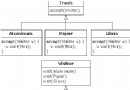
本篇參考:http://tonl.iteye.com/blog/1918245
python版本:2.7 64bit window版本;
下載python:http://www.python.org/getit/
Python 2.7.5 Windows X86-64 Installer (Windows AMD64 / Intel 64 / X86-64 binary [1] -- does not include source),進行安裝:
首先編寫下面的spider.py腳本:
# -*- coding: utf-8 -*-
#import urllib2
from urllib import urlopen
import os
import sys
class Spider:
"""
download web site from the given file
"""
def __init__(self,filename,downloadPath):
"""
init the filename ,if the filename is not raise a error
"""
if not os.path.isfile(filename):
print 'the given file does not exist,the program will exit'
sys.exit(0)
else:
self.fname=filename
if not os.path.isdir(downloadPath):
print 'the given download path does not exist ,the programe will exit'
else:
self.dpath=downloadPath
def download(self):
"""
download the web site from the given file by line
"""
fp=open(self.fname,'r')
while True:
line=fp.readline()
if not line:
break
if 'html' in line:
tempname=filter(str.isalnum,line).replace('html','.html')
else:
tempname=filter(str.isalnum,line)+'.html'
self.download_html(line,self.dpath+'\\'+tempname)
fp.close()
def download_html(self,website,filename):
"""
download the html by the given web site and save to name
"""
response=urlopen(website)
data=response.read()
fp=file(filename,'a+')
fp.write(data)
fp.close()
def test():
"""
test program
"""
filename=sys.argv[1]
downloadPath=sys.argv[2]
spider=Spider(filename,downloadPath)
spider.download()
if __name__ =='__main__': test()
上面的腳本,要輸入兩個參數,一個是要下載的網頁的地址文件,格式一般如下(websites.txt):
查看本欄目
http://blog.csdn.net/fansy1990 http://www.baidu.com
另外一個參數是下載的網頁的存放地點。
然後可以在命令行運行:
python D:\\spider.py D:\\websites.txt D:\\download_tmp
然後到D盤的download_tmp下面查找下載的文件,如果找到,則說明配置正確;
最後編寫下面的java程序,需要導入jython-*.jar包(lz下載的是2.2的):
package test;
import java.io.IOException;
public class PyTest {
/**
* @param args
* @throws IOException
* @throws InterruptedException
*/
public static void main(String[] args) throws IOException, InterruptedException {
String py_path="D:\\spider.py";
String websites="D:\\websites.txt";
String outDir="D:\\tmp";
//
Process pr=Runtime.getRuntime().exec("python "+py_path+" "+websites+" "+outDir );
pr.waitFor();
System.out.println("done ...");
}
}
運行上面的命令,需要設置eclipse中的Environment屬性,添加一個PATH變量,值是python的安裝目錄;
運行後,會提示:
*sys-package-mgr*: can't create package cache dir, *jython-2.2.jar\cachedir\packages'
這個可以不用管,不會影響程序運行。