或十幾張表中。為了提高將數據導入 搜索引索引中的性能,需要對數據進行預先"扁平化"到更少的表中,這稱為數據預處理,通過 Commerce 工具"di-preprocess.sh"完成。該工具的過程是先創建一些臨時表,將查詢到所有滿足 條件的數據記錄批量插入到這些臨時表中。因此數據預處理性能取決於兩個方面,一是查詢記錄性能,二是批 量插入性能。查詢性能取決於所寫的 SQL 查詢語句的條件復雜性及其優化。第二個插入數據的性能更依賴於 對數據庫的調優,包括內存緩沖,I/O 子系統等。本章節以 IBM DB2 產品為例進行介紹,對於其他數據庫, 如 Oracle 等,優化思路與之類似。對於優化數據預處理,給出這樣幾點建議:
為預處理用到的臨時 表創建單獨的表空間,並且在創建時就確保表空間所需到的物理存儲空間完成預先分配,保證分配空間連續性 。此外如果臨時表每條記錄較大,推薦增大表空間頁大小。
為該獨立表空間設置足夠大的緩存池,提高磁 盤 IO 效率。如下例代碼,創建一個單獨的表空間"MYTAB32K",並設置為 32K 大小代碼頁和相應 的緩存池。
CREATE BUFFERPOOL MYBUFF32K IMMEDIATE ALL DBPARTITIONNUMS
SIZE 4000 NUMBLOCKPAGES 0 PAGESIZE 32K
CREATE REGULAR TABLESPACE MYTAB32K PAGESIZE 32K MANAGED
BY AUTOMATIC STORAGE EXTENTSIZE 32 BUFFERPOOL
MYBUFF32K INITIALSIZE 600M INCREASESIZE 500M
如 果插入數據中有大文本數據,在列長度可以容納的情況下,優先使用 VARCHAR 類型,而不是 LOB 類型。
如果文本數據很大,必須使用 LOB 類型時,需要在創建表空間時候打開 FILESYSTEM CACHING 開關,如下代 碼所示:
CREATE REGULAR TABLESPACE MYTAB32K PAGESIZE 32K MANAGED BY
AUTOMATIC STORAGE EXTENTSIZE 32 BUFFERPOOL MYBUFF32K FILE
SYSTEM CACHING INITIALSIZE 600M INCREASESIZE 500M
在完成指定表空間創建後,需要修改 Utility 配置文件來保證臨時表是創建在前面步驟所創建的專用 表空間中,同時可以在這裡對臨時表進行性能微調,如去掉日志特性等來提高預處理速度。配置文件路徑請參 考 Commerce 相關文檔。預處理工具會有多個 xml 格式的配置文件,每個文件中都是類似格式定義了創建和 處理實體對象表所用到的 SQL 語句。
<_config:table definition="CREATE TABLE TI_CATALOG_0 (
CATENTRY_ID BIGINT NOT NULL, CATALOG VARCHAR(256),
PRIMARY KEY (CATENTRY_ID))NOT LOGGED INITIALLY
IN MYTAB32K"name="TI_CATALOG_0"/>
調整數據庫管理程序中的並發 IO 參數,參考實際環境中用到的磁盤系統,推薦將數據庫負責異步並 發 IO 進程數,設置成與磁盤系統所能達到的 IO 並發系數一致。如下例,這裡只有一塊磁盤,因此設置只有 一個進程負責讀寫該磁盤。
UPDATE DB CFG FOR MALL USING NUM_IOCLEANERS 1
針對 #6,如 果使用的是磁盤陣列,可能還考慮將條帶深度設置與數據庫 IO 單位一致,比如 DB2 中的 Extent 區塊大小 ,以避免並發 IO 之間的磁盤爭用。
調整內存數據緩沖與磁盤文件間同步的門限值,避免過大的同步數據 量導致磁盤系統過載。
UPDATE DB CFG FOR MALL USING CHNGPGS_THRESH 50
在 V7FEP3 中, di-preprocess.sh 工具開始支持多線程模式處理數據,這會很大程度幫助提升處理性能。這個功能可以通過 執行命令時附加參數開關來打開。
構建搜索索引
在使用工具"di-buildindex.sh"或者通過浏覽器觸發 Solr 構建索引數據時候,會有多個參數 影響其性能,下面將逐一介紹。所有配置參數都在 Solr 核心配置目錄下的文件"solrconfig.xml" 。
useCompoundFiles
"useCompoundFiles"參數控制 Solr 是否使用多個文件組成整個 Index 數據。考慮操作系統對 於進程可持有的文件描述符限制及文件系統緩存機制,通常該參數建議值為"false"來提高索引建 立的性能
mergeFactor
索引數據文件由"segment"組成,也稱之為區段。"mergeFactor"參數控制了文件中 segment 的個數。當構建索引時,新數據會添加到到正在使用的區段中。當文件中段個數超過 "mergeFactor"定義值,這些區段會被合並到一個中。該參數值設置過低會引起區段合並操作過於 頻繁而影響性能,但是較小的值會提高搜索性能。因此需要合理選擇該參數值,產品默認值為"10" ,可以得到不錯的性能。可以根據實際情況進行調節。
maxBufferedDocs
Solr 中將每一條數據記錄稱之為一個文檔,該參數控制內存中可以緩存的文檔數據對象個數,當達到門限 值時,數據會被同步到磁盤。該參數需要配合 Java 虛擬機堆內存設置來調整,同時根據 Solr 文檔數據結構 定義考慮每個文檔對象可能的大小。可能情況下設置足夠的內存緩存大小可以加速構建索引的性能。
ramBufferSizeMB
該參數從另一個角度控制文檔數據對象的內存緩存。當已經緩存內容達到該值,數據會被同步到磁盤。可 能情況下設置足夠的內存緩存大小可以加速構建索引的性能。
maxMergeDocs
該參數控制了數據文件區段中文檔數據對象個數。適當設置大一些的值可以減少合並操作頻率而提高性能 。
autoCommit
這是一個參數組,分別用"maxDocs"和"maxTime"控制自動提交更改文檔的個數門限 和時間門限。頻繁提交可以保證索引數據的實時准確性,但是會降低性能。對於完整重新構建索引數據,設置 一個大一些的值是比較合理的。
在構建索引時禁用索引優化
如果索引數據量非常大,在日常維護時間內無法完成,而又不可以影響正常生產環境訪問,可以在構建中 利用參數禁止索引優化功能。索引優化是個單線程操作,而且是 Solr 及 Lucene 內部核心功能,難以有效優 化其性能,而且不做優化並不影響 Solr 正常工作,只會對搜索響應時間有些許延長。可以在不影響生產環境 使用情況下,在 Solr 主節點環境下完成,在合適時間通過復制同步到生產環境。可以通過浏覽器來觸發索引 構建時候加上參數來達到禁用優化的目的,如下例:
http://<hostname><port>/solr/<SolrCore_name>/dataimport?command=full- import&optimize=false
當 index 完成並且有合適時間時,可以執行下面 URL 來單獨進行 index 數據優化:
http://<hostname><port>/solr/<SolrCore_name>/update?optimize=true
另外索引創建過程中會有大量文件操作,因此需要調整操作系統層面對於進程打開文件句柄個數的限制 ,比如 UNIX/LINUX 系統中的"ulimit"命令和 Windows 系統中的注冊表操作,具體使用方法請參 考各操作系統的說明文檔。
運行時定制化
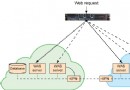
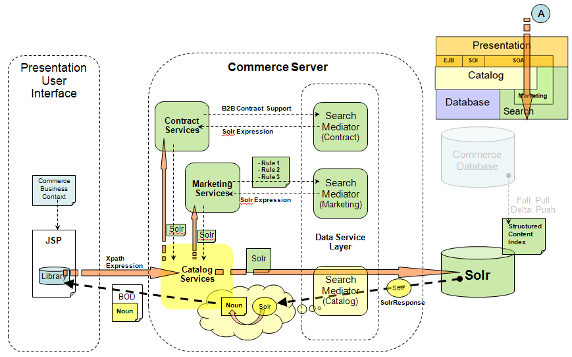
Commerce 針對整個的 Solr 應用,在基礎架構層面給出了功能完善的接口,使得搜索特性除了自身的搜 索功能外,更可以為其他組件使用,如產品目錄,訂單等,扮演著數據提供者角色。同時這些服務接口也提供 了豐富的內建功能及可擴展定制化的特點,因此在對這些接口進行合理的定制和優化對提高運行時性能至關重 要。下圖是 Commerce 搜索基礎架構服務的流程示意圖,可以看出特性特性被其他組件廣泛應用。下面將逐一 介紹運行時性能優化的建議。
圖 8. 搜索功能運行時邏輯結構圖
Runtime 定制化
Search service 優化及合理使用
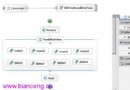
圖 9. Search service 調用流程
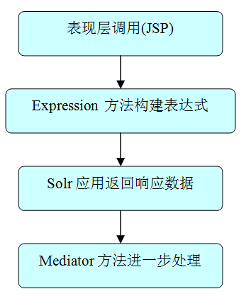
上圖給出一個搜索 SOA 服務的典型 調用過程。通常最典型的情況就是 JSP 頁面通過搜索 SOA 接口拿到所需要內容。而這個調用過程還涉及到 Expression builder 和 Mediator 邏輯,可以通過相應的搜索概要配置 (Search profile) 定義得到,如下 所示的例子。在搜索概要配置元素中,分別包含了 <_config:query>,用來得到搜索查 詢條件的方法類定義,以及 <_config:result>,用來得到對得到的初始搜索結果集進行 處理的過濾器方法類的定義。
<_config:profile
indexName="CatalogEntry"name="IBM_findCatalogGroupDetails">
<_config:query>
<_config:param name="maxRows"value="50"/>
<_config:param name="maxTimeAllowed"value="15000"/>
<_config:param name="debug"value="false"/>
<_config:param name="preview"value="1"/>
<_config:param name="price"value="1"/>
<_config:param name="statistics"value="false"/>
<_config:provider classname="com.ibm.commerce.catalog.facade.
server.services.search.expression.solr.SolrSearchIndexNameValidator"/>
<_config:provider classname="com.ibm.commerce.catalog.facade.server.
services.search.expression.solr.SolrSearchIndexSynchronizer"/>
......
<_config:provider classname="com.ibm.commerce.catalog.facade.server.
services.search.expression.solr.
SolrSearchProductEntitlementExpressionProvider"/>
</_config:query>
<_config:sort/>
<_config:result>
<_config:filter classname="com.ibm.
commerce.catalog.facade.server.services.
search.metadata.solr.SolrSearchCatalogEntryViewPriceResultFilter"/>
<_config:filter classname="com.ibm.commerce.catalog.facade.server.
services.search.metadata.solr.
SolrSearchCatalogEntryViewSingleSKUResultFilter"/>
</_config:result>
<_config:highlight simplePost="</span></strong>
"simplePre="<strong><span class=font2>"/>
<_config:facets>
<_config:param name="sort"value="count"/>
<_config:param name="minCount"value="1"/>
<_config:param name="limit"value="10"/>
<_config:category scope="all">
<_config:facet converter="com.ibm.commerce.
catalog.facade.server.services.search.metadata.solr.
SolrSearchCategoryFacetMetaDataConverter"
name="parentCatgroup_id_search"/>
<_config:facet name="*"/>
</_config:category>
</_config:facets>
<_config:spellcheck>
<_config:param name="limit"value="5"/>
</_config:spellcheck>
<_config:mapping/>
</_config:profile>
這些定義的方法類將會通過反射等方式被運行時邏輯動態調用,因此合 理選擇必要的方法並進行優化對搜索接口服務的性能有重要影響。通過上面的搜索 SOA 接口的執行邏輯我們 可以得出幾點代碼優化的建議:
正確使用搜索 SOA 調用。Solr 應用是具有良好性能的搜索引擎,可以在不同大小的數據集下提供穩定的 搜索響應時間性能。它所適合的使用場景,是針對文本及復雜語義條件的快速搜索,這是常規數據庫等其他數 據源所不能提供的功能。如下面所示就是一個反例,JSP 片段代碼通過一次搜索 SOA 調用只是獲取產品子目 錄的一個描述信息。相比之下將該信息放置於數據庫中通過 SQL 語句查詢更加合理,因為這種查詢並不涉及 復雜文本搜索,同時也存在合適的唯一索引這樣的條件適合利用數據庫索引及內存緩沖可以加速查詢性能。
<wcf:getData type="com.ibm.commerce.catalog.facade.datatypes.
CatalogNavigationViewType"var="catGroupDetailsView"expressionBuilder
="getCatalogNavigationCatalogGroupView">
<wcf:param name="UniqueID"value="${catUniqueId}"/>
<wcf:contextData name="storeId"data="${WCParam.storeId}" />
<wcf:contextData name="catalogId"data="${WCParam.catalogId}" />
<wcf:param name="searchProfile"value="IBM_findCatalogGroupDetails"/>
</wcf:getData>
不要過量使用 Search service。通常每次要完成一次搜索服務調用都會帶有一次以上的查詢。Solr 是一 個更加依賴於 CPU 資源的應用,過多查詢請求會導致 Solr 應用占據並耗光 CPU 使用時間而影響到整體性能 。如果條件允許,可以將循環多次調用的 Solr 查詢合並為一次查詢往往會提升查詢的性能。
合理定制搜索服務概要配置。對每次的調用,概要配置中的列出的 Expression provider 方法會決定最終 生成的查詢條件,決定了搜索條件的復雜性,而 Mediator 方法會對數據進行後處理。使用者需要根據每次調 用場景的實際需要合理選擇所需的 Expression provider 方法列表和 Mediator 方法列表,以及返回數據的 格式,確保所有調用都是按需查詢,因為過多的方法調用和返回的多余的數據,以及不必要的處理邏輯都有可 能對性能有很大影響。類似的 Mediator 如:
<_config:filter classname="com.ibm.commerce.catalog.facade.server.services. search.metadata.SearchCatalogEntryViewSingleSKUResultFilter"/> <_config:filter classname="com.ibm.commerce.catalog.facade.server.services. search.metadata.SearchCatalogEntryViewPriceResultFilter"/>
這兩個 Class 分別用來處理,產品只有 SKU 以及通過索引獲取價格信息的。代碼邏輯較為復雜,如果運 行時環境不需要這兩項功能,比如不存在只有單個 SKU 的產品,以及價格信息來自數據庫,則可以修改 wc- search.xml 中的 SearchProfile 配置,去掉無用的 Filter mediator。
Commerce 產品支持針對不同客戶群組進行長產品目錄過濾,稱之為 Contract Entitlement。在引入搜索 新功能後,Contract Entitlement 功能也做了功能提升,可以將通過產品屬性內容進行動態過濾,或者直接 定義產品集進行過濾。但利用產品過濾器進行動態過濾雖然功能更加強大,但帶來而外的代碼執行負擔,有損 性能。因此對不需要產品過濾器的動態過濾功能情況,比如過濾條件簡單(大多數 B2C 商店便是如此),可 以將之去掉,改為使用之前基於數據庫的實現邏輯。
首先備份 <WC_demo.ear>/xml/config/com.ibm.commerce.catalog-fep/wc-search.xml
然後在 wc-search.xml 中搜索如下條目,將之從 SearchProfile 配置中刪除或者注釋:
<_config:provider classname="com.ibm.commerce.catalog.facade.server.services. search.expression.solr.SolrSearchProductEntitlementExpressionProvider"/> <_config:provider classname="com.ibm.commerce.catalog.facade.server. services.search.expression.solr. SolrSearchCategoryEntitlementExpressionProvider"/>
備份數據庫後,執行如下 SQL 並將 SQL 返回的數據記錄刪除
select * from cmdreg where classname = 'com.ibm.commerce.contract.
commands.CheckCatalogGroupEntitlementBySearchCmdImpl' ;
select * from cmdreg where classname = '
com.ibm.commerce.contract.commands.
CheckCatalogEntryEntitlementBySearchCmdImpl' ;
select * from cmdreg where
classname = 'com.ibm.commerce.catalog.commands.
CheckSearchFeatureEnablementForCatalogFilterCmdImpl';
重啟 Commerce 服務器驗證功能。
對於新代碼的性能評估,由於 Solr 應用偏向於 CPU 資源密集型,可以通過性能測試等手段,考察系統整 體吞吐率,響應時間並關注對 CPU 資源消耗上的差異,作為評估其性能好壞的重要指標。
此外還需要根據代碼所用到 Solr 查詢條件考察其在 Solr 端的處理性能。一個簡單的辦法是在 WAS Solr 服務器控制台將日志等級調整為"*=info",這樣每次查詢都會在 SysmtemOut.log 中打出日志,其 中 QTime 即查詢在 Solr 端所消耗時間。
Commerce FEP5 版本引入的 Facet 配置及顯示功能,使用戶可以很容易為運行時增加 Facet 域。但是 Solr 查詢中過多 Facet 域會對站點性能是一個很大的挑戰。這主要是兩方面的考量:
WC 運行時端。當產品目錄頁有 Facet 需要顯示,WC 邏輯需要從數據庫中查出相關聯的 Facet 域名,再 通過 Solr 查詢得到具體信息後,如果 Facet 是 AttributeDictionary 相關,還需要迭代通過 AD service 得到屬性名字和值。當 Facet 過多,可以通過緩存改善頁面性能。參加下節"數據緩存"部分,配 置"SearchNavigationCache"和"SearchAttributeCache"緩存實例。
Solr 運行時端。當 Solr 處理每一個 Facet 域時,它會創建相應 Facet 結果對象並進 行緩存。Facet 處理和緩存對象大小與索引文檔數目有關。索引越大,處理速度越慢,相應的緩存對象越大。 實際測試表明,對一個一百萬條目索引進行一個 Facet 域處理,需要幾十到上百毫秒。因此 Solr 對結果對 象的緩存對性能改善至關重要。但是緩存不可濫用,以免過多緩存對象導致內存不足問題。具體 Solr 端緩存 配置參加下一節"數據緩存"中的"域值緩存"介紹。
Solr 端的擴展插件使用。Solr 應用是一個較為開放的框架體系,為了適應更多用戶的需 求,其提供了插件擴展機制來滿足未知的功能需求。所支持的插件功能包括查詢請求預處理,返回數據格式處 理,查詢結果後處理等等。很明顯,不合理的插件應用邏輯及使用也會極大影響到 Solr 端的性能。舉例來說 ,在 Solr 索引配置目錄下的配置文件 solr/home/MC_10001/en_US/CatalogEntry/conf/solrconfig.xml , 有這樣的配置 :
<valueSourceParser name="getSequenceByCatalogAndCategory"class= "com.ibm.commerce.foundation.internal.server.services.search. function.solr.SolrSearchGetSequenceByCatalogAndCategoryFunctionParser"/>
這是用來對 Solr 每次查詢的結果動態計算其 _val_ 值以確定其與查詢條件的匹配程度,來滿足查詢排序的功能需求。由 於是動態計算,對於每次返回的結果集合中的每一個記錄,該 class 中的方法需要進行迭代處理,因此其性 能受返回結果集大小影響而線性變化。當生產環境有很大的產品目錄,在產品目錄浏覽場景下,每個頂層產品 品類頁面的查詢都可能返回其所有產品,數量會很多,此時該頁面的 Solr 查詢就會受該插件處理邏輯的影響 。而實際上除了產品目錄頁和搜索頁面,很少需要用到查詢條件排序。比如對於基於 Contract 組件的搜索過 濾等等其他利用 Search Service 的功能。因此可以在用到的搜索概要配置中去掉相應 Expression Provider 配置:
<_config:provider classname="com.ibm.commerce.catalog.
facade.server.services.search.expression.solr.So
lrSearchSequencingExpressionProvider"/>
數據緩存
Commerce 搜索框架中,對數據緩 存的使用與其他組件類似。總體的思路是根據代碼邏輯的復雜性,數據的可重用性以及確保功能正確的緩存失 效機制來衡量哪些內容可以被放入緩存中。為提升性能,可以按照如下優先順序順次遞減考慮緩存內容,整體 頁面 -> 頁面片段 ->Java Command 緩存 -> 數據緩存。
對於搜索新特性的整體頁面或者頁 面片段的緩存,在產品中已經默認提供了商店頁面的動態緩存配置樣例,可以根據商店類型不同參考 <WC 安裝目錄 >/ samples/dynacache/< 商店類型 >/dynacache.xml,其主要針對具有產品目錄頁面進 行緩存,因為這部分頁面緩存具有良好的可重用性。如果需要對關鍵字搜索結果進行緩存,需注意因為關鍵字 緩存內容重用性很低,可以在動態緩存定制中考慮僅將熱門關鍵字加入緩存。
最新的 Commerce FEP5 版本 中,提供了將 AttributeDictionary 作為 Facet 的工具和 Runtime 支持。但是在運行時中增加過多 Facet 會影響前台性能。此時可以配置預先定義的 WC 數據緩存實例來改善性能。請注意,這些緩存實例在部署 FEP5 實例時候已經創建,我們需要做的是合理配置緩存大小。
SearchNavigationCache 對象緩存實例。該 緩存用來存放每個產品子目錄所對應的可用 Facet 域信息。因此需要將該緩存大小設置為整個站點產品目錄 下的子目錄數量。
SearchAttributeCache 對象緩存實例。該緩存用來存放特定 AD facet 信息,比如 AD 屬性名字,值。因此緩存大小應該調整為站點 AD 中所有可以作為 Facet 的屬性數量。
具體 調整方法是,登錄 WAS 控制台,在"資源"-> "緩存實例"-> "對象緩存實 例"下,在右邊列表中找到相應實例打開後,調整緩存大小的值。
搜索的數據緩存與 Commerce 中其 他數據緩存不同,因為它的數據來源是 Solr 搜索引擎,因此其數據緩存是定義在 Solr 核心配置文件 solrconfig.xml. 一般情況下,如果 Solr 應用的內存足夠,將這些緩存設置大一些會得到更好的性能。
過濾器緩存 (Filter cache). Solr 中通過過濾器查詢來縮小搜索范圍,以有助於提升搜索性能。對 於每個過濾結果,可以放置在專用緩存中。這個緩存通過過濾查詢條件作為緩存關鍵字,相同的查詢會通過緩 存命中而快速得到結果,參見下面的配置文件片段作為例子:
<filterCache class="solr.FastLRUCache"size="8192"
initialSize="4096"autowarmCount="0"/>
查詢緩存 . 查詢緩存可以將查 詢結果集緩存下來。由於緩存的內容是 Solr 文檔對象的 ID 值,因此其內存占用小,可以將緩存大小設置大 一些來換取更好性能。參見下面的配置文件片段作為例子:
<queryResultCache class="solr.LRUCache"size="8192"initialSize="4096"
autowarmCount="0"/>
文檔對象緩存 . 文檔對 象緩存用來緩存每個文檔對象內容。如果文檔對象大,數據很多,可以通過該緩存來減少從索引讀取完整數據 的時間。參見下面的配置文件片段作為例子:
<documentCache class="solr.LRUCache"size="8192"
initialSize="4096"autowarmCount ="0"/>
域值緩存 . 域值緩存有一個重要作用,是作為 Facet 對象的緩存,能夠大幅 提升帶有 Facet 域的查詢性能。Solr 實現中,對於每個 Facet 會產生一個對象存放 Facet 域與 Solr 文檔 對象關系。該對象中會存放一個整型數組,數組大小與 Solr 索引中文檔數目一致。因此可以估算一個 Facet 結果對象的大小:
Facet 對象大小 = 4 bytes × 索引文檔條目總數量
可以看出對於很大的產 品目錄索引,比如有一百萬條,一個 Facet 結果對象大約會占用 4M 字節空間。
特別需要注意的是, 即使在 solrconfig.xml 中沒有顯式配置域值緩存,Solr 代碼仍然會創建相應的緩存實例,此時緩存實例大 小是硬性指定的 100000。當站點應用涉及非常多的 facet 時,很容易引起 Solr JVM 內存不足錯誤。所以一 定要仔細評估所有可能的 Facet 數量,並根據 JVM 可用內存空間顯示設置該緩存實例。
<fieldValueCache class="solr.FastLRUCache" size="512"
showItems="32"autowarmCount="129"/>
此外如果 Solr 有 深入應用定制,可以增加自定義緩存 . 這些用戶自定義緩存可以被自定義代碼使用。
<cache name="myUserCache"class="solr.LRUCache"
size="8192" initialSize="4096" autowarmCount="0"/>
其他
在 Commerce 的新產品中,也有其他新特性是依賴搜索框架設計實現的,所以在性能優化中也需要統一考 慮。
產品目錄過濾器
產品目錄過濾器特性是 Contract 組件的一項新功能,它通過對 Solr 查詢語句的控制來完成產品數據的 過濾選擇。其基本使用是在產品類別或產品條目節點上增加"包含 / 排除"的選擇,同時可以附加 屬性或描述信息來細化過濾條件。在使用中,請注意合理選擇該功能,不要在過多的節點上添加條件,否則會 導致最終 Solr 查詢條件過復雜而影響查詢響應時間。而且過長的條件也會面臨 HTTP 服務器端請求數據長度 限制等其他問題。通常包含 50 個左右節點是比較合理的。同時為了減少過濾器計算負擔,可以增加其相應的 Java Command 緩存,參考樣例 <WC 安裝目錄 >/ samples/dynacache/Contract/dynacache.xml 和 <WC 安裝目錄 >/components/foundation/samples/dynacache/invalidation/catalogfilter/cachespec.xml。將該文件 內容加入 cachespec.xml,可以令 Java Command 方法將產品目錄過濾器計算後的搜索過濾器表達式緩存下來 ,提升運行時性能。
搜索規則
這是一種新類型的市場營銷功能,可以根據客戶的搜索關鍵字或結果集內容,進行靈活多變的精准商品 推薦。與 Catalog Filter 類似,過於復雜或者規則條目數量太大都會影響到頁面響應性能。
尤其需要注意的是這樣一種搜索規則,其中包含有"Search Criterial And Result"元素,那 麼在返回結果集中,該元素會觸發 Marketing component 通過搜索 SOA 調用去通過查詢來細化結果集。該邏 輯用到的數據復雜,而且根據其配置會產生多次查詢,因此當有多條類似規則後,Solr 查詢次數增多導致該 類型規則數量的可擴展性差,對性能影響較大。實際應用中建議避免或減少這種類型搜索規則。
圖 10. 搜索規則樣例