優化應用程序代碼的內存使用並不是一個新主題,但是人們通常並沒有很好地理解這個主題。本文將簡要介紹 Java 進 程的內存使用,隨後深入探討您編寫的 Java 代碼的內存使用。最後,本文將展示提高代碼內存效率的方法,特別強調了 HashMap 和 ArrayList 等 Java 集合的使用。
背景信息:Java 進程的內存使用
通過在命令行中執行 java 或者啟動某種基於 Java 的中間件來運行 Java 應用程序時,Java 運行時會創建一個操作系統進程,就像您運行基於 C 的 程序時那樣。實際上,大多數 JVM 都是用 C 或者 C++ 語言編寫的。作為操作系統進程,Java 運行時面臨著與其他進程完 全相同的內存限制:架構提供的尋址能力以及操作系統提供的用戶空間。
架構提供的內存尋址能力依賴於處理器的 位數,舉例來說,32 位或者 64 位,對於大型機來說,還有 31 位。進程能夠處理的位數決定了處理器能尋址的內存范圍 :32 位提供了 2^32 的可尋址范圍,也就是 4,294,967,296 位,或者說 4GB。而 64 位處理器的可尋址范圍明顯增大: 2^64,也就是 18,446,744,073,709,551,616,或者說 16 exabyte(百億億字節)。
處理器架構提供的部分可尋址 范圍由 OS 本身占用,提供給操作系統內核以及 C 運行時(對於使用 C 或者 C++ 編寫的 JVM 而言)。OS 和 C 運行時占 用的內存數量取決於所用的 OS,但通常數量較大:Windows 默認占用的內存是 2GB。剩余的可尋址空間(用術語來表示就 是用戶空間)就是可供運行的實際進程使用的內存。
對於 Java 應用程序,用戶空間是 Java 進程占用的內存,實 際上包含兩個池:Java 堆和本機(非 Java)堆。Java 堆的大小由 JVM 的 Java 堆設置控制:-Xms 和 -Xmx 分別設置最 小和最大 Java 堆。在按照最大的大小設置分配了 Java 堆之後,剩下的用戶空間就是本機堆。圖 1 展示了一個 32 位 Java 進程的內存布局:
圖 1. 一個 32 位 Java 進程的內存布局示例

在 圖 1 中,可尋址范圍總共有 4GB,OS 和 C 運行時大約占用了其中的 1GB,Java 堆占用了將近 2GB,本機堆占用了其他部分。請注意,JVM 本身也要占用內存,就 像 OS 內核和 C 運行時一樣,而 JVM 占用的內存是本機堆的子集。
Java 對象詳解
在您的 Java 代碼使用 new 操作符創建一個 Java 對象的實例時,實際上分配的數據要比您想的多得多。例如,一個 int 值與一個 Integer 對象 (能包含 int 值的最小對象)的大小比率是 1:4,這個比率可能會讓您感到吃驚。額外的開銷源於 JVM 用於描述 Java 對 象的元數據,在本例中也就是 Integer。
根據 JVM 的版本和供應的不同,對象元數據的數量也各有不同,但其中通 常包括:
類:一個指向類信息的指針,描述了對象類型。舉例來說,對於 java.lang.Integer 對象,這是 java.lang.Integer 類的一個指針。
標記:一組標記,描述了對象的狀態,包括對象的散列碼(如果有),以及對象的形狀(也就是說,對象是否是數組) 。
鎖:對象的同步信息,也就是說,對象目前是否正在同步。
對象元數據後緊跟著對象數據本身,包括對象實例中存儲的字段。對於 java.lang.Integer 對象,這就是一個 int。
如果您正在運行一個 32 位 JVM,那麼在創建 java.lang.Integer 對象實例時,對象的布局可能如圖 2 所示:
圖 2. 一個 32 位 Java 進程的 java.lang.Integer 對象的布局示例

如 圖 2 所示,有 128 位的數據被占用,其 中用於存儲 int 值的為 32 位,而對象元數據占用了其余的 96 位。
Java 數組對象詳解
數組對象(例如 一個 int 值數組)的形狀和結構與標准 Java 對象相似。主要差別在於數組對象包含說明數組大小的額外元數據。因此, 數據對象的元數據包括:
類:一個指向類信息的指針,描述了對象類型。舉例來說,對於 int 字段數組,這是 int[] 類的一個指針。
標記:一組標記,描述了對象的狀態,包括對象的散列碼(如果有),以及對象的形狀(也就是說,對象是否是數組) 。
鎖:對象的同步信息,也就是說,對象目前是否正在同步。
大小:數組的大小。
圖 3 展示了一個 int 數組對象的布局示例:
圖 3. 一個 32 位 Java 進程的 int 數組對象的布局示例

如 圖 3 所示, 有 160 位的數據用於存儲 int 值內的 32 位數據,而數組元數據占用了其余 160 位。對於 byte、int 和 long 等原語, 從內存的方面考慮,單項數組比對應的針對單一字段的包裝器對象(Byte、Integer 或 Long)的成本更高。
更為復 雜數據結構詳解
良好的面向對象設計與編程鼓勵使用封裝(提供接口類來控制數據訪問)和委托(使用 helper 對 象來實施任務)。封裝和委托會使大多數數據結構的表示形式中包含多個對象。一個簡單的示例就是 java.lang.String 對 象。java.lang.String 對象中的數據是一個字符數組,由管理和控制對字符數組的訪問的 java.lang.String 對象封裝。 圖 4 展示了一個 32 位 Java 進程的java.lang.String 對象的布局示例:
圖 4. 一個 32 位 Java 進程的 java.lang.String 對象的布局示例
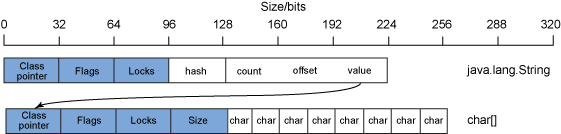
如 圖 4 所示,除了標准對象元數據之外, java.lang.String 對象還包含一些用於管理字符串數據的字段。通常情況下,這些字段是散列值、字符串大小計數、字符 串數據偏移量和對於字符數組本身的對象引用。
這也就意味著,對於一個 8 個字符的字符串(128 位的 char 數據 ),需要有 256 位的數據用於字符數組,224 位的數據用於管理該數組的 java.lang.String 對象,因此為了表示 128 位 (16 個字節)的數據,總共需要占用 480 位(60 字節)。開銷比例為 3.75:1。
總體而言,數據結構越是復雜, 開銷就越高。下一節將具體討論相關內容。
32 位和 64 位 Java 對象
之前的示例中的對象大小和開銷適用 於 32 位 Java 進程。在 背景信息:Java 進程的內存使用 一節中提到,64 位處理器的內存可尋址能力比 32 位處理器高 得多。對於 64 位進程,Java 對象中的某些數據字段的大小(特別是對象元數據或者表示另一個對象的任何字段)也需要 增加到 64 位。其他數據字段類型(例如 int、byte 和 long )的大小不會更改。圖 5 展示了一個 64 位 Integer 對象 和一個 int 數組的布局:
圖 5. 一個 64 位進程的 java.lang.Integer 對象和 int 數組的布局示例
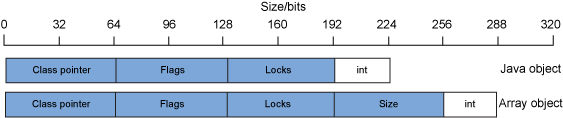
圖 5 表明,對 於一個 64 位 Integer 對象,現在有 224 位的數據用於存儲 int 字段所用的 32 位,開銷比例是 7:1。對於一個 64 位 單元素 int 數組,有 288 位的數據用於存儲 32 位 int 條目,開銷比例是 9:1。這在實際應用程序中產生的影響在於, 之前在 32 位 Java 運行時中運行的應用程序若遷移到 64 位 Java 運行時,其 Java 堆內存使用量會顯著增加。通常情況 下,增加的數量是原始堆大小的 70% 左右。舉例來說,一個在 32 位 Java 運行時中使用 1GB Java 堆的 Java 應用程序 在遷移到 64 位 Java 運行時之後,通常需要使用 1.7GB 的 Java 堆。
請注意,這種內存增加並非僅限於 Java 堆。本機堆內存區使用量也會增加,有時甚至要增加 90% 之多。
表 1 展示了一個應用程序在 32 位和 64 位模式 下運行時的對象和數組字段大小:
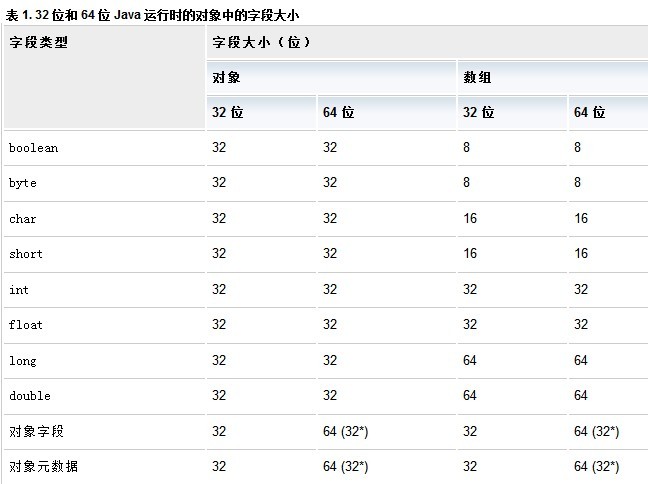
* 對象字段的大小以及用於各對象元數據條目的 數據的大小可通過 壓縮引用或壓縮 OOP 技術減小到 32 位。
壓縮引用和壓縮普通對象指針 (OOP)
IBM 和 Oracle JVM 分別通過壓縮引用 (-Xcompressedrefs) 和壓縮 OOP (-XX:+UseCompressedOops) 選項提供對象引用壓縮功能 。利用這些選項,即可在 32 位(而非 64 位)中存儲對象字段和對象元數據值。在應用程序從 32 位 Java 運行時遷移到 64 位 Java 運行時的時候,這能消除 Java 堆內存使用量增加 70% 的負面影響。請注意,這些選項對於本機堆的內存使用 無效,本機堆在 64 位 Java 運行時中的內存使用量仍然比 32 位 Java 運行時中的使用量高得多。
Java 集合的 內存使用
在大多數應用程序中,大量數據都是使用核心 Java API 提供的標准 Java Collections 類來存儲和管理 的。如果內存占用對於您的應用程序極為重要,那麼就非常有必要了解各集合提供的功能以及相關的內存開銷。總體而言, 集合功能的級別越高,內存開銷就越高,因此使用提供的功能多於您需要的功能的集合類型會帶來不必要的額外內存開銷。
其中部分最常用的集合如下:
HashSet
HashMap
Hashtable
LinkedList
ArrayList
除了 HashSet 之外,此列表是按功能和內存開銷進行降序排列的。(HashSet 是包圍一個 HashMap 對象的包裝器,它 提供的功能比 HashMap 少,同時容量稍微小一些。)
Java 集合:HashSet
HashSet 是 Set 接口的實現。 Java Platform SE 6 API 文檔對於 HashSet 的描述如下:
一個不包含重復元素的集合。更正式地來說,set(集)不包含元素 e1 和 e2 的配對 e1.equals(e2),而且至多包含一個 空元素。正如其名稱所表示的那樣,這個接口將建模數學集抽象。
HashSet 包含的功能比 HashMap 要少,只能包含一個空條目,而且無法包含重復條目。該實現是包圍 HashMap 的一個 包裝器,以及管理可在 HashMap 對象中存放哪些內容的 HashSet 對象。限制 HashMap 功能的附加功能表示 HashSet 的內 存開銷略高。
圖 6 展示了 32 位 Java 運行時中的一個 HashSet 的布局和內存使用:
圖 6. 32 位 Java 運行時中的一個 HashSet 的內存使用和布局

圖 6 展示了一個 java.util.HashSet 對象 的 shallow 堆(獨立對象的內存使用)以及保留堆(獨立對象及其子對象的內存使用),以字節為單位。shallow 堆的大 小是 16 字節,保留堆的大小是 144 字節。創建一個 HashSet 時,其默認容量(也就是該集中可以容納的條目數量)將設 置為 16 個條目。按照默認容量創建 HashSet,而且未在該集中輸入任何條目時,它將占用 144 個字節。與 HashMap 的內 存使用相比,超出了 16 個字節。表 2 顯示了 HashSet 的屬性:

Java 集合: HashMap
HashMap 是 Map 接口的實現。Java Platform SE 6 API 文檔對於 HashMap 的描述如下:
一個將鍵映射到值的對象。一個映射中不能包含重復的鍵;每個鍵僅可映射到至多一個值。
HashMap 提供了一種存儲鍵/值對的方法,使用散列函數將鍵轉換為存儲鍵/值對的集合中的索引。這允許快速訪問數據 位置。允許存在空條目和重復條目;因此,HashMap 是 HashSet 的簡化版。
HashMap 將實現為一個 HashMap$Entry 對象數組。圖 7 展示了 32 位 Java 運行時中的一個 HashMap 的內存使用和布局:
圖 7. 32 位 Java 運行時中的 一個 HashMap 的內存使用和布局

如 圖 7 所示,創建一個 HashMap 時,結果 是一個 HashMap 對象以及一個采用 16 個條目的默認容量的 HashMap$Entry 對象數組。這提供了一個 HashMap,在完全為 空時,其大小是 128 字節。插入 HashMap 的任何鍵/值對都將包含於一個 HashMap$Entry 對象之中,該對象本身也有一定 的開銷。
大多數 HashMap$Entry 對象實現都包含以下字段:
int KeyHash
Object next
Object key
Object value
一個 32 字節的 HashMap$Entry 對象用於管理插入集合的數據鍵/值對。這就意味著,一個 HashMap 的總開銷包含 HashMap 對象、一個 HashMap$Entry 數組條目和與各條目對應的 HashMap$Entry 對象的開銷。可通過以下公式表示:
HashMap 對象 + 數組對象開銷 + (條目數量 * (HashMap$Entry 數組條目 + HashMap$Entry 對象))
對於一個包含 10,000 個條目的 HashMap 來說,僅僅 HashMap、HashMap$Entry 數組和 HashMap$Entry 對象的開銷就 在 360K 左右。這還沒有考慮所存儲的鍵和值的大小。
表 3 展示了 HashMap 的屬性:

Java 集合:Hashtable
Hashtable 與 HashMap 相似,也是 Map 接口的實現。Java Platform SE 6 API 文檔對於 Hashtable 的描述如下:
這個類實現了一個散列表,用於將鍵映射到值。對於非空對象,可以將它用作鍵,也可以將它用作值。
Hashtable 與 HashMap 極其相似,但有兩項限制。無論是鍵還是值條目,它均不接受空值,而且它是一個同步集合。相 比之下,HashMap 可以接受空值,且不是同步的,但可以利用 Collections.synchronizedMap() 方法來實現同步。
Hashtable 的實現同樣類似於 HashMap,也是條目對象的數組,在本例中即 Hashtable$Entry 對象。圖 8 展示了 32 位 Java 運行時中的一個 Hashtable 的內存使用和布局:
圖 8. 32 位 Java 運行時中的一個 Hashtable 的內存使用和布局

圖 8 顯示,創建一個 Hashtable 時,結果 會是一個占用了 40 字節的內存的 Hashtable 對象,另有一個默認容量為 11 個條目的 Hashtable$entry 數組,在 Hashtable 為空時,總大小為 104 字節。
Hashtable$Entry 存儲的數據實際上與 HashMap 相同:
int KeyHash
Object next
Object key
Object value
這意味著,對於 Hashtable 中的鍵/值條目,Hashtable$Entry 對象也是 32 字節,而 Hashtable 開銷的計算和 10K 個條目的集合的大小(約為 360K)與 HashMap 類似。
表 4 顯示了 Hashtable 的屬性:

如您所見,Hashtable 的默認容量比 HashMap 要稍微小一些(分別是 11 與 16)。除此之外,兩者之間的主要 差別在於 Hashtable 無法接受空鍵和空值,而且是默認同步的,但這可能是不必要的,還有可能降低集合的性能。
Java 集合:LinkedList
LinkedList 是 List 接口的鏈表實現。Java Platform SE 6 API 文檔對於 LinkedList 的描述如下:
一種有序集合(也稱為序列)。此接口的用戶可以精確控制將各元素插入列表時的位置。用戶可以按照整數索引(代表在列 表中的位置)來訪問元素,也可以搜索列表中的元素。與其他集合 (set) 不同,該集合 (collection) 通常允許存在重復 的元素。
實現是 LinkedList$Entry 對象鏈表。圖 9 展示了 32 位 Java 運行時中的 LinkedList 的內存使用和布局:
圖 9. 32 位 Java 運行時中的一個 LinkedList 的內存使用和布局

圖 9 表明,創建一個 LinkedList 時,結果 將得到一個占用 24 字節內存的 LinkedList 對象以及一個 LinkedList$Entry 對象,在 LinkedList 為空時,總共占用的 內存是 48 個字節。
鏈表的優勢之一就是能夠准確調整其大小,且無需重新調整。默認容量實際上就是一個條目, 能夠在添加或刪除條目時動態擴大或縮小。每個 LinkedList$Entry 對象仍然有自己的開銷,其數據字段如下:
Object previous
Object next
Object value
但這比 HashMap 和 Hashtable 的開銷低,因為鏈表僅存儲單獨一個條目,而非鍵/值對,由於不會使用基於數組的查找 ,因此不需要存儲散列值。從負面角度來看,在鏈表中查找的速度要慢得多,因為鏈表必須依次遍歷才能找到需要查找的正 確條目。對於較大的鏈表,結果可能導致漫長的查找時間。
表 5 顯示了 LinkedList 的屬性:

Java 集合:ArrayList
ArrayList 是 List 接口的可變長數組實現。Java Platform SE 6 API 文檔對於 ArrayList 的描述如下:
一種有序集合(也稱為序列)。此接口的用戶可以精確控制將各元素插入列表時的位置。用戶可以按照整數索引(代表在列 表中的位置)來訪問元素,也可以搜索列表中的元素。與其他集合 (set) 不同,該集合 (collection) 通常允許存在重復 的元素。
不同於 LinkedList,ArrayList 是使用一個 Object 數組實現的。圖 10 展示了一個 32 位 Java 運行時中的 ArrayList 的內存使用和布局:
圖 10. 32 位 Java 運行時中的一個 ArrayList 的內存使用和布局

圖 10 表明,在 創建 ArrayList 時,結果將得到一個占用 32 字節內存的 ArrayList 對象,以及一個默認大小為 10 的 Object 數組,在 ArrayList 為空時,總計占用的內存是 88 字節。這意味著 ArrayList 無法准確調整大小,因此擁有一個默認容量,恰好 是 10 個條目。
表 6 展示了一個 ArrayList 的屬性:

其他類型的 “集合”
除了標准集合之外 ,StringBuffer 也可以視為集合,因為它管理字符數據,而且在結構和功能上與其他集合相似。Java Platform SE 6 API 文檔對於 StringBuffer 的描述如下:
線程安全、可變的字符序列……每個字符串緩沖區都有相應的容量。只要字符串緩沖區內包含的字符序列的長度不超過容量 ,就不必分配新的內部緩沖區數組。如果內部緩沖區溢出,則會自動為其擴大容量。
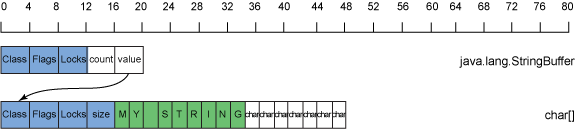
StringBuffer 是作為一個 char 數組來實現的。圖 11 展示了一個 32 位 Java 運行時中的 StringBuffer 的內存使用 和布局:
圖 11. 32 位 Java 運行時中的一個 StringBuffer 的內存使用和布局

圖 11 展示,創建一個 StringBuffer 時, 結果將得到一個占用 24 字節內存的 StringBuffer 對象,以及一個默認大小為 16 的字符數組,在 StringBuffer 為空時 ,數據總大小為 72 字節。
與集合相似,StringBuffer 擁有默認容量和重新調整大小的機制。表 7 顯示了 StringBuffer 的屬性:

集合中的空白空間
擁有給定數量對象的各 種集合的開銷並不是內存開銷的全部。前文的示例中的度量假設集合已經得到了准確的大小調整。然而,對於大多數集合來 說,這種假設都是不成立的。大多數集合在創建時都指定給定的初始容量,數據將置入集合之中。這也就是說,集合擁有的 容量往往大於集合中存儲的數據容量,這造成了額外的開銷。
考慮一個 StringBuffer 的示例。其默認容量是 16 個字符條目,大小為 72 字節。初始情況下,72 個字節中未存儲任何數據。如果您在字符數組中存儲了一些字符,例如 "MY STRING" ,那麼也就是在 16 個字符的數組中存儲了 9 個字符。圖 12 展示了 32 位 Java 運行時中的一 個包含 "MY STRING" 的 StringBuffer 的內存使用和布局:
圖 12. 32 位 Java 運行時中的一個包含 "MY STRING" 的 StringBuffer 的內存使用
如 圖 12 所示,數組中有 7 個可用的字符 條目未被使用,但占用了內存,在本例中,這造成了 112 字節的額外開銷。對於這個集合,您在 16 的容量中存儲了 9 個 條目,因而填充率 為 0.56。集合的填充率越低,因多余容量而造成的開銷就越高。
集合的擴展和重新調整
在集合達到容量限制時,如果出現了在集合中存儲額外條目的請求,那麼會重新調整集合,並擴展它以容納新條目。這將增 加容量,但往往會降低填充比,造成更高的內存開銷。
各集合所用的擴展算法各有不同,但一種通用的做法就是將 集合的容量加倍。這也是 StringBuffer 采用的方法。對於前文示例中的 StringBuffer,如果您希望將 " OF TEXT" 添加到緩沖區中,生成 "MY STRING OF TEXT",則需要擴展集合,因為新的字符集合擁有 17 個條 目,當前容量 16 無法滿足其要求。圖 13 展示了所得到的內存使用:
圖 13. 32 位 Java 運行時中的一個包含 "MY STRING OF TEXT" 的 StringBuffer 的內存使用
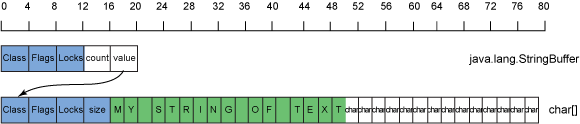
現在,如 圖 13 所示,您得到了一個 32 個 條目的字符數組,但僅僅使用了 17 個條目,填充率為 0.53。填充率並未顯著下滑,但您現在需要為多余的容量付出 240 字節的開銷。
對於小字符串和集合,低填充率和多余容量的開銷可能並不會被視為嚴重問題,而在大小增加時,這 樣的問題就會愈加明顯,代價也就愈加高昂。例如,如果您創建了一個 StringBuffer,其中僅包含 16MB 的數據,那麼( 在默認情況下)它將使用大小設置為可容納 32MB 數據的字符數組,這造成了以多余容量形式存在的 16MB 的額外開銷。
Java 集合:匯總
表 8 匯總了集合的屬性:
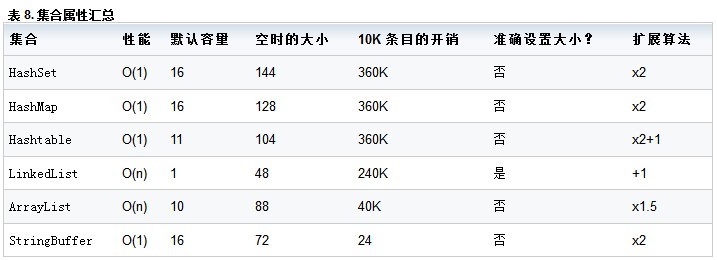
Hash 集合的性能比任何 List 的性能都要高,但每條目的成本也要更高。由於訪問性能方面的原因,如果您正在創建大集合(例如,用於實現緩存 ),那麼最好使用基於 Hash 的集合,而不必考慮額外的開銷。
對於並不那麼注重訪問性能的較小集合而言,List 則是合理的選擇。ArrayList 和 LinkedList 集合的性能大體相同,但其內存占用完全不同:ArrayList 的每條目大小要比 LinkedList 小得多,但它不是准確設置大小的。List 要使用的正確實現是 ArrayList 還是 LinkedList 取決於 List 長 度的可預測性。如果長度未知,那麼正確的選擇可能是 LinkedList,因為集合包含的空白空間更少。如果大小已知,那麼 ArrayList 的內存開銷會更低一些。
選擇正確的集合類型使您能夠在集合性能與內存占用之間達到合理的平衡。除 此之外,您可以通過正確調整集合大小來最大化填充率、最小化未得到利用的空間,從而最大限度地減少內存占用。
集合的實際應用:PlantsByWebSphere 和 WebSphere Application Server Version 7
在 表 8 中,創建一 個包含 10,000 個條目、基於 Hash 的集合的開銷是 360K。考慮到,復雜的 Java 應用程序常常使用大小為數 GB 的 Java 堆運行,因此這樣的開銷看起來並不是非常高,當然,除非使用了大量集合。
表 9 展示了在包含五個用戶的負載測 試中運行 WebSphere Application Server Version 7 提供的 PlantsByWebSphere 樣例應用程序時,Java 堆使用的 206MB 中的集合對象使用量:

通過 表 9 可以看到,這裡使用了超過 30 萬個 不同的集合,而且僅集合本身(不考慮其中包含的數據)就占用了 206MB 的 Java 堆用量中的 42.9MB(21%)。這就意味 著,如果您能更改集合類型,或者確保集合的大小更加准確,那麼就有可能實現可觀的內存節約。
通過 Memory Analyzer 查找低填充率
IBM Java 監控和診斷工具(Memory Analyzer 工具是在 IBM Support Assistant 中提供的 )可以分析 Java 集合的內存使用情況(請參閱 參考資料 部分)。其功能包括分析集合的填充率和大小。您可以使用這樣 的分析來識別需要優化的集合。
Memory Analyzer 中的集合分析位於 Open Query Browser -> Java Collections 菜單中,如圖 14 所示:
圖 14. 在 Memory Analyzer 中分析 Java 集合的填充率
在判斷當前大小 超出需要的大小的集合時,圖 14 中選擇的 Collection Fill Ratio 查詢是最有用的。您可以為該查詢指定多種選項,這 些選項包括:
對象:您關注的對象類型(集合)
分段:用於分組對象的填充率范圍
將對象選項設置為 "java.util.Hashtable"、將分段選項設置為 "10",之後運行查詢將得到如圖 15 所示的輸出結果:
圖 15. 在 Memory Analyzer 中對 Hashtable 的填充率分析
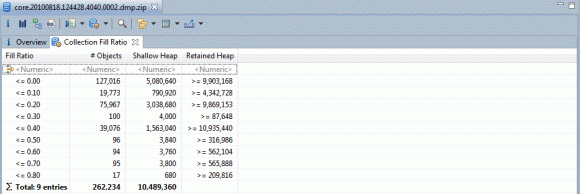
圖 15 表明,在 java.util.Hashtable 的 262,234 個實例中,有 127,016 (48.4%) 的實例完全未空,幾乎所有實例都僅包含少量條目。
隨後便可識別這些集合,方法是選擇結果表中的一行,右鍵單擊並選擇 list objects -> with incoming references,查看哪些對象擁有這些集合,或者選擇 list objects -> with outgoing references,查看這些集合中包 含哪些條目。圖 16 展示了查看對於空 Hashtable 的傳入引用的結果,圖中展開了一些條目:
圖 16. 在 Memory Analyzer 中對於空 Hashtable 的傳入引用的分析
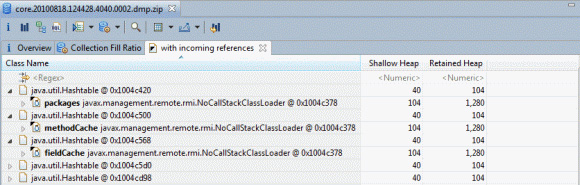
圖 16 表明,某些空 Hashtable 歸 javax.management.remote.rmi.NoCallStackClassLoader 代碼所有。
通過查看 Memory Analyzer 左側面板中的 Attributes 視圖,您就可以看到有關 Hashtable 本身的具體細節,如圖 17 所示:
圖 17. 在 Memory Analyzer 中檢查空 Hashtable
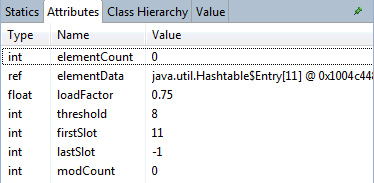
圖 17 表明,Hashtable 的大小為 11(默認 大小),而且完全是空的。
對於 javax.management.remote.rmi.NoCallStackClassLoader 代碼,可以通過以下方 法來優化集合使用:
延遲分配 Hashtable:如果 Hashtable 為空是經常發生的普遍現象,那麼僅在存在需要存儲的數據時分配 Hashtable 應該是一種合理的做法。
將 Hashtable 分配為准確的大小:由於使用默認大小,因此完全可以使用更為准確的初始大小。
這些優化是否適用取決於代碼的常用方式以及通常存儲的是哪些數據。
PlantsByWebSphere 示例中的空集合
表 10 展示了分析 PlantsByWebSphere 示例中的集合來確定哪些集合為空時的分析結果:

表 10 表明,平均而言,超過 50% 的集合為空, 也就是說通過優化集合使用能夠實現可觀的內存占用節約。這種優化可以應用於應用程序的各個級別:應用於 PlantsByWebSphere 示例代碼中、應用於 WebSphere Application Server 中,以及應用於 Java 集合類本身。
在 WebSphere Application Server 版本 7 與版本 8 之間,我們做出了一些努力來改進 Java 集合和中間件層的內存效率。 舉例來說,java.util.WeahHashMap 實例的開銷中,有很大一部分比例源於其中包含用來處理弱引用的 java.lang.ref.ReferenceQueue 實例。圖 18 展示了 32 位 Java 運行時中的一個 WeakHashMap 的內存布局:
圖 18. 32 位 Java 運行時中的一個 WeakHashMap 的內存布局
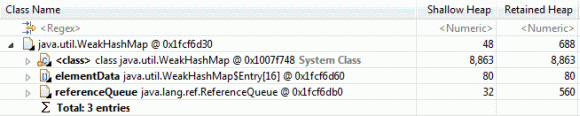
圖 18 表明,ReferenceQueue 對象負責保留 占用 560 字節的數據,即便在 WeakHashMap 為空、不需要 ReferenceQueue 的情況下也是如此。對於 PlantsByWebSphere 示例來說,在空 WeakHashMap 的數量為 19,465 的情況下,ReferenceQueue 對象將額外增加 10.9MB 的非必要數據。在 WebSphere Application Server 版本 8 和 IBM Java 運行時的 Java 7 發布版中,WeakHashMap 得到了一定的優化:它包 含一個 ReferenceQueue,這又包含一個 Reference 對象數組。該數組已經更改為延遲分配,也就是說,僅在向 ReferenceQueue 添加了對象的情況下執行分配。
結束語
在任何給定應用程序中,都存在著數量龐大(或許 達到驚人的程度)的集合,復雜應用程序中的集合數量可能會更多。使用大量集合往往能夠提供通過選擇正確的集合、正確 地調整其大小(或許還能通過延遲分配集合)來實現有時極其可觀的內存占用節約的范圍。這些決策最好在設計和開發的過 程中制定,但您也可以利用 Memory Analyzer 工具來分析現有應用程序中存在內存占用優化潛力的部分。