閱讀目錄
1. 寫在前面的話
1.1. 關於netty example
1.2. 關於github項目
2. HTTP 協議知多少
2.1. GET請求
2.2. POST請求
2.3. HTTP POST Content-Type
3. netty HTTP 編解碼
3.1. netty 自帶 HTTP 編解碼器
3.2. HTTP GET 解析實踐
3.3. HTTP POST 解析實踐
4. 自定義 HTTP POST 的 message body 解碼器
4.1. HttpJsonDecoder
4.2. HttpProtobufDecoder
5. 聊聊開發中遇到的問題【推薦】
5.1. 關於內存洩漏
5.1.1. netty 應用計數對象
5.1.2. 如何規避內存洩漏
5.2. 關於 HTTP 長連接
5.2.1. TCP KeepAlive 和 HTTP KeepAlive
5.2.2. 長連接方式中如何判斷數據發送完成
1. 說在前面的話
前段時間,工作上需要做一個針對視頻質量的統計分析系統,各端(PC端、移動端和 WEB端)將視頻質量數據放在一個 HTTP 請求中上報到服務器,服務器對數據進行解析、分揀後從不同的維度做實時和離線分析。(ps:這種活兒本該由統計部門去做的,但由於各種原因落在了我頭上,具體原因略過不講……)
先用個“概念圖”來描繪下整個系統的架構:
首先,接入服務需要支持10W+ tps,而 netty 的多線程模型和異步非阻塞的特性讓人很自然就會將它和高並發聯系起來。
基於以上幾點原因,老夫就決定使用 netty HTTP 協議棧開干啦~
本文並非純理論或純技術類文章,而是結合理論進而實踐(雖然沒有特別深入的實踐),淺析 netty 的 HTTP 協議棧,並著重聊聊實踐中遇到的問題及解決方案。越往後越精彩哦!
1.1. 關於netty example
netty 官方提供了關於 HTTP 的例子,大伙兒可以在 netty 項目中查看。
1.2. 關於github項目
本人在網上使用 “netty + HTTP” 的關鍵字搜索了下,發現大部分都是原搬照抄 netty 項目中的 example,很少有“原創性”的實踐,也幾乎沒有看到實現一個相對完整的 HTTP 服務器的項目(比如如何解析GET/POST請求、自定義 HTTP decoder、對 HTTP 長短連接的思考等等……),因此就自己整理了一個相對完整一點的項目,項目地址https://github.com/cyfonly/netty-http,該項目實現了基於 netty5 的 HTTP 服務端,暫時實現以下功能:
將來可能會繼續實現的功能有:
如果你也打算使用 netty 來實現 HTTP 服務器,相信這個項目和本文對你是有較大幫助的!
好了,閒話不多說,下面正式進入正題。
2. HTTP 協議知多少
要通過 netty 實現 HTTP 服務端(或者客戶端),首先你得了解 HTTP 協議【1】。
HTTP 協議是請求/響應式的協議,客戶端需要發送一個請求,服務器才會返回響應內容。例如在浏覽器上輸入一個網址按下 Enter,或者提交一個 Form 表單,浏覽器就會發送一個請求到服務器,而打開的網頁的內容,就是服務器返回的響應。
下面講下 HTTP 請求和響應包含的內容。
HTTP 請求有很多種 method,最常用的就是 GET 和 POST,每種 method 的請求之間會有細微的區別。下面分別分析一下 GET 和 POST 請求。
2.1. GET請求
下面是浏覽器對 http://localhost:8081/test?name=XXG&age=23 的 GET 請求時發送給服務器的數據:

可以看出請求包含 request line 和 header 兩部分。其中 request line 中包含 method(例如 GET、POST)、request uri 和 protocol version 三部分,三個部分之間以空格分開。request line 和每個 header 各占一行,以換行符 CRLF(即 \r\n)分割。
2.2. POST請求
下面是浏覽器對 http://localhost:8081/test 的 POST 請求時發送給服務器的數據,同樣帶上參數 name=XXG&age=23:
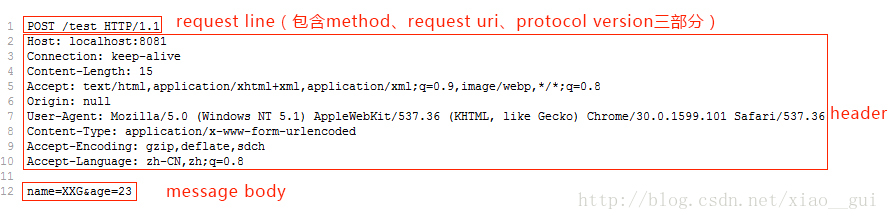
可以看出,上面的請求包含三個部分:request line、header、message,比之前的 GET 請求多了一個 message body,其中 header 和 message body 之間用一個空行分割。POST 請求的參數不在 URL 中,而是在 message body 中,header 中多了一項 Content-Length 用於表示 message body 的字節數,這樣服務器才能知道請求是否發送結束。這也就是 GET 請求和 POST 請求的主要區別。
HTTP 響應和 HTTP 請求非常相似,HTTP 響應包含三個部分:status line、header、massage body。其中 status line 包含 protocol version、狀態碼(status code)、reason phrase 三部分。狀態碼用於描述 HTTP 響應的狀態,例如 200 表示成功,404 表示資源未找到,500 表示服務器出錯。

在上面的 HTTP 響應中,Header 中的 Content-Length 同樣用於表示 message body 的字節數。Content-Type 表示 message body 的類型,通常浏覽網頁其類型是HTML,當然還會有其他類型,比如圖片、視頻等。
2.3. HTTP POST Content-Type
HTTP/1.1 協議規定的 HTTP 請求方法有 OPTIONS、GET、HEAD、POST、PUT、DELETE、TRACE、CONNECT 這幾種。其中 POST 一般用來向服務端提交數據,本文討論主要的幾種 POST 提交數據方式。
我們知道,HTTP 協議是以 ASCII 碼傳輸,建立在 TCP/IP 協議之上的應用層規范。規范把 HTTP 請求分為三個部分:狀態行、請求頭、消息主體。類似於下面這樣:
<method> <request-URL> <version> <headers> <entity-body>
協議規定 POST 提交的數據必須放在消息主體(entity-body)中,但協議並沒有規定數據必須使用什麼編碼方式。實際上,開發者完全可以自己決定消息主體的格式,只要最後發送的 HTTP 請求滿足上面的格式就可以。
但是,數據發送出去,還要服務端解析成功才有意義。一般服務端語言如 php、python 等,以及它們的 framework,都內置了自動解析常見數據格式的功能。服務端通常是根據請求頭(headers)中的 Content-Type 字段來獲知請求中的消息主體是用何種方式編碼,再對主體進行解析。所以說到 POST 提交數據方案,包含了 Content-Type 和消息主體編碼方式 Charset 兩部分。下面就正式開始介紹它們。
2.3.1. application/x-www-form-urlencoded
這應該是最常見的 POST 提交數據的方式了。浏覽器的原生 Form 表單,如果不設置 enctype 屬性,那麼最終就會以 application/x-www-form-urlencoded 方式提交數據。請求類似於下面這樣(無關的請求頭在本文中都省略掉了):
POST http://www.example.com HTTP/1.1 Content-Type: application/x-www-form-urlencoded;charset=utf-8 title=test&sub%5B%5D=1&sub%5B%5D=2&sub%5B%5D=3
首先,Content-Type 被指定為 application/x-www-form-urlencoded;其次,提交的數據按照 key1=val1&key2=val2 的方式進行編碼,key 和 val 都進行了 URL 轉碼。大部分服務端語言都對這種方式有很好的支持。
很多時候,我們用 Ajax 提交數據時,也是使用這種方式。例如 JQuery 的 Ajax,Content-Type 默認值都是 application/x-www-form-urlencoded;charset=utf-8 。
2.3.2. multipart/form-data
這又是一個常見的 POST 數據提交的方式。我們使用表單上傳文件時,必須讓 Form 的 enctyped 等於這個值。直接來看一個請求示例:
POST http://www.example.com HTTP/1.1 Content-Type:multipart/form-data; boundary=----WebKitFormBoundaryrGKCBY7qhFd3TrwA ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="text" title ------WebKitFormBoundaryrGKCBY7qhFd3TrwA Content-Disposition: form-data; name="file"; filename="chrome.png" Content-Type: image/png PNG ... content of chrome.png ... ------WebKitFormBoundaryrGKCBY7qhFd3TrwA--
這個例子稍微復雜點。首先生成了一個 boundary 用於分割不同的字段,為了避免與正文內容重復,boundary 很長很復雜。然後 Content-Type 裡指明了數據是以 mutipart/form-data 來編碼,本次請求的 boundary 是什麼內容。消息主體裡按照字段個數又分為多個結構類似的部分,每部分都是以 –boundary 開始,緊接著內容描述信息,然後是回車,最後是字段具體內容(文本或二進制)。如果傳輸的是文件,還要包含文件名和文件類型信息。消息主體最後以 –boundary– 標示結束。
這種方式一般用來上傳文件,各大服務端語言對它也有著良好的支持。
上面提到的這兩種 POST 數據的方式,都是浏覽器原生支持的,而且現階段原生 Form 表單也只支持這兩種方式。但是隨著越來越多的 Web 站點,尤其是 WebApp,全部使用 Ajax 進行數據交互之後,我們完全可以定義新的數據提交方式,給開發帶來更多便利。
2.3.3. application/json
application/json 這個 Content-Type 作為響應頭大家肯定不陌生。實際上,現在越來越多的人把它作為請求頭,用來告訴服務端消息主體是序列化後的 JSON 字符串。由於 JSON 規范的流行,除了低版本 IE 之外的各大浏覽器都原生支持 JSON.stringify,服務端語言也都有處理 JSON 的函數,使用 JSON 不會遇上什麼麻煩。
JSON 格式支持比鍵值對復雜得多的結構化數據,這一點也很有用,當需要提交的數據層次非常深,就可以考慮把數據 JSON 序列化之後來提交的。
var data = {'title':'test', 'sub' : [1,2,3]};
$http.post(url, data).success(function(result) {
...
});
最終發送的請求是:
POST http://www.example.com HTTP/1.1
Content-Type: application/json;charset=utf-8
{"title":"test","sub":[1,2,3]}
這種方案,可以方便的提交復雜的結構化數據,特別適合 RESTful 的接口。各大抓包工具如 Chrome 自帶的開發者工具、Fiddler,都會以樹形結構展示 JSON 數據,非常友好。
其他幾種 Content-Type 就不一一詳細介紹了,感興趣的童鞋請自行了解。下面進入 netty 支持 HTTP 協議的源碼分析階段。
3. netty HTTP 編解碼
要通過 netty 處理 HTTP 請求,需要先進行編解碼。
3.1. netty 自帶 HTTP 編解碼器
netty5 提供了對 HTTP 協議的幾種編解碼器:
3.1.1. HttpRequestDecoder
Decodes ByteBuf into HttpRequest and HttpContent.
即把 ByteBuf 解碼到 HttpRequest 和 HttpContent。
3.1.2. HttpResponseEncoder
Encodes an HttpResponse or an HttpContent into a ByteBuf.
即把 HttpResponse 或 HttpContent 編碼到 ByteBuf。
3.1.3. HttpServerCodec
A combination of HttpRequestDecoder and HttpResponseEncoder which enables easier server side HTTP implementation.
即 HttpRequestDecoder 和 HttpResponseEncoder 的結合。
因此,基於 netty 實現 HTTP 服務端時,需要在 ChannelPipeline 中加上以上編解碼器:
ch.pipeline().addLast("codec",new HttpServerCodec())
或者
ch.pipeline().addLast("decoder",new HttpRequestDecoder())
.addLast("encoder",new HttpResponseEncoder())
然而,以上編解碼器只能夠支持部分 HTTP 請求解析,比如 HTTP GET請求所傳遞的參數是包含在 uri 中的,因此通過 HttpRequest 既能解析出請求參數。但是,對於 HTTP POST 請求,參數信息是放在 message body 中的(對應於 netty 來說就是 HttpMessage),所以以上編解碼器並不能完全解析 HTTP POST請求。
這種情況該怎麼辦呢?別慌,netty 提供了一個 handler 來處理。
3.1.4. HttpObjectAggregator
A ChannelHandler that aggregates an HttpMessage and its following HttpContent into a single FullHttpRequest or FullHttpResponse (depending on if it used to handle requests or responses) with no following HttpContent. It is useful when you don't want to take care of HTTP messages whose transfer encoding is 'chunked'.
即通過它可以把 HttpMessage 和 HttpContent 聚合成一個 FullHttpRequest 或者 FullHttpResponse (取決於是處理請求還是響應),而且它還可以幫助你在解碼時忽略是否為“塊”傳輸方式。
因此,在解析 HTTP POST 請求時,請務必在 ChannelPipeline 中加上 HttpObjectAggregator。(具體細節請自行查閱代碼)
當然,netty 還提供了其他 HTTP 編解碼器,有些涉及到高級應用(較復雜的應用),在此就不一一解釋了,以上只是介紹netty HTTP 協議棧最基本的編解碼器(切合文章主題——淺析)。
3.2. HTTP GET 解析實踐
上面提到過,HTTP GET 請求的參數是包含在 uri 中的,可通過以下方式解析出 uri:
HttpRequest request = (HttpRequest) msg; String uri = request.uri();
特別注意的是,用浏覽器發起 HTTP 請求時,常常會被 uri = "/favicon.ico" 所干擾,因此最好對其特殊處理:
if(uri.equals(FAVICON_ICO)){
return;
}
接下來就是解析 uri 了。這裡需要用到 QueryStringDecoder:
Splits an HTTP query string into a path string and key-value parameter pairs.
This decoder is for one time use only. Create a new instance for each URI:
QueryStringDecoder decoder = new QueryStringDecoder("/hello?recipient=world&x=1;y=2");
assert decoder.getPath().equals("/hello");
assert decoder.getParameters().get("recipient").get(0).equals("world");
assert decoder.getParameters().get("x").get(0).equals("1");
assert decoder.getParameters().get("y").get(0).equals("2");
This decoder can also decode the content of an HTTP POST request whose
content type is application/x-www-form-urlencoded:
QueryStringDecoder decoder = new QueryStringDecoder("recipient=world&x=1;y=2", false);
...
從上面的描述可以看出,QueryStringDecoder 的作用就是把 HTTP uri 分割成 path 和 key-value 參數對,也可以用來解碼 Content-Type = "application/x-www-form-urlencoded" 的 HTTP POST。特別注意的是,該 decoder 僅能使用一次。
解析代碼如下:
String uri = request.uri();
HttpMethod method = request.method();
if(method.equals(HttpMethod.GET)){
QueryStringDecoder queryDecoder = new QueryStringDecoder(uri, Charsets.toCharset(CharEncoding.UTF_8));
Map<String, List<String>> uriAttributes = queryDecoder.parameters();
//此處僅打印請求參數(你可以根據業務需求自定義處理)
for (Map.Entry<String, List<String>> attr : uriAttributes.entrySet()) {
for (String attrVal : attr.getValue()) {
System.out.println(attr.getKey() + "=" + attrVal);
}
}
}
3.3. HTTP POST 解析實踐
如3.1.4小結所說的那樣,解析 HTTP POST 請求的 message body,一定要使用 HttpObjectAggregator。但是,是否一定要把 msg 轉換成 FullHttpRequest 呢?答案是否定的,且往下看。
首先解釋下 FullHttpRequest 是什麼:
Combinate the HttpRequest and FullHttpMessage, so the request is a complete HTTP request.
即 FullHttpRequest 包含了 HttpRequest 和 FullHttpMessage,是一個 HTTP 請求的完全體。
而把 msg 轉換成 FullHttpRequest 的方法很簡單:
FullHttpRequest fullRequest = (FullHttpRequest) msg;
接下來就是分幾種 Content-Type 進行解析了。
3.3.1. 解析 application/json
處理 JSON 格式是非常方便的,我們只需要將 msg 轉換成 FullHttpRequest,然後將其 content 反序列化成 JSONObject 對象即可,如下:
FullHttpRequest fullRequest = (FullHttpRequest) msg;
String jsonStr = fullRequest.content().toString(Charsets.toCharset(CharEncoding.UTF_8));
JSONObject obj = JSON.parseObject(jsonStr);
for(Entry<String, Object> item : obj.entrySet()){
System.out.println(item.getKey()+"="+item.getValue().toString());
}
3.3.2. 解析 application/x-www-form-urlencoded
解析此類型有兩種方法,一種是使用 QueryStringDecoder,另外一種就是使用 HttpPostRequestDecoder。
方法一:3.2節中講 QueryStringDecoder 時提到:QueryStringDecoder 可以用來解碼 Content-Type = "application/x-www-form-urlencoded" 的 HTTP POST。因此我們可以用它來解析 message body,剩下的處理就跟 HTTP GET沒什麼兩樣了:
FullHttpRequest fullRequest = (FullHttpRequest) msg;
String jsonStr = fullRequest.content().toString(Charsets.toCharset(CharEncoding.UTF_8));
QueryStringDecoder queryDecoder = new QueryStringDecoder(jsonStr, false);
Map<String, List<String>> uriAttributes = queryDecoder.parameters();
for (Map.Entry<String, List<String>> attr : uriAttributes.entrySet()) {
for (String attrVal : attr.getValue()) {
System.out.println(attr.getKey()+"="+attrVal);
}
}
方法二:使用 HttpPostRequestDecoder 解析時,無需先將 msg 轉換成 FullHttpRequest。
我們先來了解下 HttpPostRequestDecoder :
public HttpPostRequestDecoder(HttpDataFactory factory, HttpRequest request, Charset charset) {
if (factory == null) {
throw new NullPointerException("factory");
}
if (request == null) {
throw new NullPointerException("request");
}
if (charset == null) {
throw new NullPointerException("charset");
}
// Fill default values
if (isMultipart(request)) {
decoder = new HttpPostMultipartRequestDecoder(factory, request, charset);
} else {
decoder = new HttpPostStandardRequestDecoder(factory, request, charset);
}
}
由它的定義可知,它的內部實現其實有兩種方式,一種是針對 multipart 類型的解析,一種是普通類型的解析。這兩種方式的具體實現中,我把它們相同的代碼提取出來,如下:
if (request instanceof HttpContent) {
// Offer automatically if the given request is als type of HttpContent
offer((HttpContent) request);
} else {
undecodedChunk = buffer();
parseBody();
}
由於我們使用過 HttpObjectAggregator, request 都是 HttpContent 類型,因此會 Offer automatically,我們就不必自己手動去 offer 了,也不用處理 Chunk,所以使用 HttpObjectAggregator 確實是帶來了很多簡便的。
好了,接下來就是使用 HttpPostRequestDecoder 來解析了,直接上代碼:
HttpRequest request = (HttpRequest) msg;
HttpPostRequestDecoder decoder = new HttpPostRequestDecoder(factory, request, Charsets.toCharset(CharEncoding.UTF_8));
List<InterfaceHttpData> datas = decoder.getBodyHttpDatas();
for (InterfaceHttpData data : datas) {
if(data.getHttpDataType() == HttpDataType.Attribute) {
Attribute attribute = (Attribute) data;
System.out.println(attribute.getName() + "=" + attribute.getValue());
}
}
是不是很簡單?沒錯。但是這裡有點我要說明下, InterfaceHttpData 是一個interface,沒有 API 可以直接拿到它的 value。那怎麼辦呢?莫方,在它的類內部定義了個枚舉類型,如下:
enum HttpDataType {
Attribute, FileUpload, InternalAttribute
}
這種情況下它是 Attribute 類型,因此你轉換一下就能拿到值了。好奇的你可能會問,除 Attribute 外,其他兩個是什麼時候用呢?沒錯,接下來馬上就講 FileUpload,至於 InternalAttribute 嘛,老夫就不多說啦,有興趣可以自己去研究了哈~
3.3.3. 解析 multipart/form-data (文件上傳)
上面說到了 FileUpload,那在這裡就來說說如何使用 netty HTTP 協議棧實現文件上傳和保存功能。
這裡依然使用 HttpPostRequestDecoder,廢話就不多少了,直接上代碼:
DiskFileUpload.baseDirectory = "/data/fileupload/";
HttpRequest request = (HttpRequest) msg;
HttpPostRequestDecoder decoder = new HttpPostRequestDecoder(factory, request, Charsets.toCharset(CharEncoding.UTF_8));
List<InterfaceHttpData> datas = decoder.getBodyHttpDatas();
for (InterfaceHttpData data : datas) {
if(data.getHttpDataType() == HttpDataType.FileUpload) {
FileUpload fileUpload = (FileUpload) data;
String fileName = fileUpload.getFilename();
if(fileUpload.isCompleted()) {
//保存到磁盤
StringBuffer fileNameBuf = new StringBuffer();
fileNameBuf.append(DiskFileUpload.baseDirectory).append(fileName);
fileUpload.renameTo(new File(fileNameBuf.toString()));
}
}
}
至於效果,你可以直接在本地起個服務搞個簡單的頁面,向服務器傳個文件就行了。如果你很懶,直接用下面的HTML代碼改改將就著用吧:
<form action="http://localhost:8080" method="post" enctype ="multipart/form-data"> <input id="File1" runat="server" name="UpLoadFile" type="file" /> <input type="submit" name="Button" value="上傳" id="Button" /> </form>
至於其他類型的 Method、其他類型的 Content-Type,我也不打算細無巨細一一給大伙兒詳細講解了,看看上面羅列的,其實都很簡單是不是?
上面說的都是 netty 自己實現的東西,下面就來講講如何實現一個簡單的 HTTP decoder。
4. 自定義 HTTP POST 的 message body 解碼器
關於解碼器,我也不打算實現很復雜很牛逼的,只是寫了兩個粗糙的 decoder,一個是帶參數的一個是不帶參數的。既然是淺析,那就下面就簡單的聊聊。
如果你要實現一個頂層解碼器,就要繼承 MessageToMessageDecoder 並重寫其 decode 方法。MessageToMessageDecoder 繼承了 ChannelHandlerAdapter,也就是說解碼器其實就是一個 handler,只不過是專門用來做解碼的事情。下面我們來看看它重寫的 channelRead 方法:
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
RecyclableArrayList out = RecyclableArrayList.newInstance();
try {
if (acceptInboundMessage(msg)) {
@SuppressWarnings("unchecked")
I cast = (I) msg;
try {
decode(ctx, cast, out);
} finally {
ReferenceCountUtil.release(cast);
}
} else {
out.add(msg);
}
} catch (DecoderException e) {
throw e;
} catch (Exception e) {
throw new DecoderException(e);
} finally {
int size = out.size();
for (int i = 0; i < size; i ++) {
ctx.fireChannelRead(out.get(i));
}
out.recycle();
}
}
其中 decode 方法是你實現 decoder 時需要重寫的,經過解碼之後,會調用 ctx.fireChannelRead() 將 out 傳遞給給下一個 handler 執行相關邏輯。
4.1. HttpJsonDecoder
從名字可以看出,這是個針對 message body 為 JsonString 的解碼器。處理過程很簡單,只需要把 HTTP 請求的 content (即 ByteBuf)的可讀字節轉換成 JSONObject 對象,如下:
@Override
protected void decode(ChannelHandlerContext ctx, HttpRequest msg, List<Object> out) throws Exception {
FullHttpRequest fullRequest = (FullHttpRequest) msg;
ByteBuf content = fullRequest.content();
int length = content.readableBytes();
byte[] bytes = new byte[length];
for(int i=0; i<length; i++){
bytes[i] = content.getByte(i);
}
try{
JSONObject obj = JSON.parseObject(new String(bytes));
out.add(obj);
}catch(ClassCastException e){
throw new CodecException("HTTP message body is not a JSONObject");
}
}
使用方法也很簡單,在 Server 的 HttpServerCodec() 和 HttpObjectAggregator() 後面加上:
.addLast("jsonDecoder", new HttpJsonDecoder())
然後在業務 handler channelRead方法中使用即可:
if(msg instanceof JSONObject){
JSONObject obj = (JSONObject) msg;
......
}
4.2. HttpProtobufDecoder
這是一個帶參數的 decoder,用來解析使用 protobuf 序列化後的 message body。使用的時候需要傳遞 MessageLite 進來,直接上代碼:
private final MessageLite prototype;
public HttpProtobufDecoder(MessageLite prototype){
if (prototype == null) {
throw new NullPointerException("prototype");
}
this.prototype = prototype.getDefaultInstanceForType();
}
@Override
protected void decode(ChannelHandlerContext ctx, HttpRequest msg, List<Object> out) {
FullHttpRequest fullRequest = (FullHttpRequest) msg;
ByteBuf content = fullRequest.content();
int length = content.readableBytes();
byte[] bytes = new byte[length];
for(int i=0; i<length; i++){
bytes[i] = content.getByte(i);
}
try {
out.add(prototype.getParserForType().parseFrom(bytes, 0, length));
} catch (InvalidProtocolBufferException e) {
throw new CodecException("HTTP message body is not " + prototype + "type");
}
}
使用方法跟 HttpJsonDecoder無異。此處以 protobuf 對象 UserProtobuf.User 為例,在 Server 的 HttpServerCodec() 和 HttpObjectAggregator() 後面加上:
.addLast("protobufDecoder", new HttpProtobufDecoder(UserProbuf.User.getDefaultInstance()))
然後在業務 handler channelRead方法中使用即可:
if(msg instanceof UserProbuf.User){
UserProbuf.User user = (UserProbuf.User) msg;
......
}
5. 聊聊開發中遇到的問題【推薦】
如果你沒有親自使用過 netty 卻說自己熟悉甚至精通 netty,我勸你千萬別這麼做,因為你的臉會被打腫的。netty 作為一個異步非阻塞的 IO 框架,它到底多牛逼在這就不多扯了,而作為一個首次使用 netty HTTP 協議棧的我來說,踩坑是必不可少的過程。當然了,踩了坑就要填上,我還很樂意在這把我踩過的幾個坑給大家分享下,前車之鑒。
5.1. 關於內存洩漏
首先說下經歷的情況。在文章開篇提到的接收服務,經過多輪的單元測試幾乎沒發現什麼問題,於是對於接下來的壓力測試我是自信滿滿。然而,當我第一次跑壓測時就拋出一個異常,如下:
[ERROR] 2016-07-24 15:25:46 [io.netty.util.internal.logging.Slf4JLogger:176] - LEAK: ByteBuf.release() was not called before it's garbage-collected. Enable advanced leak reporting to find out where the leak occurred. To enable advanced leak reporting, specify the JVM option '-Dio.netty.leakDetectionLevel=advanced' or call ResourceLeakDetector.setLevel() See http://netty.io/wiki/reference-counted-objects.html for more information.
著實讓我開心了一把,終於出現異常了!異常信息表達的是 “ByteBuf 在被 JVM GC 之前沒有調用 ByteBuf.release() ,啟用高級洩漏報告,找出發生洩漏的地方”,於是馬上google了一把,原來是從 netty4 開始,對象的生命周期由它們的引用計數(reference counts)管理,而不是由垃圾收集器(garbage collector)管理了。
要解決這個問題,先從源頭了解開始。
5.1.1. netty 引用計數對象【2】
對於 netty Inbound message,當 event loop 讀入了數據並創建了 ByteBuf,並用這個 ByteBuf 觸發了一個 channelRead() 事件時,那麼管道(pipeline)中相應的ChannelHandler 就負責釋放這個 buffer 。因此,處理接數據的 handler 應該在它的 channelRead() 中調用 buffer 的 release(),如下:
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ByteBuf buf = (ByteBuf) msg;
try {
...
} finally {
buf.release();
}
}
而有時候,ByteBuf 會被一個 buffer holder 持有,它們都擴展了一個公共接口 ByteBufHolder。正因如此, ByteBuf 並不是 netty 中唯一一種引用計數對象。由 decoder 生成的消息對象很可能也是引用計數對象,比如 HTTP 協議棧中的 HttpContent,因為它也擴展了 ByteBufHolder。
public void channelRead(ChannelHandlerContext ctx, Object msg) {
if (msg instanceof HttpRequest) {
HttpRequest req = (HttpRequest) msg;
...
}
if (msg instanceof HttpContent) {
HttpContent content = (HttpContent) msg;
try {
...
} finally {
content.release();
}
}
}
如果你抱有疑問,或者你想簡化這些釋放消息的工作,你可以使用 ReferenceCountUtil.release():
public void channelRead(ChannelHandlerContext ctx, Object msg) {
try {
...
} finally {
ReferenceCountUtil.release(msg);
}
}
或者可以考慮繼承 SimpleChannelHandler,它在所有接收消息的地方都調用了 ReferenceCountUtil.release(msg)。
對於 netty Outbound message,你的程序所創建的消息對象都由 netty 負責釋放,釋放的時機是在這些消息被發送到網絡之後。但是,在發送消息的過程中,如果有 handler 截獲(intercept)了你的發送請求並創建了一些中間對象,則這些 handler 要確保正確釋放這些中間對象。比如 encoder,此處不贅述。
通過以上信息,自然就很容易找到 OOM 問題的原因所在了。由於在處理 HTTP 請求過程中沒有釋放 ByteBuf,因此在代碼 finally 塊中加上 ReferenceCountUtil.release(msg) 就解決啦!
5.1.2. 如何規避內存洩漏【3】
netty 提供了內存洩漏的監測機制,默認就會從分配的 ByteBuf 裡抽樣出大約 1% 的來進行跟蹤。如果洩漏,就會打印5.1.1節中的異常信息,並提示你通過指定 JVM 選項
-Dio.netty.leakDetectionLevel=advanced
來查看洩漏報告。洩漏年監測有4個等級:
一般情況下我們采用 SIMPLE 級別即可。
5.2. 關於 HTTP 長連接
按照慣例,先說下開發中踩到的坑。
對於接收服務,我采用的是 nginx + netty http,其中 nginx 配置如下(閹割隱藏版):
upstream xxx.com{
keepalive 32;
server xxxx.xx.xx.xx:8080;
}
server{
listen 80;
server_name xxx.com;
location / {
proxy_next_upstream http_502 http_504 error timeout invalid_header;
proxy_pass xxx.com;
proxy_http_version 1.1;
proxy_set_header Connection "";
#proxy_set_header Host $host;
#proxy_set_header X-Forwarded-For $remote_addr;
#proxy_set_header REMOTE_ADDR $remote_addr;
#proxy_set_header X-Real-IP $remote_addr;
proxy_read_timeout 60s;
client_max_body_size 1m;
}
error_page 500 502 503 504 /50x.html;
location = /50x.html{
root html;
}
}
然後編寫了一個簡單的 HttpClient 發送消息,如下(截取):
OutputStream outStream = conn.getOutputStream();
outStream.write(data);
outStream.flush();
outStream.close();
if (conn.getResponseCode() == 200) {
BufferedReader in = new BufferedReader(new InputStreamReader((InputStream) conn.getInputStream(), "UTF-8"));
String msg = in.readLine();
System.out.println("msg = " + msg);
in.close();
}
conn.disconnect();
接著,正常發送 HTTP 請求到服務器,然而,老夫整整等了60多秒才接到響應信息!而且每次都這樣!!
我首先懷疑是不是 ngxin 出問題了,有一個配置項立馬引起了我的懷疑,沒錯,就是上面紅色的那行 proxy_read_timeout 60s; 。為了驗證,我首先把 60s 改成了 10s,效果很明顯,發送的請求 10 秒過一點就收到響應了!更加徹底證明是 nginx 的鍋,我去掉了 nginx,讓客戶端直接發送請求給服務端。然而,蛋疼的事情出現了,客戶端竟然一直阻塞在 BufferedReader in = new BufferedReader(new InputStreamReader((InputStream) conn.getInputStream(), "UTF-8")); 處。這說明根本就不是 nginx 的問題啊!
我冷靜下來,review 了一下代碼同時 search 了相關資料,發現了一個小小的區別,在我的返回代碼中,對 ChannelFuture 少了對 CLOSE 事件的監聽器:
ctx.writeAndFlush(response).addListener(ChannelFutureListener.CLOSE);
於是,我加上 Listener 再試一下,馬上就得到響應了!
就在這一刻明白了這是 HTTP 長連接的問題。首先從上面的 nginx 配置中可以看到,我顯式指定了 nginx 和 HTTP 服務器是用的 HTTP1.1 版本,HTTP1.1 版本默認是長連接方式(也就是 Connection=Keep-Alive),而我在 netty HTTP 服務器中並沒有對長、短連接方式做區別處理,並且在 HttpResponse 響應中並沒有顯式加上 Content-Length 頭部信息,恰巧 netty Http 協議棧並沒有在框架上做這件工作,導致服務端雖然把響應消息發出去了,但是客戶端並不知道你是否發送完成了(即沒辦法判斷數據是否已經發送完)。
於是,把響應的處理完善一下即可:
/**
* 響應報文處理
* @param channel 當前上下文Channel
* @param status 響應碼
* @param msg 響應消息
* @param forceClose 是否強制關閉
*/
private void writeResponse(Channel channel, HttpResponseStatus status, String msg, boolean forceClose){
ByteBuf byteBuf = Unpooled.wrappedBuffer(msg.getBytes());
response = new DefaultFullHttpResponse(HttpVersion.HTTP_1_1, status, byteBuf);
boolean close = isClose();
if(!close && !forceClose){
response.headers().add(org.apache.http.HttpHeaders.CONTENT_LENGTH, String.valueOf(byteBuf.readableBytes()));
}
ChannelFuture future = channel.write(response);
if(close || forceClose){
future.addListener(ChannelFutureListener.CLOSE);
}
}
private boolean isClose(){
if(request.headers().contains(org.apache.http.HttpHeaders.CONNECTION, CONNECTION_CLOSE, true) ||
(request.protocolVersion().equals(HttpVersion.HTTP_1_0) &&
!request.headers().contains(org.apache.http.HttpHeaders.CONNECTION, CONNECTION_KEEP_ALIVE, true)))
return true;
return false;
}
好了,問題是解決了,那麼你對 HTTP 長連接真的了解嗎?不了解,好,那就來不補課。
5.2.1. TCP KeepAlive 和 HTTP KeepAlive【4】
netty 中有個地方比較讓初學者迷惑,就是 childOption(ChannelOption.SO_KEEPALIVE, true) 和 HttpRequest.Headers.get("Connection").equals("Keep-Alive") (非標准寫法,僅作示例)的異同。有些人可能會問,我在 ServerBootstrap 中指定了 childOption(ChannelOption.SO_KEEPALIVE, true),是不是就意味著客戶端和服務器是長連接了?
答案當然不是。
首先,TCP 的 KeepAlive 是 TCP 連接的探測機制,用來檢測當前 TCP 連接是否活著。它支持三個系統內核參數
當網絡兩端建立了 TCP 連接之後,閒置 idle(雙方沒有任何數據流發送往來)了 tcp_keepalive_time 後,服務器內核就會嘗試向客戶端發送偵測包,來判斷 TCP 連接狀況(有可能客戶端崩潰、強制關閉了應用、主機不可達等等)。如果沒有收到對方的回答( ACK 包),則會在 tcp_keepalive_intvl 後再次嘗試發送偵測包,直到收到對對方的 ACK,如果一直沒有收到對方的 ACK,一共會嘗試 tcp_keepalive_probes 次,每次的間隔時間在這裡分別是 15s、30s、45s、60s、75s。如果嘗試 tcp_keepalive_probes,依然沒有收到對方的 ACK 包,則會丟棄該 TCP 連接。TCP 連接默認閒置時間是2小時。
而對於 HTTP 的 KeepAlive,則是讓 TCP 連接活長一點,在一次 TCP 連接中可以持續發送多份數據而不會斷開連接。通過使用 keep-alive 機制,可以減少 TCP 連接建立次數,也意味著可以減少 TIME_WAIT 狀態連接,以此提高性能和提高 TTTP 服務器的吞吐率(更少的 TCP 連接意味著更少的系統內核調用,socket 的 accept() 和 close() 調用)。
5.2.2. 長連接方式中如何判斷數據發送完成【6】
回到本節最開始提出的問題,KeepAlive 模式下,HTTP 服務器在發送完數據後並不會主動斷開連接,那客戶端如何判斷數據發送完成了?
對於短連接方式,服務端在發送完數據後會斷開連接,客戶端過服務器關閉連接能確定消息的傳輸長度。(請求端不能通過關閉連接來指明請求消息體的結束,因為這樣讓服務器沒有機會繼續給予響應)。
但對於長連接方式,服務端只有在 Keep-alive timeout 或者達到 max 請求次數時才會斷開連接。這種情況下有兩種判斷方法。
使用消息頭部 Content-Length
Conent-Length 表示實體內容長度,客戶端(或服務器)可以根據這個值來判斷數據是否接收完成。但是如果消息中沒有 Conent-Length,那該如何來判斷呢?又在什麼情況下會沒有 Conent-Length 呢?
使用消息首部字段 Transfer-Encoding
當請求或響應的內容是動態的,客戶端或服務器無法預先知道要傳輸的數據大小時,就要使用 Transfer-Encoding(即 chunked 編碼傳輸)。chunked 編碼將數據分成一塊一塊的發送。chunked 編碼將使用若干個chunk 串連而成,由一個標明長度為 0 的 chunk 標示結束。每個 chunk 分為頭部和正文兩部分,頭部內容指定正文的字符總數(十六進制的數字)和數量單位(一般不寫),正文部分就是指定長度的實際內容,兩部分之間用回車換行(CRLF)隔開。在最後一個長度為 0 的 chunk 中的內容是稱為footer的內容,是一些附加的Header信息(通常可以直接忽略)。
如果一個請求包含一個消息主體並且沒有給出 Content-Length,那麼服務器如果不能判斷消息長度的話應該以400響應(Bad Request),或者以411響應(Length Required)如果它堅持想要收到一個有效的 Content-length。所有的能接收實體的 HTTP/1.1 應用程序必須能接受 chunked 的傳輸編碼,因此當消息的長度不能被提前確定時,可以利用這種機制來處理消息。消息不能同時都包括 Content-Length 頭域和 非identity (Transfer-Encoding)傳輸編碼。如果消息包括了一個 非identity 的傳輸編碼,Content-Length頭域必須被忽略。當 Content-Length 頭域出現在一個具有消息主體(message-body)的消息裡,它的域值必須精確匹配消息主體裡字節數量。
好了,本章較長,雖然不是很深奧難懂的知識,也不是很牛逼的技術實現,但是耐心看完之後相信你終究是有所收獲的。在此本文就要完結了,後續會對 netty HTTP 協議棧做更深入的研究,至於這個 github 上的項目,後面也會繼續完善 TODO LIST。大家可以通過多種方式與我交流,並歡迎大家提出寶貴意見。
參考文章:
【1】《Mina、Netty、Twisted一起學(八):HTTP服務器》
【2】《【Netty官方文檔翻譯】引用計數對象(reference counted objects)》
【3】《Netty之有效規避內存洩漏》
【4】《詳解http_keepalive》
【5】《HTTP Keep-Alive模式》
【6】《HTTP的長連接和短連接》