當 CPU 進入多核時代之後,軟件的性能調優就不再是一件簡單的事情。沒有 並行化的程序在新的硬件上可能會運行得比從前更慢。當 CPU 數目增加的時候 ,芯片制造商為了取得最佳的性能/功耗比,降低 CPU 的運行頻率是一件非常明 智的事情。相比 C/C++ 程序員而言 , 利用 Java 編寫多線程應用已經簡單了很 多。然而,多線程程序想要達到高性能仍然不是一件容易的事情。對於軟件開發 人員而言, 如果在測試時發現並行程序並不比串行程序快,那不是一件值得驚 訝的事情,畢竟,在多核時代之前, 受到廣泛認可的並行軟件開發准則通常過 於簡單和武斷。
在本文中,我們將介紹提高 Java 多線程應用性能的一般步驟。 通過運用本 文提供的一些簡單規則,我們就能獲得具有高性能的可擴展的應用程序。
為什麼性能沒有增長?
多核能帶來性能的大幅增長,這很容易通過簡單的一些測試來觀察到。如果 我們寫一個多線程程序,並在每個線程中對一個本地變量進行累加,我們可以很 容易的看到多核和並行帶來的成倍的性能提升。這非常容易做到,不是嗎?在 參考資源 裡我們給出了一個例子。然而,與我們的測試相反,我們很少在實際 軟件應用中看到這樣完美的可擴展性。阻礙我們獲得完美的可擴展性有兩方面的 因素存在。首先,我們面臨著理論上的限制,其次軟件開發過程中也經常出現實 現上的問題。讓我們看看 圖 1 中的三條性能曲線:
圖 1. 性能曲線
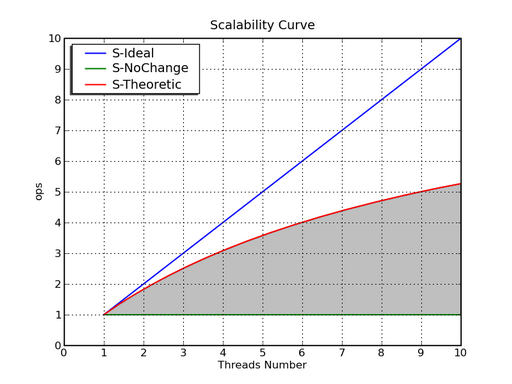
作為追求完美的軟件工程師,我們希望看到隨著線程數目的增長程序的性能 獲得線性的增長,也就是圖 1 中的藍色直線。而我們最不希望看到的是綠色的 曲線,不管投入多少新的 CPU,性能也沒有絲毫增長。(隨著 CPU 增長而性能 下降的曲線在實際項目中也存在)。而圖中的紅色線條則說明通常的 90-10 法 則並不適用於可擴展性方面。假設程序中有 10% 的計算只能串行進行,那麼其 擴展性曲線如紅線所示。由圖可見,當 90% 的代碼可以完美的並行時,在 10 個 CPU 存在的情況下,我們也只能獲得大約 5 倍的性能。如果任務中具有無法 並行的部分,那麼在現實世界,我們的性能曲線大致上會位於圖 1 中的灰色區 域。
在這篇文章中,我們不會試圖挑戰理論極限。我們希望能解釋一個 Java 程 序員如何能夠盡可能的接近極限,這已經不是一個容易的任務。
是什麼造成了糟糕的可擴展性?
可擴展性糟糕的原因有很多,其中最為顯著的是鎖的濫用。這沒有辦法,我 們就是這樣被教育的:“想要多線程安全嗎?那就加一個鎖吧”。想想 Python 中臭名昭著的 Global Intepreter Lock,還有 Java 中的 Collections.synchronizedXXXX() 系列方法,跟隨巨人的做法有什麼不好嗎? 是的,用鎖來保護關鍵區域非常方便,也較容易保證正確性,然而鎖也意味著只 有一個進程能進入關鍵區域,而其他的進程都在等待!如果觀察到 CPU 空閒而 軟件執行緩慢,那麼檢察一下鎖的使用是一個明智的做法。
對於 Java 程序而言,Performance Inspector 中的 Java Lock Monitor 是 一個不錯的開源工具。
對一個多線程應用進行調優
下面,我們將提供一個例子程序並演示如何在多核平台上獲得更好的可擴展 性。這個例子程序演示了一個假想的日志服務器。它接收來自多個源的日志信息 並將其統一保存到文件系統中。為了簡單起見,我們的例子代碼中不包含任何的 網絡相關代碼,Main() 函數將啟動多個線程來發送日志信息到日志服務器中。 對於性急的讀者,讓我們先看看調優的結果:
圖 2. 日至服務器調優結果
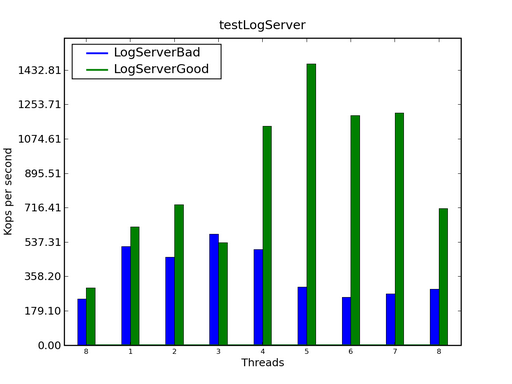
在上圖中,藍色的曲線是一個基於 Lock 的老式日志服務器,而綠色的曲線 是我們進行了性能調優之後的日志服務器。可以看到,LogServerBad 的性能隨 線程數目的增加變化很小,而 LogServerGood 的性能則隨著線程數目的增加而 線性增長。如果不介意使用第三方的庫的話,那麼來自 Project KunMing 的 LockFreeQueue 可以進一步提供更好的可擴展性:
圖 3. 使用 Lock-free 的數據結構
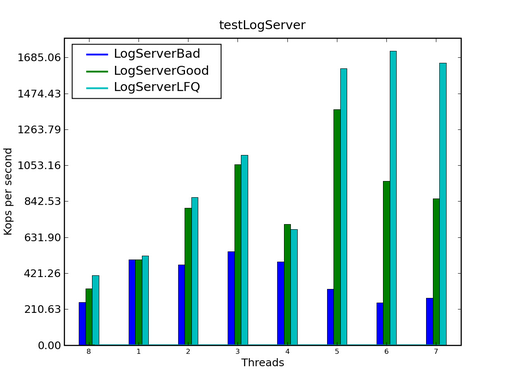
在上圖中,第三條曲線表示用 LockFreeQueue 替換標准庫中的 ConcurrentLinkedQueue 之後的性能曲線。可以看到,如果線程數目較少時,兩 條曲線差別不大,但是單線程數目增大到一定程度之後,Lock-Free 的數據結構 具有明顯的優勢。
在下文中,將介紹在上述例子中使用的可以幫助我們創建高可擴展 Java 應 用的工具和技巧。
使用 JLM 分析應用程序
JLM 提供了 Java 應用和 JVM 中鎖持有時間和沖突統計。具體提供以下功能 :
對沖突的鎖進行計數
成功獲得鎖的次數
遞歸鎖的次數
申請鎖的線程被阻塞等待的次數
鎖被持有的累計時間。對於支持 3 Tier Spin Locking 的平台 , 還可以獲 得以下信息 :
請求線程在內層(spin loop)請求鎖的次數
請求線程在外層(thread yield loop)請求鎖的次數
使用 rtdriver 工具收集更詳細的信息
jlmlitestart:僅收集計數器
jlmstart:僅收集計數器和持有時間統計
jlmstop:停止數據收集
jlmdump:打印數據收集並繼續收集過程
從鎖持有時間中去除垃圾收集(Garbage Collection,GC)的時間
GC 時間從 GC 周期中所有被持有的鎖的持有時間中去除
使用 AtomicInteger 進行計數
通常,在我們實現多線程使用的計數器或隨機數生成器時,會使用鎖來保護 共享變量。這樣做的弊端是如果鎖競爭的太厲害,會損害吞吐量,因為競爭的同 步非常昂貴。
volatile 變量雖然可以使用比同步更低的成本存儲共享變量,但它只可以保 證其他線程能夠立即看到對 volatile 變量的寫入,無法保證讀 - 修改 - 寫的 原子性。因此,volatile 變量無法用來實現正確的計數器和隨機數生成器。
從 JDK 5 開始,java.util.concurrent.atomic 包中引入了原子變量,包括 AtomicInteger、AtomicLong、AtomicBoolean 以及數組 AtomicIntergerArray 、AtomicLongArray 。原子變量保證了 ++,--,+=,-= 等操作的原子性。利用 這些數據結構,您可以實現更高效的計數器和隨機數生成器。
加入輕量級的線程池—— Executor
大多數並發應用程序是以執行任務(task)為基本單位進行管理的。通常情 況下,我們會為每個任務單獨創建一個線程來執行。這樣會帶來兩個問題:一, 大量的線程(>100)會消耗系統資源,使線程調度的開銷變大,引起性能下 降;二,對於生命周期短暫的任務,頻繁地創建和消亡線程並不是明智的選擇。 因為創建和消亡線程的開銷可能會大於使用多線程帶來的性能好處。
一種更加合理的使用多線程的方法是使用線程池(Thread Pool)。 java.util.concurrent 提供了一個靈活的線程池實現:Executor 框架。這個框 架可以用於異步任務執行,而且支持很多不同類型的任務執行策略。它還為任務 提交和任務執行之間的解耦提供了標准的方法,為使用 Runnable 描述任務提供 了通用的方式。 Executor 的實現還提供了對生命周期的支持和 hook 函數,可 以添加如統計收集、應用程序管理機制和監視器等擴展。
在線程池中執行任務線程,可以重用已存在的線程,免除創建新的線程。這 樣可以在處理多個任務時減少線程創建、消亡的開銷。同時,在任務到達時,工 作線程通常已經存在,用於創建線程的等待時間不會延遲任務的執行,因此提高 了響應性。通過適當的調整線程池的大小,在得到足夠多的線程以保持處理器忙 碌的同時,還可以防止過多的線程相互競爭資源,導致應用程序在線程管理上耗 費過多的資源。
Executor 默認提供了一些有用的預設線程池,可以通過調用 Executors 的 靜態工廠方法來創建。
newFixedThreadPool:提供一個具有最大線程個數限制的線程池。
newCachedThreadPool:提供一個沒有最大線程個數限制的線程池。
newSingleThreadExecutor:提供一個單線程的線程池。保證任務按照任務隊 列說規定的順序(FIFO,LIFO,優先級)執行。
newScheduledThreadPool:提供一個具有最大線程個數限制線程池,並支持 定時以及周期性的任務執行。
使用並發數據結構
Collection 框架曾為 Java 程序員帶來了很多方便,但在多核時代, Collection 框架變得有些不大適應。多線程之間的共享數據總是存放在數據結 構之中,如 Map、Stack、Queue、List、Set 等。 Collection 框架中的這些數 據結構在默認情況下並不是多線程安全的,也就是說這些數據結構並不能安全地 被多個線程同時訪問。 JDK 通過提供 SynchronizedCollection 為這些類提供 一層線程安全的接口,它是用 synchronized 關鍵字實現的,相當於為整個數據 結構加上一把全局鎖保證線程安全。
java.util.concurrent 中提供了更加高效 collection,如 ConcurrentHashMap/Set, ConcurrentLinkedQueue, ConcurrentSkipListMap/Set, CopyOnWriteArrayList/Set 。這些數據結構是為 多線程並發訪問而設計的,使用了細粒度的鎖和新的 Lock-free 算法。除了在 多線程條件下具有更高的性能,還提供了如 put-if-absent 這樣適合並發應用 的原子函數。
其他一些需要考慮的因素
不要給內存系統太大的壓力
如果線程執行過程中需要分配內存,這在 Java 中通常不會造成問題。現代 的 JVM 是高度優化的,它通常為每個線程保留一塊 Buffer,這樣在分配內存時 ,只要 buffer 沒有用光,那麼就不需要和全局的堆打交道。而本地 buffer 分 配完畢之後 , JVM 將不得不到全局堆中分配內存,這樣通常會帶來嚴重的可擴 展性的降低。另外,給 GC 帶來的壓力也會進一步降低程序的可擴展性。盡管我 們有並行的 GC,但其可擴展性通常並不理想。如果一個循環執行的程序在每次 執行中都需要分配臨時對象,那麼我們可以考慮利用 ThreadLocal 和 SoftReference 這樣的技術來減少內存的分配。
使用 ThreadLocal
ThreadLocal 類能夠被用來保存線程私有的狀態信息,對於某些應用非常方 便。通常來講,它對可擴展性有正面的影響。它能為各個線程提供一個線程私有 的變量,因而多個線程之間無須同步。需要注意的是在 JDK 1.6 之前, ThreadLocal 有著相當低效的實現,如果需要在 JDK 1.5 或更老的版本上使用 ThreadLocal,需要慎重評估其對性能的影響。類似的,目前 JDK 6 中的 ReentrantReadWriteLock 的實現也相當低效,如果想利用讀鎖之間不互斥的特 性來提高可擴展性,同樣需要進行 profile 來確認其適用程度。
鎖的粒度很重要
粗粒度的全局鎖在保證線程安全的同時,也會損害應用的性能。仔細考慮鎖 的粒度在構建高可擴展 Java 應用時非常重要。當 CPU 個數和線程數較少時, 全局鎖並不會引起激烈的競爭,因此獲得一個鎖的代價很小(JVM 對這種情況進 行了優化)。隨著 CPU 個數和線程數增多,對全局鎖的競爭越來越激烈。除了 一個獲得鎖的 CPU 可以繼續工作外,其他試圖獲得該鎖的 CPU 都只能閒置等待 ,導致整個系統的 CPU 利用率過低,系統性能不能得到充分利用。當我們遇到 一個競爭激烈的全局鎖時,可以嘗試將鎖劃分為多個細粒度鎖,每一個細粒度鎖 保護一部分共享資源。通過減小鎖的粒度,可以降低該鎖的競爭程度。 java.util.concurrent.ConcurrentHashMap 就通過使用細粒度鎖,提高 HashMap 在多線程應用中的性能。在 ConcurrentHashMap 中,默認構造函數使 用 16 個鎖保護整個 Hash Map 。用戶可以通過參數設定使用上千個鎖,這樣相 當於將整個 Hash Map 劃分為上千個碎片,每個碎片使用一個鎖進行保護。
結論
通過選擇一種合適的 profile 工具,檢查 profile 結果中的熱點區域。使 用適合多線程訪問的數據結構,線程池,細粒度鎖減小熱點區域。並重復此過程 不斷提高應用的可擴展性。
構建在多核上具有高可擴展性的 Java 應用並不是一件容易的事。減少各個 線程之間的沖突和同步是提高可擴展性的關鍵。本文中介紹的一些通用工具和技 巧可以給程序員提供一些幫助,但更多的情況要依賴於具體的應用。
本文配套源碼