學習Hibernate ,我們首先要知道為什麼要學習它?它有什麼好處?也就是我們為什麼要學習框架技術?
還要知道 什麼是Hibernate? 為什麼要使用Hibernate? Hibernate的配置文件的作用是什麼? Hibernate映射文件的作用是什麼? Hibernate持久化對象的狀態有哪些?
現在我先上面的問題解決了。
一。我們為什麼要學習框架技術?
1.框架技術有哪些?
在Java開發中,我們經常使用Struts、Hibernate和Spring三個主流框架.
我們知道,傳統的Java Web應用程序是采用JSP+Servlet+Javabean來實現的,這種模式實現了最基本的MVC分層,使的程序結構分為幾層,有負責前台展示的JSP、負責流程邏輯控制的Servlet以及負責數據封裝的Javabean。但是這種結構仍然存在問題:如JSP頁面中需要使用<%>符號嵌入很多的Java代碼,造成頁面結構混亂,Servlet和Javabean負責了大量的跳轉和運算工作,耦合緊密,程序復用度低等等。
Struts
為了解決這些問題,出現了Struts框架,它是一個完美的MVC實現,它有一個中央控制類(一個Servlet),針對不同的業務,我們需要一個Action類負責頁面跳轉和後台邏輯運算,一個或幾個JSP頁面負責數據的輸入和輸出顯示,還有一個Form類負責傳遞Action和JSP中間的數據。JSP中可以使用Struts框架提供的一組標簽,就像使用HTML標簽一樣簡單,但是可以完成非常復雜的邏輯。從此JSP頁面中不需要出現一行<%%>包圍的Java代碼了。
可是所有的運算邏輯都放在Struts的Action裡將使得Action類復用度低和邏輯混亂,所以通常人們會把整個Web應用程序分為三層,Struts負責顯示層,它調用業務層完成運算邏輯,業務層再調用持久層完成數據庫的讀寫。
使用JDBC連接來讀寫數據庫,我們最常見的就是打開數據庫連接、使用復雜的SQL語句進行讀寫、關閉連接,獲得的數據又需要轉換或封裝後往外傳,這是一個非常煩瑣的過程。
Hibernate
這時出現了Hibernate框架,它需要你創建一系列的持久化類,每個類的屬性都可以簡單的看做和一張數據庫表的屬性一一對應,當然也可以實現關系數據庫的各種表件關聯的對應。當我們需要相關操作是,不用再關注數據庫表。我們不用再去一行行的查詢數據庫,只需要持久化類就可以完成增刪改查的功能。使我們的軟件開發真正面向對象,而不是面向混亂的代碼。我的感受是,使用Hibernate比JDBC方式減少了80%的編程量。
現在我們有三個層了,可是每層之間的調用是怎樣的呢?比如顯示層的Struts需要調用一個業務類,就需要new一個業務類出來,然後使用;業務層需要調用持久層的類,也需要new一個持久層類出來用。通過這種new的方式互相調用就是軟件開發中最糟糕設計的體現。簡單的說,就是調用者依賴被調用者,它們之間形成了強耦合,如果我想在其他地方復用某個類,則這個類依賴的其他類也需要包含。程序就變得很混亂,每個類互相依賴互相調用,復用度極低。如果一個類做了修改,則依賴它的很多類都會受到牽連。 為此,出現Spring框架。
Spring
Spring的作用就是完全解耦類之間的依賴關系,一個類如果要依賴什麼,那就是一個接口。至於如何實現這個接口,這都不重要了。只要拿到一個實現了這個接口的類,就可以輕松的通過xml配置文件把實現類注射到調用接口的那個類裡。所有類之間的這種依賴關系就完全通過配置文件的方式替代了。所以Spring框架最核心的就是所謂的依賴注射和控制反轉。
現在的結構是,Struts負責顯示層,Hibernate負責持久層,Spring負責中間的業務層,這個結構是目前國內最流行的Java Web應用程序架構了。另外,由於Spring使用的依賴注射以及AOP(面向方面編程),所以它的這種內部模式非常優秀,以至於Spring自己也實現了一個使用依賴注射的MVC框架,叫做Spring MVC,同時為了很好的處理事物,Spring集成了Hibernate,使事物管理從Hibernate的持久層提升到了業務層,使用更加方便和強大。
Struts框架是2000年就開始起步了,到目前已經發展了5年,技術相當成熟,目前全球Java開發中Struts框架是顯示層技術中當之無愧的王者。它擁有大量的用戶群和很好的開發團隊。這也是國內大部分Java軟件公司對新進員工的基本要求。
上面我只是簡單的介紹了框架的出現原因,以及它們的優勢。
下面才是我要對Hibernate的精講。
1.什麼是Hibernate?
Hibernate是一個開放源代碼的對象關系映射框架,它對JDBC進行了非常輕量級的對象封裝,它將POJO與數據庫表建立映射關系,是一個全自動的orm框架,hibernate可以自動生成SQL語句,自動執行,使得Java程序員可以隨心所欲的使用對象編程思維來操縱數據庫。 Hibernate可以應用在任何使用JDBC的場合,既可以在Java的客戶端程序使用,也可以在Servlet/JSP的Web應用中使用,最具革命意義的是,Hibernate可以在應用EJB的J2EE架構中取代CMP,完成數據持久化的重任。
也可以這樣講:
01.它是連接Java應用程序和關系數據的中間件(組件)
中間件就是一種軟件的半成品,Hibernate就是幫忙我們解決操作數據庫的問題。以後我們就不需要用JAVA的CONNECTION等對象
由Hibernate操作JDBC,簡化我們操作數據庫,提高開發效率。
02.它對JDBC API進行了封裝,負責JAVA對象的持久化(就是保持到數據庫裡)
03.在分層軟件體系中它位於持久化層,封裝了所有數據訪問細節,使業務邏輯層可以專注於實現業務邏輯
04.它是一種ORM映射工具,能夠建立面向對象的域模型和關系數據模型之間的映射。
2,為什麼要使用Hibernate?
Hibernate是一個開放源代碼的對象關系映射框架,它對JDBC進行了非常輕量級的對象封裝,使得Java程序員可以隨心所欲的使用對象編程思維來操縱數據庫.
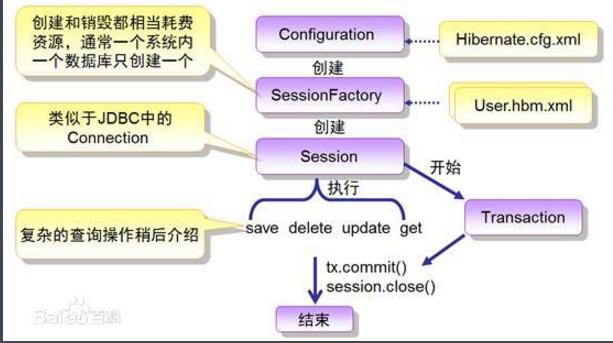
Hibernate工作原理:
01、讀取並解析配置文件
02、讀取並解析映射文件,創建SessionFactory
03、打開Session
04、創建事務Transaction
05、持久化操作
06、提交事務
07、關閉Session
08、關閉SessionFactory
至於我們為什麼要用Hibernate,就從Hibernate的四個優點來說:
首先、Hibernate對JDBC訪問數據庫的代碼做了封裝,大大簡化了數據訪問層繁瑣的重復性代碼。
其次、Hibernate是一個基於jdbc的主流持久化框架,是一個優秀的orm實現,它很大程度的簡化了dao層編碼工作。
再次、Hibernate使用java的反射機制,而不是字節碼增強程序類實現透明性
最後、Hibernate的性能非常好,因為它是一個輕量級框架。映射的靈活性很出色。它支持很多關系型數據庫,從一對一到多對多的各種復雜關系。
3.Hibernate的配置文件的作用是什麼?
01.映射java類和關系型數據庫的表。
02.使得對該類對象的操作可以映射到數據庫記錄的操作。
4.Hibernate的配置文件的參數的作用
在Hibernate配置文件中使用<set>, <list>, <map>, <bag>, <array> 和 <primitive-array>等元素來定義集合. <set name="propertyName" (1) table="table_name" (2) schema="schema_name" (3) lazy="true|false" (4) inverse="true|false" (5) cascade="all|none|save-update|delete|all-delete-orphan" (6) sort="unsorted|natural|comparatorClass" (7) order-by="column_name asc|desc" (8) where="arbitrary sql where condition" (9) outer-join="true|false|auto" (10) batch-size="N" (11) access="field|property|ClassName" (12) > <key .... /> <index .... /> <element .... /> </set>
(1) name 集合屬性的名稱
(2) table (可選——默認為屬性的名稱)這個集合表的名稱(不能在一對多的關聯關系中使用)
(3) schema (可選) 表的schema的名稱, 他將覆蓋在根元素中定義的schema
(4) lazy (可選——默認為false) lazy(可選--默認為false) 允許延遲加載(lazy initialization )(不能在數組中使用)
(5) inverse (可選——默認為false) 標記這個集合作為雙向關聯關系中的方向一端。
(6) cascade (可選——默認為none) 讓操作級聯到子實體
(7) sort(可選)指定集合的排序順序, 其可以為自然的(natural)或者給定一個用來比較的類。
(8) order-by (可選, 僅用於jdk1.4) 指定表的字段(一個或幾個)再加上asc或者desc(可選), 定義Map,Set和Bag的迭代順序
(9) where (可選) 指定任意的SQL where條件, 該條件將在重新載入或者刪除這個集合時使用(當集合中的數據僅僅是所有可用數據的一個子集時這個條件非常有用)
(10) outer-join(可選)指定這個集合,只要可能,應該通過外連接(outer join)取得。在每一個SQL語句中, 只能有一個集合可以被通過外連接抓取(譯者注: 這裡提到的SQL語句是取得集合所屬類的數據的Select語句)
(11) batch-size (可選, 默認為1) 指定通過延遲加載取得集合實例的批處理塊大小("batch size")。
(12) access(可選-默認為屬性property):Hibernate取得屬性值時使用的策略
5. Hibernate映射文件的作用是什麼?
Hibernate的持久化類和關系數據庫之間的映射通常是用一個XML文檔來定義的。該文檔通過一系列XML元素的配置,來將持久化類與數據庫表之間建立起一一映射。這意味著映射文檔是按照持久化類的定義來創建的,而不是表的定義。
它設定數據庫表與實體類進行關聯,讓用戶以面向對象的方式去操作持久化類(也就是實體bean),而不再是操作數據庫表,免去了用戶頻繁書寫sql語句的麻煩
01、根元素:<hibernate-mapping>,每一個hbm.xml文件都有唯一的一個根元素,包含一些可選的屬性
1)package:指定一個包前綴,如果在映射文檔中沒有指定全限定的類名,就使用這個作為包名,如
<hibernate-mapping package="com.demo.hibernate.beans">
<class name="User" ...>
</hibernate-mapping>
<hibernate-mapping>
<class name="com.demo.hibernate.beans.User" ...>
</hibernate-mapping>
2)schema:數據庫schema的名稱
3)catalog:數據庫catalog的名稱
4)default-cascade:默認的級聯風格,默認為none
5)default-access:Hibernate用來訪問屬性的策略
6)default-lazy:指定了未明確注明lazy屬性的Java屬性和集合類,Hibernate會采取什麼樣的默認加載風格,默認為true
7)auto-import:指定我們是否可以在查詢語言中使用非全限定的類名,默認為true,如果項目中有兩個同名的持久化類,則最好在這兩個類的對應的映射文件中配置為false
02、<class>定義類:根元素的子元素,用以定義一個持久化類與數據表的映射關系,如下是該元素包含的一些可選的屬性
1)name:持久化類(或者接口)的Java全限定名,如果這個屬性不存在,則Hibernate將假定這是一個非POJO的實體映射
2)table:對應數據庫表名
3)discriminator-value:默認和類名一樣,一個用於區分不同的子類的值,在多態行為時使用
4)mutable:表明該類的實例是可變的或者是不可變的
5)schema:覆蓋根元素<hibernate-mapping>中指定的schema名字
6)catalog:覆蓋根元素<hibernate-mapping>中指定的catalog名字
7)proxy:指定一個接口,在延遲裝載時作為代理使用
8)dynamic-update:指定用於UPDATE的SQL將會在運行時動態生成,並且只更新那些改變過的字段
9)dynamic-insert:指定用於INSERT的SQL將會在執行時動態生成,並且只包含那些非空值字段
10)select-before-update:指定HIbernate除非確定對象真正被修改了(如果該值為true),否則不會執行SQL UPDATE操作。在特定場合(實際上,它只在一個瞬時對象關聯到一個新的Session中時執行的update()中生效),這說明Hibernate會在UPDATE之前執行一次額外的SQL SELECT操作,來決定是否應該執行UPDATE
11)polymorphism:多態,界定是隱式還是顯式的多態查詢
12)where:指定定個附加的SQLWHERE條件,在抓取這個類的對象時會增加這個條件
13)persister:指定一個定制的ClassPersister
14)batch-size:指定一個用於根據標識符(identifier)抓取實例時使用的'batch size'(批次抓取數量)
15)optimistic-lock:樂觀鎖定,決定樂觀鎖定的策略
16)lazy:通過設置lazy="false",所有的延遲加載(Lazy fetching)功能將未被激活(disabled)
17)entity-name
18)check:這是一個SQL表達式,用於為自動生成的schema添加多行(multi-row)約束檢查
19)rowid
20)subselect
21)abstract:用於在<union-subclass>的繼承結構(hierarchies)中標識抽象超類
03、<id>定義主鍵:Hibernate使用OID(對象標識符)來標識對象的唯一性,OID是關系數據庫中主鍵在Java對象模型中的等價物,在運行時,Hibernate根據OID來維持Java對象和數據庫表中記錄的對應關系
1)name:持久化類的標識屬性的名字
2)type:標識Hibernate類型的名字
3)column:數據庫表的主鍵這段的名字
4)unsaved-value:用來標志該實例是剛剛創建的,尚未保存。可以用來區分對象的狀態
5)access:Hibernate用來訪問屬性值的策略
如果表使用聯合主鍵,那麼你可以映射類的多個屬性為標識符屬性。<composite-id>元素接受<key-property>屬性映射和<key-many-to-one>屬性映射作為子元素:
以下定義了兩個字段作為聯合主鍵:
<composite-id>
<key-property name="username" />
<key-property name="password" />
</composite-id>
04、<generator>設置主鍵生成方式
該元素的作用是指定主鍵的生成器,通過一個class屬性指定生成器對應的類。(通常與<id>元素結合使用)
<id name="id" column="ID" type="integer">
<generator class="native" />--native是Hibernate主鍵生成器的實現算法之一,由Hibernate根據底層數據庫自行判斷采用identity、hilo、sequence其中一種作為主鍵生成方式。
</id>
Hibernate提供的內置生成器:
1)assigned算法
2)hilo算法
3)seqhilo算法
4)increment算法
5)identity算法
6)sequence算法
7)native算法
8)uuid.hex算法
9)uuid.string算法
10)foregin算法
11)select算法
05、<property>定義屬性
用於持久化類的屬性與數據庫表字段之間的映射,包含如下屬性:
1)name:持久化類的屬性名,以小寫字母開頭
2)column:數據庫表的字段名
3)type:Hibernate映射類型的名字
4)update:表明用於UPDATE的SQL語句中是否包含這個被映射的字段,默認為true
5)insert:表明用於INSERT的SQL語句中是否包含這個被映射是否包含這個被映射的字段,默認為true
6)formula:一個SQL表達式,定義了這個計算屬性的值
7)access:Hibernate用來訪問屬性值的策略
8)lazy:指定實例變量第一次被訪問時,這個屬性是否延遲抓取,默認為false
9)unique:使用DDL為該字段添加唯一的約束,此外,這也可以用做property-ref的目標屬性
10)not-null:使用DDL為該字段添加可否為空的約束
11)optimistic-lock:指定這個屬性在進行更新時是否需要獲得樂觀鎖定(換句話說,它決定這個屬性發生髒數據時版本version的值是否增長)
access屬性用來讓你控制Hibernate如何在運行時訪問屬性。默認情況下,Hibernate會使用屬性的get/set方法對。如果你指明access="field",則Hibernate會忽略get/set方法對,直接使用反射來訪問成員變量。
formula屬性是個特別強大的的特征。這些屬性應該定義為只讀,屬性值在裝載時計算生成。用一個SQL表達式生成計算的結果,它會在這個實例轉載時翻譯成一個SQL查詢的SELECT子查詢語句。如:
<property name="totalPrice" formula="(SELECT SUM(*) FROM user)" />
6.Hibernate持久化對象的狀態有哪些?
持久化對象的三種狀態
Hibernate中的對象有3中狀態,瞬時對象(TransientObjects)、持久化對象(PersistentObjects)和離線對象(DetachedObjects也叫做脫管對象)。
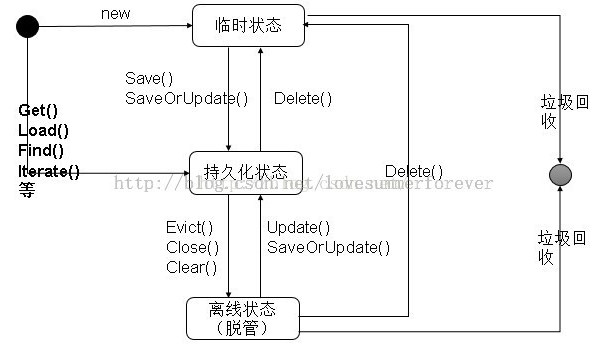
臨時狀態:由java的new命令開辟內存空間的java對象也就是普通的java對象,如果沒有變量引用它它將會被JVM收回。臨時對象在內存中是孤立存在的,它的意義是攜帶信息載體,不和數據庫中的數據由任何的關聯。通過Session的save()方法和saveOrUpdate()方法可以把一個臨時對象和數據庫相關聯,並把臨時對象攜帶的信息通過配置文件所做的映射插入數據庫中,這個臨時對象就成為持久化對象。
持久化狀態:持久化對象在數據庫中有相應的記錄,持久化對象可以是剛被保存的,或者剛被加載的,但都是在相關聯的session聲明周期中保存這個狀態。如果是直接數據庫查詢所返回的數據對象,則這些對象和數據庫中的字段相關聯,具有相同的id,它們馬上變成持久化對象。如果一個臨時對象被持久化對象引用,也立馬變為持久化對象。
如果使用delete()方法,持久化對象變為臨時對象,並且刪除數據庫中相應的記錄,這個對象不再與數據庫有任何的聯系。
持久化對象總是與Session和Transaction關聯在一起,在一個session中,對持久化對象的操作不會立即寫到數據庫,只有當Transaction(事務)結束時,才真正的對數據庫更新,從而完成持久化對象和數據庫的同步。在同步之前的持久化對象成為髒對象。
當一個session()執行close()、clear()、或evict()之後,持久化對象就變為離線對象,這時對象的id雖然擁有數據庫的識別值,但已經不在Hibernate持久層的管理下,他和臨時對象基本上一樣的,只不過比臨時對象多了數據庫標識id。沒有任何變量引用時,jvm將其回收。
游離態或脫管態:Session關閉之後,與此Session關聯的持久化對象就變成為脫管對象,可以繼續對這個對象進行修改,如果脫管對象被重新關聯到某個新的Session上,會在此轉成持久對象。
脫管對象雖然擁有用戶的標識id,所以通過update()、saveOrUpdate()等方法,再次與持久層關聯。
Session對各種狀態實體對象進行操作的可能結果如下表所示。
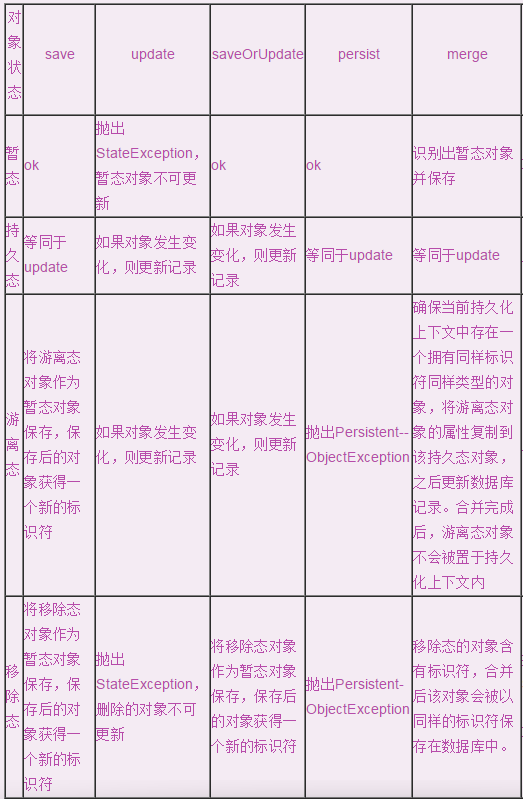
在項目開發中,通常使用工具類來管理SessionFactory和Session
當我們建立Session都要實例化SessionFactory,所以我們把重復的代碼進行封裝,並且session是單線程的。我們把對session的管理,打開session,關閉session等封裝到工具類中,代碼如下所示。
package cn.hibernate.util;
import org.hibernate.Session;
import org.hibernate.SessionFactory;
import org.hibernate.cfg.Configuration;
public class HibernateUtil {
//1.初始化一個 ThreadLocal 對象
private static final ThreadLocal<Session> sessionTL=new ThreadLocal<Session>();
private static Configuration configuration;
private final static SessionFactory sessionFactory;
static{
configuration=new Configuration().configure();
sessionFactory=configuration.buildSessionFactory();
}
public static Session currentSession(){
//2.返回當前的線程其對應的線程內部變量
Session session=sessionTL.get();
//如果當前線程是session 為空=null ,則打開一個新的Session
if(session==null){
//創建一個session對象
session=sessionFactory.openSession();
//保存該Sessioon對象到ThreadLocal中
sessionTL.set(session);
}
return session;
}
//關閉Session
public static void closeSessio(){
Session session=sessionTL.get();
sessionTL.set(null);
session.close();
}
}
Hibernate的重要的核心類和接口
分別為:Session、SessionFactory、Transaction、Query、Criteria和Configuration。這6個核心類和接口在任何開發中都會用到。通過這些接口,不僅可以對持久化對象進行存取,還能夠進行事務控制
<id name="deptNo" column="DEPTNO">
<generator class="Assigned"/>
</id>
還要注意開關:
<!--序列化 -->
<property name="hbm2ddl.auto">update</property>
<id name="gradeId" column="GRADEID">
<generator class="sequence">
<param name="sequence">SEQ_NUM</param>
</generator>
</id>
還要注意開關:
<!--序列化 -->
<property name="hbm2ddl.auto">update</property>
<!--name對應的是實體類的屬性 -->
<!--column對應的是數據庫裡面 的列 -->
<id name="deptNo" column="DEPTNO">
<generator class="native"/>
</id>
還要注意開關:
<!--序列化 -->
<property name="hbm2ddl.auto">update</property>
當Session緩存中對象的屬性每次發生了變化,Session並不會立即清理緩存和執行相關的SQL update語句,而是在特定的時間點才清理緩存,這使得Session能夠把幾條相關的SQL語句合並為一條SQL語句,一遍減少訪問數據庫的次數,從而提高應用程序的數據訪問性能。
在默認情況下,Session會在以下時間點清理緩存。
Session進行清理緩存的例外情況是,如果對象使用native生成器來生成OID,那麼當調用Session的save()方法保存該對象時,會立即執行向數據庫插入該實體的insert語句。

最後呢,還有很多知識沒有寫上去,有時間我繼續補上去的!!!
謝謝大家的浏覽