企業java應用的性能調優是一項艱巨的、有時甚至是徒勞的任務,這是由現代 應用的復雜性和缺少正規的調優方法導致的。現代企業應用與十年前的應用相比 差距很大,如今這些應用支持多輸入、多輸出、復雜的框架和業務處理引擎。而 十年之前,基於web的企業應用只是通過網絡浏覽器獲得輸入信息,然後與數據庫 或者遺留系統交互進行後台處理,最後把輸出結果返回給浏覽器(HTML)。現在 ,輸入信息可以來自HTML浏覽器、富客戶端、移動設備或者網絡服務,它可以跨 越運行在不同架構下的servlets或者門戶容器,這反過來又可能調用企業bean, 外部web服務或者把處理委托給業務規則引擎。每一個這樣的組件都可能與內容管 理系統、緩存層、眾多數據庫和遺留系統交互。輸出的信息通常以獨立於展現層 的形式保存,隨後轉化為HTML、XML、WML或者其他任意客戶端需要的格式。現代 應用比過去包含更多移動部分和“黑盒子”,這對性能調優提出了巨大的挑戰。
除了復雜性提高,性能調優技術其藝術性要大於科學性,還因為大多數性能調 優指南都側重於性能指標,有時晦澀難懂,也可能影響用戶體驗。本文嘗試把性 能調優活動變成一種“科學”范疇內的行為,提供了一種可重用的關注用戶體驗 的方法,利用“等待點”(也就是應用中引起某請求等待的部分)分析應用架構 。總之,基於等待的調優方法允許性能工程師們通過優化用戶體驗快速實現可度 量的性能提高。
性能調優過程
在詳細介紹基於等待調優和等待點分析方法之前,本節首先對有效的性能調優 過程做一個概述。性能調優可以簡單的概括為四步:
負載測試
容器調優
應用調優
迭代
像大多數計算機科學一樣,性能調優是一個迭代的過程。首先,創建一個合適 的負載測試,其中包含了均衡的、具有代表性的服務請求,這都是容器調優實踐 可以滿足的。隨著容器被不斷調優和測試壓力的增大,應用程序的瓶頸逐漸顯現 出來。隨著應用的瓶頸被定位和解決,應用行為會發生變化,這就要求容器再次 調優。在容器和應用之間的迭代過程會一直進行到性能到達可以接受的條件(或 者直到項目已經到期必須發布時)。
負載測試方法
啟動一個性能調優實踐的先決條件是創建一整套合適的負載測試集合。每一個 負載測試必須滿足以下兩點:
代表性,必須體現最終用戶的業務場景(或期望的場景)
均衡性,必須符合最終用戶不同行為的比例分配
也就是說,負載必須能夠按照最終用戶的實際操作比例來模擬用戶動作。為了 說明均衡最終用戶動作的重要性,請看下面這個例子:在保險索賠部門,員工執 行以下操作:
用戶上午八點登陸系統。
上午每人平均處理五個索賠請求。
大約80%的用戶忘記在吃飯之前注銷賬號,導致session過期。
午飯後,用戶重新登錄系統。
下午每人平均處理五個索賠申請。
下班之前生成兩個報告。
80%的用戶回家前注銷賬號。
這個例子是一個真實應用的簡化版,但是它足夠在這些服務請求建立一個平衡 。這個場景展現的均衡是:兩次登陸,十次索賠處理,兩次報告和一次注銷。
如果負載生成器把壓力均勻分布在不同的服務請求上又會怎麼樣呢?在本例中 ,用戶登陸和注銷功能會接收與處理與理賠請求相同的負載。如果是1000個並發 用戶,登陸功能會很快崩潰,導致企業投資建立一個能夠處理這種負載的登陸組 件,而實際上這種負載根本不會發生。更糟糕的是,本例中由於最大的瓶頸看似 存在於登陸功能上,所以調優的努力會側重該功能,而忽視索賠處理功能。總之 ,一個非均衡的負載可能導致調優過程錯誤的關注於支持那些絕不會發生的負載 的組件,而不是那些真正需要調優的部分!
判斷一個負載對於應用是均衡的和代表性的標准,對於測試一個已存在的應用 (或者一個新版本)還是一個全新的應用是不同的。
已存在應用
已存在應用跟一個全新應用相比,一個明顯的優點是:真實的用戶行為可以在 實際生產環境中觀察獲得。根據請求的本質和它們如何被應用定義,可以通過兩 個選擇定義最終用戶行為:
訪問日志
最終用戶體驗監視器
對於大多數基於web的應用來說,訪問日志提供了足夠的資源分析服務請求的 本質和它們的均衡關系。Web服務器可以配置成抓取最終用戶請求信息並存儲在一 個日志文件中,稱之為“訪問日志”(因為該文件通常命名為“access.log”) 。使用訪問日志定位用戶行為的關鍵是應用交互需要能夠通過不同的 URI來區分 。例如,如果之前例子的動作采用類似“/login.do”、“/processClaim.do”、 “/logout.do”的URI,那 麼我們可以非常容易的在訪問日志中發現這些行為並 確定它們的比例。更進一步,通過最頻繁的URI來排序訪問日志可以快速發現占比 例前n%的的若干請求,這 個“n”%應該在80%左右。
訪問日志是文本文件,可以手動檢查(不是一個很有效率的任務),可以通過 編程解析,也可以通過工具來分析。對此有很多商業解決方案,不過Quest Software有一個產品Funnel Web Analyzer,雖然多年以前已經終止開發,但是由 於其很受歡迎的命令,公司就作為將其作為自由軟件重新發布。Funnel Web Analyzer可以分析大多數訪問日志並顯示用於創建合適負載測試的信息。
一些應用不像上面提到的那樣簡單,其用戶交互無法很容易的通過一個URI來 定位。例如,考慮一個包含前端控制器servlet的應用,該servlet接受一個XML有 效信息——並且其業務處理邏輯就存在於該信息中。在本例中,需要另外的工具 來偵測其有效信息以判斷其符合哪個業務場景。這可以通過使用 servlet過濾器 或者一個稱為最終用戶體驗監視器的硬件設備來完成。
不管用戶行為是如何獲得的,它都是開始任何性能調優實踐之前的關鍵先決條 件。
全新應用
由於全新的應用沒有任何最終用戶行為可以分析,所以對我們提出了一個獨特 的挑戰。定位新應用的用戶行為需要三個步驟,如圖1所示。
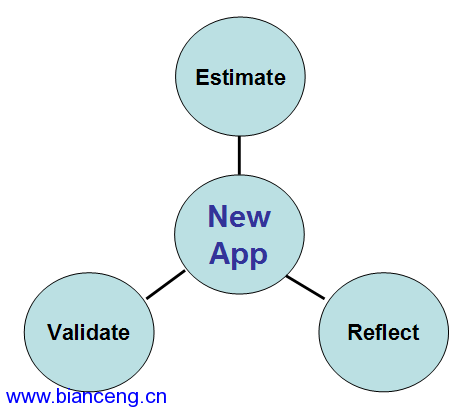
圖 1 評估新應用的最終用戶行為
第一步,評估最終用戶應該會做什麼。這步是“猜一猜”的正式說法,但應該 是一個經過培訓的猜測過程。評估結果應該來自於以下雙方的討論:應用業務負 責人和應用技術負責人。應用業務負責人,通常是一個產品經理,負責細化最終 用戶應該如何使用該應用程序——例如,他可能報告說最終用戶會登陸、處理五 個索賠請求、過期、處理五個索賠請求、生成兩個報告、然後注銷。應用技術負 責人,一般是架構師或是技術lead,負責把業務交互的抽象列表翻譯成用於生成 負載測試的技術步驟——例如,他可能報告說登陸通過“/login.do” URI完成而 處理一個索賠請求需要五個URI。這些人(或者小組或者一些大型項目裡的委員會 )應該一起提供足夠的信息來建立一個基准負載測試。
我們建立負載測試,用其調整應用和容器,應用程序部署到生產環境中,這一 切做完之後,調優工作並沒有結束。下一步是驗證負載測試集。這通常是一個多 階段的活動:
冒煙測試驗證:在實際運行的一兩周之內驗證原先的評估值是否符合真正生產 環境下最終用戶的行為。這步驗證是為了確認在評估過程中沒有明顯的錯誤。
生產驗證:一些應用需要用戶花時間才能形成統一的使用方式。這個適應的時 間長短因應用而異,可能是一個月或者一個季度,不過一旦用戶的行為穩定下來 ,就需要驗證最終用戶行為是否與評估一致。
回歸驗證:最好在應用的生產周期中階段性的驗證用戶行為,以防止用戶行為 改變或者引入新的功能或工作流導致用戶行為改變。
最後一步,也是經常被忽視的一步,就是反思。根據實際用戶行為來反思評估 的精確性是很重要的,因為只有通過反思,用戶行為才能更便於理解,評估在以 後的應用中才能得到提高。沒有反思,相同的錯誤會一犯再犯,最終會增加調優 的工作量。
基於等待的調優方法
建好了負載測試,接下來就是決定把調優精力放在何處。大多數調優指南都會 提到“性能比率”或者度量之間的關系。例如,某調優指南可能強調說緩存命中 率應該達到80%或者更高,因此負載測試應用時調整緩存大小直到命中率達到80% 。然後處理列表上的下一個度量值,但是不要忘記驗證調整新的參數不會影響之 前已經調好的其他參數。
這項工作不僅困難而且效率很低。例如,調整緩存命中率到80%可能是件好事 ,但是存在一些更重要的問題:
該應用如何依賴於緩存(與該緩存交互的請求比例是多少)?
這些請求對應用中的其他請求有多大影響力?
被緩存的條目的本質是什麼?它們真的需要緩存嗎?
基於等待的調優方法提出了一個新的思想,即分析應用的業務交互和實現這些 交互的底層結構,然後優化這些業務交互的處理。第一步是分析應用的架構以定 位實現業務請求的相關技術。每一個技術代表一個“等待點”,或者說在應用的 這個地方,請求可能需要等待一些事情才能繼續處理。例如,如果一個請求執行 了一次數據庫查詢,則它必須從連接池中獲取一個數據庫連接—如果連接池裡沒 有可用的連接,則該請求必須等待直到有連接可用。同樣,如果某請求調用了一 個web服務,而那個web服務維護了一個請求隊列(對應一個線程池處理請求), 這會潛在的導致請求等待直到一個處理線程可用。
從以上稱之為等待點分析的方法中,可以定位兩種類型的等待點:
基於層次的等待點
基於技術的等待點
本節首先概述了基於等待點的架構分析方法,然後分別研究了不同類型的等待 點。
等待點架構分析
從上面討論中得出的最重要的結論就是性能調優必須在應用架構的環境中執行 。這也是調優性能比率為何如此低效的一個原因:主觀的調整一個性能參數到一 個最佳值,對應用可能是好事也可能是壞事——因為這可能會也可能不會有利於 最終用戶體驗。
基於等待點的分析是一個分析應用中主要請求處理路徑的過程,借此定位潛在 影響該請求可能會等待的資源。在等待點分析實踐中最有效的辦法是定位並標出 應用中核心處理路徑。這包括一個請求可能訪問的所有層次、請求交互的所有外 部服務、被做成池的所有對象和全部緩存對象。
基於層次的等待點
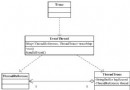
一個請求穿過一個物理層,比如在web層和業務層之間切換,或者調用外部服 務器,比如web服務,每當這種時候,都意味著伴隨著轉換,這裡存在一個隱式等 待點。如果服務器在某一時刻只處理單個請求是沒有效率的,因此他們使用了多 線程方法。典型的,一個服務器在某個socket端口監聽訪問的請求——每當收到 一個請求它就會把請求放在隊列中,然後返回監聽其他請求。請求隊列對應著一 個線程池,負責從隊列中提取請求並處理。圖2描述了對於三層結構(web服務器 、動態web層和業務層)的執行過程。
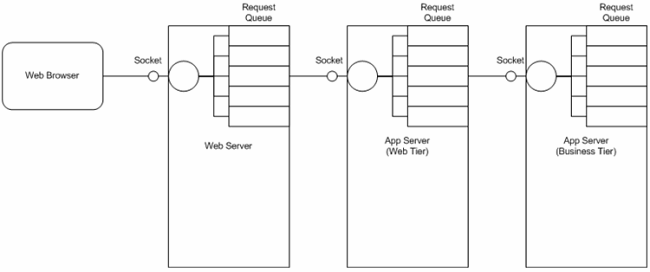
圖 2 基於層次的等待點
因為請求穿越層次的動作會引起請求隊列,由相應的線程池處理,這種線程池 也是一個潛在的等待點。每一個線程池的大小的調優必須基於以下考慮:
池必須足夠大使得訪問的請求無需不必要的等待一個線程。
池不能大到耗盡服務器。過多的線程會迫使服務器花費大量時間用於在不同的 線程上下文中切換,真正處理請求的時間反而更少了。這種情況通常表現為CPU使 用率很高,但是處理請求的吞吐量卻降低了。
池的大小不能透支與之交互的後台資源。例如,如果數據庫對於單個服務器只 支持50個請求,那麼服務器不應該向數據庫發送超過50個數量的請求。
服務器線程池的最佳尺寸的標准是:對受限制的依賴資源產生足夠的負載—最 大化它們的使用率而不讓其透支。下面的“後退調優”一節有更多調整受限制資 源池大小的內容。
基於技術的等待點
基於層次的等待點考慮的是在不同服務器之間傳遞請求,而基於技術的等待點 關注的則是在單個服務器中如何通過有效地內部工作來傳遞請求。基於層次的調 優,類似於IBM的隊列調優,只是調整應用的有效第一步,如果忽略了調優應用服 務器的內部工作,則會對應用性能產生巨大的影響。這就類似於調整JDBC連接池 以發送最佳數量的負載給數據庫,但是忽略了檢查執行的SQL語句——如果查詢需 要連接十個表單,每個表單有一百萬個記錄,則最佳負載可能是兩個連接,但是 如果我們優化了查詢,則數據庫可能支持二百個連接。深入研究應用服務器和應 用使用的潛在技術,可能存在以下通用的基於技術的等待點:
池對象(比如無狀態session bean或者其他應用放入池的業務對象)
緩存設施
持久化存儲或外部依賴池
通訊基礎設施
垃圾收集
大多數情況下,無狀態session bean池的大小被應用服務器優化,不會是一個 明顯的等待點,除非池大小被手工錯誤的配置了。但是也存在一些池對象必須手 動配置大小——這些可能成為有效的等待點。當一個應用需要一個池化的資源, 它必須從池裡獲取一個資源實例,使用它,然後釋放給池。如果池太小,所有的 對象實例都在被使用,則請求不得不等待一個實例可用。顯而易見,等待一個池 化的資源會增加響應時間,如果越來越多的請求被堵塞在等待池化資源,會導致 明顯的性能下降。另一方面,如果池很大,它可能消耗過多內存,對總體JVM的性 能產生差的影響。池的最佳大小需要權衡,只能在對池的利用情況做徹底的分析 才能決定。
池化對象是無狀態的,這意味著應用從池中得到哪個實例都無所謂——任何實 例都行。另一方面,緩存的對象都是有狀態的,也就是說當應用從緩存中請求一 個對象時,它的目標是一個特定對象。舉一個很粗糙的類比說明一下區別:考慮 人們生活當中兩種常見的活動:超市購物和接孩子放學。在超市中,任何收銀員 都可以接待每一位顧客,無論顧客選擇哪位收銀員都可以順利結賬。因此收銀員 可以池化。但是在接孩子放學時,每一個父母只想要他們自己的孩子,別的孩子 是不行的。因此孩子可以被緩存。
如前面所述,緩存提出了一個新的調優挑戰。簡單說,緩存的目的是在本地內 存中存儲對象,使應用可以隨時讀取它們,而不是在需要的時候才獲取他們。一 個合適大小的緩存可以對通過遠程調用加載對象的行為提供明顯的性能改善。但 是,一個不合適大小的緩存,可能產生明顯的性能阻礙。因為緩存維護有狀態的 對象,所以重要的一點是在緩存中存儲最頻繁訪問的對象,同時保留額外的空間 來處理非頻繁訪問對象。試想如果緩存太小,請求會怎樣:
請求檢查緩存中是否存在某對象,結果失敗。
請求需要查詢外部資源獲取對象數據。
因為緩存通常維護最頻繁訪問的數據,所以這個新對象需要添加到緩存中(它 正在被訪問)。
但是如果緩存滿了,必須利用“最少最近訪問”算法選擇一個對象移除。
如果緩存對象的狀態與外部資源不一致,則緩存對象移除之前必須更新外部資 源。
新的對象此刻添加到緩存中。
新的對象最終返回給請求。
這是一個低效的過程,如果大多數請求都要執行這些步驟,那麼緩存肯定會降 低性能。緩存必須調整到足夠大以最小化緩存的“不命中率”,一次不命中意味 著需要執行前面提到的七個步驟,但是也不能太大導致占用太多JVM內存。如果緩 存需要非常非常大才能滿足性能需要,那麼最好是重新考慮被緩存對象的實質和 它們到底是否值得緩存。
類似對象池,外部資源池,比如數據庫連接池,也必須足夠大以滿足請求不會 被迫等待池中的一個連接變為可用狀態,但是也不能太大,導致應用浪費外部資 源。“後退調優”一節討論了如何決定這些池的最佳大小,但是在本節的上下文 中,牢記它們代表了一個明顯的等待點。
調優通訊基礎設施遠遠超出了本文討論的范圍,因為其具體實現因產品不同而 存在明顯的區別,這包括諸如MSMQ、MQSeries、TIBCO等主流產品。但是請記住, 如果一個應用與某消息服務器交互,它必須經過合適的調優或者它也代表了一個 等待點。
最後一個明顯影響JVM性能的等待點是垃圾收集。它不太適用本文中描述的等 待點分析過程(檢查一個請求,定位導致該請求等待的技術),但是由於它可以 對性能產生顯著的影響,所以把它列在這裡。不同的JVM實現和不同的垃圾收集策 略決定了垃圾收集如何執行,但是在很多情況下,一次主垃圾收集(或者說標記 —清除—壓縮垃圾收集)可能導致整個JVM暫停直到垃圾收集完成。一個顯著提高 JVM性能的辦法就是優化垃圾收集。如果想了解更多垃圾收集的信息,請加入 GeekCap討論應用基礎設施調優。
後退調優
現在關於基於層次的和基於技術的等待點的一切都介紹完了,最後一步就是優 化每一個等待點的配置。這一步有時被稱為“後退調優”,其思想非常簡單:
開放所有基於層次的等待點和外部依賴池——也就是配置它們允許過多的負載 經過服務器。
根據應用生成均衡的和具有代表性的服務請求。
定位首先透支的等待點,通常是外部依賴,比如數據庫。
減小配置以控制等待點允許足夠的負載經過外部依賴而不透支。
調整所有其他基於層次的等待點,發送足夠的負載經過服務器,最大化受限制 的等待點,但是也不讓請求等待。
允許所有其他請求在業務邏輯層之上等待,比如web服務器端。
此處的原則就是應用應該發送一定數量的負載給它的外部依賴資源以最大化它 們的使用率又不導致透支—並且所有其他等待點應該合理配置以發送足夠的負載 給這些受限制的等待點。例如,如果數據庫對每一個應用服務器最多支持50個連 接(例如,配置池容納40或45個連接)。接下來,如果80個線程產生40個數據庫 連接,則應用的線程池應配置為80。最後,web服務器在任意時刻應該發送不超過 80個請求給每一個應用服務器。
所有基於技術的等待點,比如對象池、緩存和垃圾回收,應該調整到最大化請 求的吞吐量使得盡可能快的穿越服務器或者基於層析的等待點之間。
總結
性能調優曾經是“藝術性”多於“科學性”,但是通過結合抽象分析和嘗試並 產生錯誤,基於等待的調優方法已經證明能夠使該過程更具科學性和更有效率。 基於等待的調優首先執行一個應用架構的等待點分析,以此定位有可能導致請求 等待的某個技術。等待點來自兩方面:基於層次的等待點,代表著跨越應用層次 的轉換;基於技術的等待點,代表著可能提高或降低性能的技術,比如緩存、池 和通訊基礎設施。一旦定位好了一系列等待點,調優過程就此開始:開放所有基 於層次的等待點和外部依賴池,產生均衡的和具有代表性的負載,然後後退調優 ,收緊等待點以最大化該請求最薄弱的一環的性能,但是不要透支。基於等待的 調優方法在生產環境中已經一次又一次得到了證明,不僅僅是高效的,而且允許 性能工程師快速實現可度量的性能優化。
關於作者
Steven Haines是GeekCap公司的創立者和CEO,該公司致力於向全球的開發社 區提供電子學習解決方案,尤其側重於諸如性能測試和性能調優這樣生僻的領域 。除了電子學習方案,GeekCap還提供了免費的技術論壇、學習路線圖和其他資源 以幫助開發人員發展自己的技術事業和學習新技術。GeekCap提供的服務包括:市 場營銷資料,比如白皮書和技術概要;業務服務,比如市場分析和戰略定位。 Steven的著作包括:許多白皮書、Java EE 5性能管和優化(Apress,2006), Java 2 Primer Plus (SAMS, 2002)和從零學習Java 2(QUE,1999)。他是 InformIT.com的Java版主,同時也是InfoQ.com的Java社區編輯。平時他作為一名 承包商在Disney團隊工作,負責實現下一代Disney網站的架構。他之前在Quest Software公司工作了七年,職責是作為Java領域專家設計性能監控和分析軟件。 他先後在California大學Irvine分校和 Learning Tree大學接受過全面的Java開 發培訓。您可以通過steve@geekcap.com聯系他。
閱讀英文原文:A Formal Performance Tuning Methodology: Wait-Based Tuning。