Java 中使用 new、newarray、anewarray 和 multianewarray 指令來創建的對象,當這些對象不再使用時由垃圾收集來釋放。那麼 反序列化等都是間接使用了前面的某個指令, clone() 是個本地方法?
JVM 規范不需要任何特定的垃圾收集技術,甚至也沒要求有垃圾收集機制。大概只是說不需要手工釋放內存,具體怎麼實現各 JVM 自行決定。
GC 除了釋放不再被引用的對象,還要處理堆碎片,整理出連續的空閒空間才能放得下新的對象。不至於出現總的空閒空間足夠,但碎片太多而報出 "Out of Memory" 的異常。
GC 有兩個好處:一個是提高了生產率,不用埋頭於 Memory Link 的有時甚至是逐行的檢查;二,GC 也是 Java 安全策略的一部分,有了它不至於因錯誤的釋放內存而導至 JVM 崩潰。但是 GC 的一個潛在缺陷影響了程序的性能,它需要一直在後台不時的做些事情,而且實時性也有所欠缺。
垃圾收集算法
GC 算法要做兩件基本的事情:1. 檢測出垃圾對象;2. 回收垃圾對象,釋放相應堆空間。垃圾檢測一般是先建立一個根對象集合,其他對象要是從根對象起可觸及就是活的,無法到達的就是垃圾。這裡的根對象的認定就有些講究的,不同的 JVM 的看法不完全一致,但總是會包含局部變量中的對象引用和棧幀的操作數棧(以及類變量中的引用)。
另一個根對象的來源是被加載的類的常量池中的對象引用。類的常量池中的字符串包括有類名、超類名、超接口名、字段名、字段特征簽名、方法名、方法特征簽名
還有一個來源是傳遞到方法中的、沒有被本地方法“釋放”的對象引用(根據本地方法接口,本地方法可以通過簡單的返回來釋放引用,或者顯式的調用一個回調函數來釋放傳遞來的引用,或是這兩者的結合)。
再一個潛在的根對象來源是,JVM 運行時數據區中從垃圾收集器的堆中分配的部分。某些實現中,方法區中的類數據本身可能被存放在使用垃圾收集器的堆中,以便使用和釋放對象同樣的垃圾收集算法來檢測和卸載不再被引用的類。
在某些 JVM 實現中,像基本類型,如一個 int 如果被解釋為一個本地指針,那它就是指向堆中的一個對象,但是保守的垃圾收集器對這種基本類型引用的堆中的對象不處理。
區別活動對象和垃圾的兩個基本方法是引用計數和跟蹤。
引用計數收集器
引用計數是垃圾收集的早期策略,這種方法時堆中的每個對象都有一個引用計數。當對象創建並賦給一個變量時,引用計數為 1。每次賦給別的變量時,引用計數加 1,當對象的引用超過了生存期或指向到了新值(如果引用置為 null),對象的引用計減 1。這樣對象的引用計數為 0 時就是垃圾,可清除的。引用計數對多個對象的循環引用無能為力,其實這些對象都是死的,但引用計數都不為 0,還有引用數的增減帶來額外開銷,基於這些缺陷,這種技術現在已經不為人所接受了。
跟蹤收集器
跟蹤收集追蹤從根節點開始的對象引用圖。基本的追蹤算法叫作“標記並清除”,也就是垃圾收集的兩個階段。標記階段,垃圾收集器遍歷引用樹,標記每一個遇到的對象。清除階段,未被標記的對象被釋放。可能在對象本身設置標記,要麼就是用一個獨立的位圖來設置標記。
壓縮收集器
垃圾收集同時要應對碎片整理的任務。標記和清除通常使用兩種策略來消除堆碎片:壓縮和拷貝,這兩種方法都是快速移動對象來減小碎片。
壓縮收集我想應該是在標記清除之後來做的?壓縮收集器把活動對象越過空閒區滑到堆的一堆,留下另一端的大的連續空閒塊。被移動的對象的引用也被更新,指向新的位置。更新被移動對象的引用有時通過一個間接對象引用層來實現的,對象的引用不實際指向堆中對象,而是指向一個對象句柄表(由它完成對象引用到堆中對象的實際位置的映射),對象被移動了,只需要更新對象句柄表的句柄值,這樣程序中的對象引用不變。這種方法簡化了消除堆碎片的工作,但是每次對象訪問都要查一下映射表,帶來了性能上的損失。
拷貝收集器
拷貝收集器把所有的活動對象移動到一個新的區域。這種方法在追蹤對象過程中隨著發現而被拷貝,不再有標記和清除的區分。一般的拷貝收集算法稱為“停止並拷貝”。在這個方案中,堆被分為兩個區域,任何時候只使用其中一個區域。對象在某一個區域中分配,直到這個區域被耗盡時,程序執行停止,遍歷這個區域,活動對象移到另一個區域,完成後程序恢復執行,對象在新的區域分配。原來的區域剩下垃圾,全清除。直到新的區域耗盡時,程序停止,活動對象又往回移,循環工作。這種方法的代價就是堆內存只能使用到一半。
下面是“停止和拷貝”算法的垃圾收集過程中以時間為線索的 9 個快照:
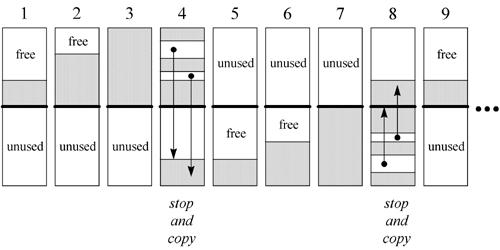
看過這個圖,應該不用多加解釋,反正就是堆分成上下兩個區域,哪部分滿了,活動對象往另一部分跑,被移出的區域剩下的對象全是垃圾,可以嘩一下全清空。來來回回,新對象總是在正用的那部份分配。想想你在運行 Java 程序的時候應該有過突然被中止不動的時候,可能就是 GC 在活動了。
分代收集器
簡單的停止拷貝收集器的缺點是,每次收集時,所有的活動對象都要移動來移動去。對於短生命的對象還好說,經常可以就地解決掉,可是對於長生命周期的對象就純粹是個體力勞動了,把它挪來挪去除消耗大量的時間,沒有產生任何效益。分代收集能直接讓長生命周期的對象長時間的呆在一個地方按兵不動。GC 的精力可以更多的花在收集短命對象上。
這種方法裡,堆被分成兩個或更多的子堆,每一個堆為一“代”對象服務。最年幼的那一代進行最頻繁的垃圾收集。因為多數對象是短命的,只有很小部分的年幼對象可以在經歷第一次收集後還存活。如果一個最年幼的對象經歷了好幾次垃圾收集後仍是活著的,那這個對象就成為壽命更高的一代,它被轉移到另外一個子堆中去。年齡更高一代的收集沒有年輕一代來得頻繁。每當對象在所屬的年齡代中變得成熟(多次垃圾收集後仍幸存)之後,就可以轉移到更高年齡的一代中去。
分代收集除了可應用於拷貝算法,也可以應用於標記清除算法。不管在哪種情況下,把堆按照對象年齡分組可以提高最基本的垃圾收集的性能。