隨著內容管理應用程序的日益普及,對於公共的、標准的內容倉庫 API 的需求也變得漸漸明顯起來。Content Repository for Java ™ Technology API(JSR-170)的目標就是提供這樣一個接口。在這篇文章中,我將用開放源碼的 JSR-170 實現 Apache Jackrabbit,設計一個簡單的類似維京百科全書的後端,研究這個前途遠大的框架所提供的特性。
如果曾經試過開發內容管理應用程序,那麼您應當非常清楚在實現內容系統時所遇到的固有難題。這個領地有點支離破碎,許多供應商都有自己的私有倉庫引擎。這些困難惡化了這類系統的復雜性和可維護性、增強了廠商鎖定、增加了企業市場中對傳統系統長期支持的需要。隨著企業 weblog 和電子企業文檔管理的日益流行,對標准化內容倉庫接口的需求比以往任何時候都更加顯著。
Content Repository for Java Technology 規范是在 Java Community Process 中作為 JSR-170 開發的,它的目標是滿足這些行業的需求。該規范在 javax.jcr 名稱空間中提供了統一的 API ,允許以廠商中立的方式訪問任何符合規范的倉庫實現。
但是 API 標准化並不是 Java Content Repository(JCR)帶來的惟一特性。JSR-170 的一個主要優勢就是沒有捆綁到任何特定的底層架構上。例如,JSR-170 實現的後端數據存儲可以是文件系統、WebDAV 倉庫、XML 支持的系統或者是 SQL 數據庫。而且,JSR-170 的導出和導入功能允許集成人員在後端內容和 JCR 實現之間無縫地切換。最後,JCR 提供了簡單的接口,可以將該接口放在各種現有的內容倉庫之上,並同時標准化一些復雜的功能(例如版本管理、訪問控制和搜索)。
在討論 JCR 時,有幾種方式可以采用。在這篇文章中,我從開發人員的角度來研究 JSR-170 規范所提供的特性,重點放在可用的 API 和接口上,這些接口允許程序員在設計內容應用程序時有效利用 JSR-170 倉庫。作為一個假設的示例,我將為一個類似維京百科全書的、叫做 JCRWiki 的系統實現一個小小的後端,為二進制內容、版本管理、備份和搜索提供支持。我使用 Apache Jackrabbit(JSR-170 的開源實現)開發這個應用程序。
倉庫模型
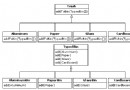
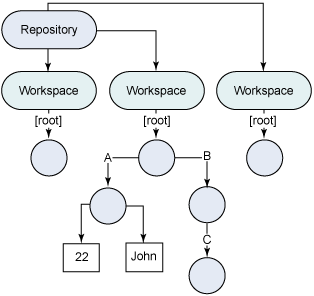
我先從對倉庫模型的高級討論開始,以便讓您熟悉 JCR。倉庫模型是簡單的層次結構,看起來就像一個有 n 個分叉的樹。它由單一內容倉庫構成,有一個或多個工作區。(這篇文章中的討論僅限制於單一工作區。)每個工作區都包含一個項目 樹;項目既可以是節點 也可以是屬性。節點可以有零個或多個子節點以及零個或多個相關屬性,實際的內容保存在子節點和屬性中。
每個節點都有且只有一個主節點類型。主節點類型定義了節點的特征,例如允許節點擁有的屬性和子節點。除了主節點類型之外,節點還可以有一個或多個混合(mixin)類型。混合類型更像修飾器,向節點提供額外的特征。具體來說,JCR 實現可以提供三種預定義混合類型:
mix:versionable:允許節點支持版本管理
mix:lockable:支持節點的鎖定功能
mix:referenceable:提供自動創建的 jcr:uuid 屬性,給節點一個惟一可以引用的標識符
這個結構如圖 1 所示。圓圈代表節點,矩形代表屬性。請參見節點 A、B 和 C,它們都衍生自一個根節點。節點 A 有兩個屬性,即一個字符串 “John” 和一個整數 22。
圖 1. 有多個工作區的倉庫模型
預定義的節點類型
每個倉庫都必須支持主節點類型 nt:base。倉庫還可以支持其他許多公共節點類型:
nt:unstructured 是最靈活的節點類型。它允許使用任意數量的子節點或屬性,並且可以使用任意名稱。這個節點類型表示 JCRWiki 的條目。
nt:file 表示文件。它需要一個叫做 jcr:content 的單一子節點。這個節點類型表示 JCRWiki 條目中的圖片和其他二進制內容。
nt:folder 節點類型可以表示文件夾,就像常規的文件系統中的文件夾一樣。
nt:resource 通常表示文件的實際內容。
nt:version 是支持版本管理的倉庫所必需的節點類型。
整個節點類型的結構可以在 JSR-170 規范的 6.7.22.1 小節找到。
名稱空間
倉庫模型一個有用的卻經常被忽視的特性就是它對名稱空間 的支持。名稱空間防止不同來源和不同應用程序域之間的項目和節點類型的命名沖突。名稱空間被定義為帶有一個前綴,中間用一個 : (冒號)分隔。在這篇文章的教程中,已經遇到了一些名稱空間:jcr 用於 JCR 的內部屬性,mix 用於混合類型,nt 用於節點類型。在 JCRWiki 中,所有的數據都將使用 wiki 名稱空間。
安裝 JCR
在編寫這篇文章的時候,Apache Jackrabbit(即 Apache 基金會的 JSR-170 的開源實現)的發行版已經到了版本 1.0。編譯好的字節碼 JAR 可以直接從 Jackrabbit Web 站點下載。雖然 Jackrabbit can 仍然可以用 SVN 從源代碼進行編譯,但是 Jackrabbit 庫已經非常穩定,不再需要每夜構建(nightly builds)技術。這一節將提供盡可能快地安裝 JCR 實現並運行它的詳細說明。
需要的庫
要使用和運行這篇文章中的示例,請將下面這些庫放在類路徑中:
jackrabbit-core:針對 JSR-170 的 Jackrabbit 內容倉庫核心實現和來自 Apache 的公共實用代碼。
commons-collections:包含強大數據結構的框架,該框架可以加快 Java 應用程序的開發。
concurrent:這個庫提供通常在 Java 並發編程中會遇到的工具類的標准化的、有效率的版本。
derby:一個 Apache 數據庫子項目,它提供完全用 Java 語言實現的關系數據庫。
jcr:一組符合 JSR-170 規范的接口。
log4j:運行時日志庫。
lucene:高性能的全功能文本搜索引擎庫。
slf4j (針對 Java 的簡單日志 Facade):目的是充當不同日志 API 的簡單 facade,允許用戶在部署時插入需要的實現。
xerces:高級 XML 解析器,支持 SAX 版本 2、DOM 1 級和 SAX 版本 1 API。
如果用 SVN 構建 Jackrabbit,那麼所有這些 JAR 文件都會在 Jackrabbit 構建過程中被下載,並位於 Maven 的緩存目錄中。在 Linux 下,這些 JAR 位於主目錄的 .maven 目錄下。如果使用二進制構建,那麼只需要從它們各自的 Web 站點下載其二進制版或浏覽 Jackrabbit Web 站點的 “First Hops with Jackrabbit” 即可,那裡會提供到所有這些資源的直接鏈接。在 JSR-170 規范的下載中還有一個 jcr-1.0.jar,在 Java 社區進程的 Web 站點上也可以找到它。
手工配置
JSR-170 沒有確切地指定應當如何獲得初始的 Repository 對象;這被留作每個倉庫廠商的實現細節。但是,在應用程序中最好使用 JNDI 或其他容器環境中的配置機制,這樣可以保持 JSR-170 的實現相對獨立於對 Jackrabbit 的直接依賴項。雖然這一策略在初始配置期間造成了額外的復雜性,但它提供了跨不同 JSR-170 實現的更好的移植性。要想獲得一個移植性雖然差但得到了簡化的配置,可以使用自動配置,詳細內容在這篇文章後面部分介紹。
在手工配置中,可以將 JNDI 與配置文件(叫做 repository.xml,以編程方式載入)結合使用來得到倉庫。
倉庫配置
第一步,也是最容易的一步,就是為 Jackrabbit 創建 repository.xml 文件。這個配置文件實現了許多重要任務。這些任務包括:指定底層的後端存儲、訪問控制機制、可用的工作區、版本管理系統和搜索子系統。清單 1 提供了一個示例:
清單 1. 示例 repository.xml 配置文件
<?xml version="1.0" encoding="ISO-8859-1"?>
<Repository>
<FileSystem
class="org.apache.jackrabbit.core.fs.local.LocalFileSystem">
<param name="path" value="${rep.home}/repository"/>
</FileSystem>
<Security appName="Jackrabbit">
<AccessManager
class="org.apache.jackrabbit.core.security.
SimpleAccessManager"/>
</Security>
<Workspaces
rootPath="${rep.home}/workspaces"
defaultWorkspace="default" />
<Workspace name="${wsp.name}">
<FileSystem
class="org.apache.jackrabbit.core.fs.local.
LocalFileSystem">
<param name="path" value="${wsp.home}"/>
</FileSystem>
<PersistenceManager
class="org.apache.jackrabbit.core.state.xml.
XMLPersistenceManager" />
<SearchIndex
class="org.apache.jackrabbit.core.query.lucene.
SearchIndex">
<param name="path" value="${wsp.home}/index" />
</SearchIndex>
</Workspace>
<Versioning rootPath="${rep.home}/versions">
<FileSystem
class="org.apache.jackrabbit.core.fs.local.
LocalFileSystem">
<param name="path" value="${rep.home}/versions"/>
</FileSystem>
<PersistenceManager
class="org.apache.jackrabbit.core.state.xml.
XMLPersistenceManager" />
</Versioning>
</Repository>
這個配置使用本地文件系統來保存倉庫數據,用 SimpleAccessManager 進行訪問控制。文件剩下的部分基本是自解釋的,將它們原樣復制到自己的倉庫目錄中即可。
安全性配置
使用 JASS 配置文件 jaas.config(存放在項目的根目錄中),可以提供初步的安全性。清單 2 提供了一個示例:
清單 2. 示例 JAAS 配置
Jackrabbit {
org.apache.jackrabbit.core.security.SimpleLoginModule required
anonymousId="anonymous";
};
倉庫初始化代碼
清單 3 描述的包可在初始化倉庫時使用:
清單 3. 手工配置的初始化 import 語句
import org.apache.jackrabbit.core.jndi.RegistryHelper;
import javax.naming.Context;
import javax.naming.InitialContext;
import javax.naming.NamingException;
import javax.jcr.*;
import javax.jcr.query.*;
import javax.jcr.version.*;
import java.util.Hashtable;
import java.util.Calendar;
import java.io.*;
import sun.net.www.MimeTable;
要得到 Repository 對象,請將 configFile 變量設置成指向 repository.xml 文件,將 repHomeDir 變量設置成指向倉庫所在的本地文件系統目錄。當結合 RegistryHelper 使用 JNDI 時,獲得倉庫非常簡單,如清單 4 所示:
清單 4. 用 JNDI 獲得 repository 對象
String configFile = "repository.xml";
String repHomeDir = "repository";
Hashtable env = new Hashtable();
env.put(Context.INITIAL_CONTEXT_FACTORY,
"org.apache.jackrabbit.core.jndi" +
".provider.DummyInitialContextFactory");
env.put(Context.PROVIDER_URL, "localhost");
InitialContext ctx = new InitialContext(env);
RegistryHelper.registerRepository(ctx,
"repo",
configFile,
repHomeDir,
true);
Repository r = (Repository) ctx.lookup("repo");
接下來,用 SimpleCredentials 獲得 Session 對象。在這個實現中,SimpleCredentials 接受所有用戶名。替代的 JCR 實現可以提供更復雜的認證機制,可以連接到 LDAP 服務器或外部數據庫來提供憑據信息。(身份驗證和訪問控制的完整功能超出了本文的范圍。要獲得有關的更多信息,請參閱 JSR-170 規范的 6.9 小節。)
Session 對象為程序員提供了一個臨時的存儲層,它非常像傳統的對象關系映射工具中可以看到的層,而且還可以將它看作到特定工作區的連接。它允許客戶訪問綁定到這個會話的任何節點或屬性。通過會話,可以得到工作區,再從工作區得到根節點。所有這些步驟都是在清單 5 的簡短代碼片段中完成的:
清單 5. 獲得工作區和根節點
SimpleCredentials cred = new SimpleCredentials("userid",
"".toCharArray());
Session session = r.login(cred, null);
Workspace ws = session.getWorkspace();
Node rn = session.getRootNode();
使用會話、工作區和根節點引用,現在可以通過不同的抽象層訪問倉庫的特性。最後,為了驗證倉庫已經成功獲得初始化,可以用 rn.getPrimaryNodeType().getName() 輸出根節點的名稱。這應當形成以下輸出:
rep:root
因為正在使用 JAAS,所以請記得將 -Djava.security.auth.login.config==jaas.config. 以 Java JVM 參數的形式包含進來。
JCRWiki 名稱空間
在這個練習中,所有的 JCRWiki 內容都放在 wiki 名稱空間下。為了讓倉庫識別這個名稱空間,必須在初始化時注冊名稱空間,如下所示:
ws.getNamespaceRegistry()。registerNamespace
("wiki", "http://www.barik.net/wiki/1.0");
恭喜!倉庫的手工配置現在完成了。
自動配置
Jackrabbit 實現還提供了一個 TransientRepository 類,這個類來自其核心 API,可以在啟動第一個會話時自動初始化內容倉庫,並在最後一個會話關閉時停止使用倉庫。對於簡單的獨立應用程序,使用 TransientRepository 可以極大地簡化倉庫的配置,但要以 JSR-170 的移植性作為代價。
TransientRepository 自動創建 repository.xml 和倉庫文件夾。它還在內部提供了處理身份驗證和安全性的 SimpleAccessManager。
自動配置需要使用如圖 6 所示的初始化 import 語句。與手工配置相比,所有的 JNDI 引用都被刪除了。在 RegistryHelper 的位置換上了 TransientRepository。
清單 6. 自動配置的 import 語句
import org.apache.jackrabbit.core.TransientRepository
import javax.jcr.*;
import javax.jcr.query.*;
import javax.jcr.version.*;
import java.util.Calendar;
import java.io.*;
import sun.net.www.MimeTable;
因為 TransientRepository 為您執行了初始化,所以獲得倉庫非常簡單,如清單 7 所示:
清單 7. 用 TransientRepository 獲得倉庫、工作區和根節點
Repository r = new TransientRepository();
Session session = r.login(new SimpleCredentials("userid", "".toCharArray()));
Workspace ws = session.getWorkspace();
Node rn = session.getRootNode();
像手工配置時一樣,所有的 JCRWiki 內容都放在 wiki 名稱空間下:
ws.getNamespaceRegistry()。registerNamespace
("wiki", "http://www.barik.net/wiki/1.0");
恭喜!倉庫的自動配置現在完成了。
JCRWiki 的設計策略
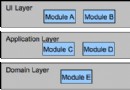
現在看一下 JCRWiki 倉庫的整體內容層次結構。在示例中,要創建兩個實體 “rose” 和 “Shakespeare”,它們都是 nt:unstructured 類型的。根據設計合同,每個百科全書條目都要有三個屬性:條目的標題、條目的內容以及多值分類屬性(如果條目有多個分類)或單值分類屬性(如果條目只有一個分類)。多值屬性在編程上表現為一組數值。
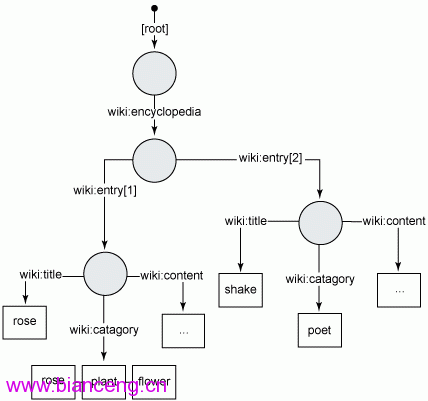
圖 2 描繪了 JCRWiki 設計策略的圖示:
圖 2. JCRWiki 拓撲的高層圖示
JCRWiki 功能
沒有內容的倉庫沒什麼用處。這一節將演示 JSR-170 提供的基本內容操縱功能,並描述一些更高級的、可選的倉庫特性,例如版本管理和導入導出 XML 內容。
添加內容
從清單 8 開始,向倉庫添加內容節點,讓它看起來像圖 2 中的 JCRWiki 拓撲:
清單 8. 將內容添加到 JCR 倉庫中
Node encyclopedia = rn.addNode("wiki:encyclopedia");
Node p = encyclopedia.addNode("wiki:entry");
p.setProperty("wiki:title", new StringValue("rose"));
p.setProperty("wiki:content", new
StringValue("A rose is a flowering shrub."));
p.setProperty("wiki:category",
new Value[]{
new StringValue("flower"),
new StringValue("plant"),
new StringValue("rose")});
Node n = encyclopedia.addNode("wiki:entry");
n.setProperty("wiki:title", new StringValue("Shakespeare"));
n.setProperty("wiki:content", new
StringValue("A famous poet who likes roses."));
n.setProperty("wiki:category", new StringValue("poet"));
session.save();
默認情況下,Jackrabbit 的節點被設置為 nt:unstructured。注意,“rose” 的分類屬性是多值的。上面代碼段的最後一行代碼將保存會話。添加和設置節點以及節點屬性只能修改臨時的會話存儲層。要將這些變化保持到倉庫中,則必須用 session.save() 保存會話。可以在目標節點上調用 Node.remove() 來刪除節點。
存取內容
JSR-170 提供了兩種存取內容的方法:遍歷 存取和直接 存取。遍歷存取包括用相對路徑在內容樹中進行遍歷,直接存取允許用絕對路徑直接跳到節點,如果節點是可以引用的,則用 UUID 直接跳到節點。因為兩種存取之間存在相似性,所以我在這篇文章只側重於遍歷存取。
從任何 Node 對象及其方法 Node.getNode()、Node.getProperty() 都可以進行遍歷存取。通過使用 JCRWiki 拓撲,可以用以下代碼從根節點獲得 encyclopedia 節點:
Node encyclopedia = rn.getNode("wiki:encyclopedia");
可以進一步通過遍歷得到屬性。例如,在根節點向下的 “rose” 百科全書節點條目中,假設以前知道 JCRWiki 拓撲,那麼可以像這樣通過遍歷得到屬性:
String roseTitle = rn.getProperty
("wiki:encyclopedia/wiki:entry[1]/wiki:title").getString()
請注意,您是通過 wiki:entry[1] 進行遍歷的。當有同名的多個同級節點時,可以用下標區分出想要的同級節點。在 JCR 中,對同級節點的索引是從 1 而不是 0 開始的。而且,索引的順序是在通過 Node.getNodes() 得到的迭代器中返回的節點的順序。
然後,可以通過獲取 NodeIterator(它返回特點節點的子節點)來浏覽所有 JCRWiki 條目,如清單 9 所示:
清單 9. 浏覽內容倉庫
Node encyclopedia = rn.getNode("wiki:encyclopedia");
NodeIterator entries = encyclopedia.getNodes("wiki:entry");
while (entries.hasNext()) {
Node entry = entries.nextNode();
System.out.println(entry.getName());
System.out.println(entry.getProperty("wiki:title")。getString());
System.out.println(entry.getProperty("wiki:content")。getString());
System.out.println(entry.getPath());
Property category = entry.getProperty("wiki:category");
try {
String c = category.getValue()。getString();
System.out.println("Category: " + c);
} catch (ValueFormatException e) {
Value[] categories = category.getValues();
for (Value c : categories) {
System.out.println("Category: " + c.getString());
}
}
}
因為分類屬性可以是多值的也可以是單值的,所以要用 try-catch 語句檢查它。如果對多值屬性調用 getValue(),就會拋出 ValueFormatException。一般來說,直接存取和遍歷存取都需要知道內部節點的結構。所以讓我們來看一種更具表現力的存取節點的方式:使用搜索。
用 XPath 搜索內容
正如已經看到的,遍歷存取和直接存取都需要知道圖書的位置。獲得特定條目的更好方式是通過 JCR 的 XPath 搜索工具。因為從樹形結構來看,工作區模型非常類似於 XML 文檔,所以 XPath 是查找節點的理想語法。XPath 查詢是通過 QueryManager 對象執行的。查詢的過程與通過 JDBC 存取記錄類似,如清單 10 所示:
清單 10. 用 XPath 搜索內容
QueryManager qm = ws.getQueryManager();
Query q = qm.createQuery
("//wiki:encyclopedia/wiki:entry[@wiki:title = 'rose']",
Query.XPATH);
QueryResult result = q.execute();
NodeIterator it = result.getNodes();
while (it.hasNext()) {
Node n = it.nextNode();
System.out.println(n.getName());
System.out.println(n.getProperty("wiki:title").getString());
System.out.println(n.getProperty("wiki:content").getString());
}
createQuery() 的第二個參數指定所使用的查詢語言。JRC 實現可以另外選擇為 SQL 語法支持 Query.SQL。也可以執行更復雜的查詢。例如,可以查詢的內容中包含單詞 rose 的所有條目:
Query q = qm.createQuery
("//wiki:encyclopedia/" +
"wiki:entry[jcr:contains(@wiki:content, 'rose')]",
Query.XPATH);
用 XML 導入和導出內容
JSR-170 為了確保跨 JCR 實現的移植性已經做了許多工作。它促進移植性的方式之一就是使用標准的 XML 導入和導出特性。通過使用這些工具,符合規范的供應商倉庫內容可以很容易地轉移到另一個符合規范的供應商倉庫。使用 XML 進行序列化的另一個優勢是:可以用傳統的 XML 解析工具操縱導出的倉庫。只要用清單 11 的三行代碼就可以執行導出:
清單 11. 導出數據
File outputFile = new File("systemview.xml");
FileOutputStream out = new FileOutputStream(outputFile);
session.exportSystemView("/wiki:encyclopedia", out, false, false);
然後可以把生成的 XML 文件轉移給另一個新倉庫,如清單 12 所示:
清單 12. 轉移數據
File inputFile = new File("systemview.xml");
FileInputStream in = new FileInputStream(inputFile);
session.importXML
("/", in, ImportUUIDBehavior.IMPORT_UUID_CREATE_NEW);
session.save();
添加二進制內容
直到現在,一直都是用 StringValue 表示屬性和節點。但是 JCR 還支持其他類型,包括布爾型和長整型。清單 13 演示了 JCR 中可使用的流類型,可在節點中保存二進制圖片。在這個清單中,可將文件 rose.gif 作為元數據添加到 nt:file 節點中。文件數據本身被保存為 nt:resource 子節點。
清單 13. 添加二進制內容
File file = new File("rose.gif");
MimeTable mt = MimeTable.getDefaultTable();
String mimeType = mt.getContentTypeFor(file.getName());
if (mimeType == null) mimeType = "application/octet-stream";
Node fileNode = roseMode.addNode(file.getName(), "nt:file");
Node resNode = fileNode.addNode("jcr:content", "nt:resource");
resNode.setProperty("jcr:mimeType", mimeType);
resNode.setProperty("jcr:encoding", "");
resNode.setProperty("jcr:data", new FileInputStream(file));
Calendar lastModified = Calendar.getInstance();
lastModified.setTimeInMillis(file.lastModified());
resNode.setProperty("jcr:lastModified", lastModified);
在使用 MimeTable 類確定了內容類型之後,用 FileInputStream 裝入文件。這個問題很簡單,只要給 nt:resource 節點類型添加命名正確的屬性即可,屬性包含實際的文件數據。
版本管理
JSR-170 支持許多可選特性,包括訪問控制、事務、鎖定和版本管理。這些特性本身都可以是個完整的主題,所以我必須簡要地總結一下,只介紹它們當中最流行的那一個:版本管理。在最簡單的情況下,只需將 mix:versionable 混合類型添加到任何節點,就可以執行版本管理。在節點上,可以用一組類似 CVS 操作的方法實現版本管理,如清單 14 所示:
清單 14. 版本管理方法
n.checkout();
n.setProperty("wiki:content", "Updated content for the entry.");
n.save();
n.checkin();
JCR 中的其他操作包括:更新、合並和恢復以前版本。要浏覽指定節點的整個版本歷史,可以通過清單 15 中的步驟進行:
清單 15. 浏覽版本歷史
VersionHistory vh = n.getVersionHistory();
VersionIterator vi = vh.getAllVersions();
vi.skip(1);
while (vi.hasNext()) {
Version v = vi.nextVersion();
NodeIterator ni = v.getNodes();
while (ni.hasNext()) {
Node nv = ni.nextNode();
System.out.println("Version: " +
v.getCreated()。getTime());
System.out.println(nv.getProperty("wiki:title").getString());
System.out.println(nv.getProperty("wiki:content").getString());
}
}
使用 vi.skip(1) 最初看起來可能有點怪,但是如果看到了版本歷史的內部保存機制,就應該很清楚這種用法了,版本歷史的內部保存機制如圖 3 所示:
圖 3. 節點版本歷史的結構化模型
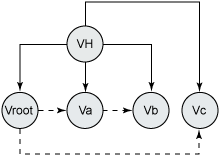
在節點的版本歷史中,每個版本都保存為版本歷史的一個子版本,而且包含指向後續版本的引用。在圖 3 中,版本 Vb 是版本 Va 的後續,版本 Vc 和 Va 是 Vroot 的後續,Vroot 是版本圖的開始。Vroot 是自動創建的子節點,是版本圖的起點,它不包含任何狀態信息。所以,當應用程序在版本歷史中遍歷時,Vroot 被跳過。
結束語
本文提供了對 JSR-170 規范所提供特性的廣泛介紹。在 2005 年 6 月 17 日通過的規范的最終發行版中,已有兩個商業實現:Day Software 的 CRX 和 Obinary 的 Magnolia Power Pack。JSR-170 的引入也導致了企業開源門戶和內容管理系統(如 Magnolia 和 eXo 平台)的增多。最重要的是,JSR-170 擁有來自行業領導者(包括 SAP AG、Macromedia 和 IBM)的強大支持,從而在企業陣營建立起了它自己的應用和重要性。就像對象關系映射框架改變了數據庫編程一樣,JCR API 也有可能極大地改變我們思考和開發內容應用程序的方式。