關於String字符串,對於Java開發者而言,這無疑是一個非常熟悉的類。也正是因為經常使用,其內部代碼的設計才值得被深究。所謂知其然,更得知其所以然。
舉個例子,假如想要寫個類去繼承String,這時IDE提示String為final類型不允許被繼承。
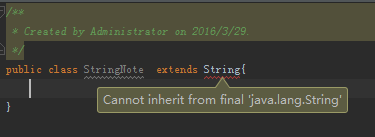
此時最先想到的肯定是java中類被final修飾的效果,其實由這一點也可以引出更多思考:
比如說String類被設計成final類型是出於哪些考慮?
在Java中,被final類型修飾的類不允許被其他類繼承,被final修飾的變量賦值後不允許被修改
查看String類在jdk7源碼中的定義:
publicfinalclassStringimplementsjava.io.Serializable,Comparable,CharSequence{...}
可以看出String是final類型的,表示該類不能被其他類繼承,同時該類實現了三個接口:java.io.Serializable Comparable CharSequence
對於Sting類,官方有如下注釋說明:
/*Stringsareconstant;theirvaluescannotbechangedafterthey
arecreated.Stringbufferssupportmutablestrings.
BecauseStringobjectsareimmutabletheycanbeshared.Forexample:*/
String字符串是常量,其值在實例創建後就不能被修改,但字符串緩沖區支持可變的字符串,因為緩沖區裡面的不可變字符串對象們可以被共享。(其實就是使對象的引用發生了改變)
/**Thevalueisusedforcharacterstorage.*/
privatefinalcharvalue[];
這是一個字符數組,並且是final類型,用於存儲字符串內容。從fianl關鍵字可以看出,String的內容一旦被初始化後,其不能被修改的。
看到這裡也許會有人疑惑,String初始化以後好像可以被修改啊。比如找一個常見的例子:
String str = “hello”; str = “hi”
其實這裡的賦值並不是對str內容的修改,而是將str指向了新的字符串另外可以明確的一點:String其實是基於字符數組char[]實現的。
/**Cachethehashcodeforthestring*/
privateinthash;//Defaultto0
緩存字符串的hash Code,其默認值為 0
/**useserialVersionUIDfromJDK1.0.2forinteroperability*/
privatestaticfinallongserialVersionUID=-6849794470754667710L;
/**ClassStringisspecialcasedwithintheSerializationStreamProtocol.*/
privatestaticfinalObjectStreamField[]serialPersistentFields= newObjectStreamField[0]
因為String實現了Serializable接口,所以支持序列化和反序列化支持。Java的序列化機制是通過在運行時判斷類的serialVersionUID來驗證版本一致性的。在進行反序列化時,JVM會把傳來的字節流中的serialVersionUID與本地相應實體(類)的serialVersionUID進行比較,如果相同就認為是一致的,可以進行反序列化,否則就會出現序列化版本不一致的異常(InvalidCastException)。
空的構造器
this.value="".value;
}```
該構造方法會創建空的字符序列,注意這個構造方法的使用,因為創造不必要的字符串對象是不可變的。因此不建議采取下面的創建String對象:
String str = new String()
str = "sample";
>這樣的結果顯而易見,會產生了不必要的對象。
**使用字符串類型的對象來初始化**
publicString(Stringoriginal){
this.value=original.value;
this.hash=original.hash;
}
這裡將直接將源String中的value和hash兩個屬性直接賦值給目標String。因為String一旦定義之後是不可以改變的,所以也就不用擔心改變源String的值會影響到目標String的值。
**使用字符數組來構造**
publicString(charvalue[]){
this.value=Arrays.copyOf(value,value.length);
}
```
publicString(charvalue[],intoffset,intcount){
if(offset<0){
thrownewStringIndexOutOfBoundsException(offset);
}
if(count<=0){
if(count<0){
thrownewStringIndexOutOfBoundsException(count);
}
if(offset<=value.length){
this.value="".value;
return;
}
}
//Note:offsetorcountmightbenear-1>>>1.
if(offset>value.length-count){
thrownewStringIndexOutOfBoundsException(offset+count);
}
this.value=Arrays.copyOfRange(value,offset,offset+count);
}
````
這裡值得注意的是:當我們使用字符數組創建String的時候,會用到Arrays.copyOf方法或Arrays.copyOfRange方法。這兩個方法是將原有的字符數組中的內容逐一的復制到String中的字符數組中。會創建一個新的字符串對象,隨後修改的字符數組不影響新創建的字符串。
**使用字節數組來構建String**
在Java中,String實例中保存有一個char[]字符數組,char[]字符數組是以unicode碼來存儲的,String 和 char 為內存形式。
byte是網絡傳輸或存儲的序列化形式,所以在很多傳輸和存儲的過程中需要將byte[]數組和String進行相互轉化。所以,String提供了一系列重載的構造方法來將一個字符數組轉化成String,提到byte[]和String之間的相互轉換就不得不關注編碼問題。
String(byte[] bytes, Charset charset)“`
該構造方法是指通過charset來解碼指定的byte數組,將其解碼成unicode的char[]數組,夠造成新的String。
這裡的bytes字節流是使用charset進行編碼的,想要將他轉換成unicode的char[]數組,而又保證不出現亂碼,那就要指定其解碼方式**
同樣使用字節數組來構造String也有很多種形式,按照是否指定解碼方式分的話可以分為兩種:
publicString(bytebytes[]){
this(bytes,0,bytes.length);
}
publicString(bytebytes[],intoffset,intlength){
checkBounds(bytes,offset,length);
this.value=StringCoding.decode(bytes,offset,length);
}
如果我們在使用byte[]構造String的時候,使用的是下面這四種構造方法(帶有charsetName或者charset參數)的一種的話,那麼就會使用StringCoding.decode方法進行解碼,使用的解碼的字符集就是我們指定的charsetName或者charset。
String(byte bytes[]) String(byte bytes[], int offset, int length)
String(byte bytes[], Charset charset)
String(byte bytes[], String charsetName)
String(byte bytes[], int offset, int length, Charset charset)
String(byte bytes[], int offset, int length, String charsetName)
們在使用byte[]構造String的時候,如果沒有指明解碼使用的字符集的話,那麼StringCoding的decode方法首先調用系統的默認編碼格式,如果沒有指定編碼格式則默認使用ISO-8859-1編碼格式進行編碼操作。主要體現代碼如下:
staticchar[]decode(byte[]ba,intoff,intlen){
Stringcsn=Charset.defaultCharset().name();
try{ //usecharsetnamedecode()variantwhichprovidescaching.
returndecode(csn,ba,off,len);
}catch(UnsupportedEncodingExceptionx){
warnUnsupportedCharset(csn);
}
try{
returndecode("ISO-8859-1",ba,off,len); }catch(UnsupportedEncodingExceptionx){
//IfthiscodeishitduringVMinitialization,MessageUtilsis
//theonlywaywewillbeabletogetanykindoferrormessage.
MessageUtils.err("ISO-8859-1charsetnotavailable:"+x.toString());
//IfwecannotfindISO-8859-1(arequiredencoding)thenthings
//areseriouslywrongwiththeinstallation.
System.exit(1);
returnnull;
}
}
使用StringBuffer和StringBuider構造一個String
作為String的兩個“兄弟”,StringBuffer和StringBuider也可以被當做構造String的參數。
“`
public String(StringBuffer buffer) {
synchronized(buffer) {
this.value = Arrays.copyOf(buffer.getValue(), buffer.length());
}
}
public String(StringBuilder builder) {
this.value = Arrays.copyOf(builder.getValue(), builder.length());
}
當然,這兩個構造方法是很少用到的,因為當我們有了StringBuffer或者StringBuilfer對象之後可以直接使用他們的toString方法來得到String。
>關於效率問題,Java的官方文檔有提到說使用StringBuilder的toString方法會更快一些,原因是StringBuffer的toString方法是synchronized的,在犧牲了效率的情況下保證了線程安全。
StringBuilder的toString()方法:
@Override
publicStringtoString(){
//Createacopy,don’tsharethearray
returnnewString(value,0,count);
}
StringBuffer的toString()方法:
@Override
publicsynchronizedStringtoString(){
if(toStringCache==null){
toStringCache=Arrays.copyOfRange(value,0,count);
}
returnnewString(toStringCache,true);
}
**一個特殊的保護類型的構造方法**
String除了提供了很多公有的供程序員使用的構造方法以外,還提供了一個保護類型的構造方法(Java 7),我們看一下他是怎麼樣的:
String(char[] value, boolean share) {
// assert share : “unshared not supported”;
this.value = value;
}
從代碼中我們可以看出,該方法和String(char[] value)有兩點區別:
* 第一個,該方法多了一個參數:boolean share,其實這個參數在方法體中根本沒被使用。注釋說目前不支持false,只使用true。
>那可以斷定,加入這個share的只是為了區分於String(char[] value)方法,不加這個參數就沒辦法定義這個函數,只有參數是不能才能進行重載。
* 第二個區別就是具體的方法實現不同。我們前面提到過,String(char[] value)方法在創建String的時候會用到Arrays的copyOf方法將value中的內容逐一復制到String當中,而這個String(char[] value, boolean share)方法則是直接將value的引用賦值給String的value。
>那麼也就是說,這個方法構造出來的String和參數傳過來的char[] value共享同一個數組。
**為什麼Java會提供這樣一個方法呢? **
* **性能好**
>這個很簡單,一個是直接給數組賦值(相當於直接將String的value的指針指向char[]數組),一個是逐一拷貝。當然是直接賦值快了。
* **節約內存**
>該方法之所以設置為protected,是因為一旦該方法設置為公有,在外面可以訪問的話,如果構造方法沒有對arr進行拷貝,那麼其他人就可以在字符串外部修改該數組,由於它們引用的是同一個數組,因此對arr的修改就相當於修改了字符串,那就破壞了字符串的不可變性。
* **安全的**
>對於調用他的方法來說,由於無論是原字符串還是新字符串,其value數組本身都是String對象的私有屬性,從外部是無法訪問的,因此對兩個字符串來說都很安全。
###Java7加入的新特性
在Java 7 之前有很多String裡面的方法都使用上面說的那種“性能好的、節約內存的、安全”的構造函數。
比如:`substring` `replace` `concat` `valueOf`等方法
>實際上他們使用的是public String(char[], ture)方法來實現。
**但是在Java 7中,substring已經不再使用這種“優秀”的方法了**
publicStringsubstring(intbeginIndex,intendIndex){
if(beginIndex<0){
thrownewStringIndexOutOfBoundsException(beginIndex);
}
if(endIndex>value.length){
thrownewStringIndexOutOfBoundsException(endIndex);
}
intsubLen=endIndex-beginIndex;
if(subLen<0){
thrownewStringIndexOutOfBoundsException(subLen);
}
return((beginIndex==0)&&(endIndex==value.length))?this :newString(value,beginIndex,subLen);
}
**為什麼呢?**
雖然這種方法有很多優點,但是他有一個致命的缺點,對於sun公司的程序員來說是一個零容忍的bug,那就是他很有可能造成**內存洩露**。
看一個例子,假設一個方法從某個地方(文件、數據庫或網絡)取得了一個很長的字符串,然後對其進行解析並提取其中的一小段內容,這種情況經常發生在網頁抓取或進行日志分析的時候。
下面是示例代碼。
StringaLongString=”…averylongstring…”;
StringaPart=data.substring(20,40);
returnaPart;
在這裡aLongString只是臨時的,真正有用的是aPart,其長度只有20個字符,但是它的內部數組卻是從aLongString那裡共享的,因此雖然aLongString本身可以被回收,但它的內部數組卻不能釋放。
這就導致了內存洩漏。如果一個程序中這種情況經常發生有可能會導致嚴重的後果,如內存溢出,或性能下降。
>新的實現雖然損失了性能,而且浪費了一些存儲空間,但卻保證了字符串的內部數組可以和字符串對象一起被回收,從而防止發生內存洩漏,因此新的substring比原來的更健壯。
###其他方法
length() 返回字符串長度
publicintlength(){
returnvalue.length;
}
isEmpty() 返回字符串是否為空
publicbooleanisEmpty(){
returnvalue.length==0;
}
charAt(int index) 返回字符串中第(index+1)個字符(數組索引)
publiccharcharAt(intindex){
if((index<0)||(index>=value.length)){
thrownewStringIndexOutOfBoundsException(index);
}
returnvalue[index];
}
char[] toCharArray()轉化成字符數組
trim()去掉兩端空格
toUpperCase()轉化為大寫
toLowerCase()轉化為小寫
**需要注意**
String concat(String str) //拼接字符串
String replace(char oldChar, char newChar) //將字符串中的oldChar字符換成newChar字符
>以上兩個方法都使用了String(char[] value, boolean share);concat方法和replace方法,他們不會導致元數組中有大量空間不被使用,因為他們一個是拼接字符串,一個是替換字符串內容,不會將字符數組的長度變得很短,所以使用了共享的char[]字符數組來優化。
boolean matches(String regex) //判斷字符串是否匹配給定的regex正則表達式
boolean contains(CharSequence s) //判斷字符串是否包含字符序列s
String[] split(String regex, int limit) 按照字符regex將字符串分成limit份
String[] split(String regex) 按照字符regex將字符串分段
**getBytes**
在創建String的時候,可以使用byte[]數組,將一個字節數組轉換成字符串,同樣,我們可以將一個字符串轉換成字節數組,那麼String提供了很多重載的getBytes方法。
publicbyte[]getBytes(){
returnStringCoding.encode(value,0,value.length);
}
但是,值得注意的是,在使用這些方法的時候一定要注意編碼問題。比如:
`String s = "你好,世界!"; byte[] bytes = s.getBytes();`
這段代碼在不同的平台上運行得到結果是不一樣的。由於沒有指定編碼方式,所以在該方法對字符串進行編碼的時候就會使用系統的默認編碼方式。
>在中文操作系統中可能會使用GBK或者GB2312進行編碼,在英文操作系統中有可能使用iso-8859-1進行編碼。這樣寫出來的代碼就和機器環境有很強的關聯性了,為了避免不必要的麻煩,要指定編碼方式。
publicbyte[]getBytes(StringcharsetName) throwsUnsupportedEncodingException{
if(charsetName==null)thrownewNullPointerException();
returnStringCoding.encode(charsetName,value,0,value.length);
}
###比較方法
booleanequals(ObjectanObject);
booleancontentEquals(StringBuffersb);
booleancontentEquals(CharSequencecs);
booleanequalsIgnoreCase(StringanotherString);
intcompareTo(StringanotherString);
intcompareToIgnoreCase(Stringstr);
booleanregionMatches(inttoffset,Stringother,intooffset,intlen) //局部匹配
booleanregionMatches(booleanignoreCase,inttoffset,Stringother,intooffset,intlen) //局部匹配
字符串有一系列方法用於比較兩個字符串的關系。 前四個返回boolean的方法很容易理解,前三個比較就是比較String和要比較的目標對象的字符數組的內容,一樣就返回true,不一樣就返回false,核心代碼如下:
```
int n = value.length;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
v1 v2分別代表String的字符數組和目標對象的字符數組。 第四個和前三個唯一的區別就是他會將兩個字符數組的內容都使用toUpperCase方法轉換成大寫再進行比較,以此來忽略大小寫進行比較。相同則返回true,不想同則返回false
equals方法:
public boolean equals(Object anObject) {
if (this == anObject) {
return true;
}
if (anObject instanceof String) {
String anotherString = (String) anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}
該方法首先判斷this == anObject ?,也就是說判斷要比較的對象和當前對象是不是同一個對象,如果是直接返回true,如不是再繼續比較,然後在判斷anObject是不是String
類型的,如果不是,直接返回false,如果是再繼續比較,到了能終於比較字符數組的時候,他還是先比較了兩個數組的長度,不一樣直接返回false,一樣再逐一比較值。 雖然代碼寫的內容比較多,但是可以很大程度上提高比較的效率。值得學習!!!
contentEquals有兩個重載:
StringBuffer需要考慮線程安全問題,加鎖之後再調用contentEquals((CharSequence) sb)方法。
contentEquals((CharSequence) sb)則分兩種情況,一種是cs instanceof AbstractStringBuilder,另外一種是參數是String類型。具體比較方式幾乎和equals方法類似,先做“宏觀”比較,在做“微觀”比較。
下面這個是equalsIgnoreCase代碼的實現:
public boolean equalsIgnoreCase(String anotherString) {
return (this == anotherString) ? true : (anotherString != null) && (anotherString.value.length == value.length) && regionMatches(true, 0, anotherString, 0, value.length);
}
看到這段代碼,眼前為之一亮。使用一個三目運算符和&&操作代替了多個if語句。
publicinthashCode(){
inth=hash;
if(h==0&&value.length>0){
charval[]=value;
for(inti=0;i
hashCode的實現其實就是使用數學公式:s[0]*31^(n-1) + s[1]*31^(n-2) + … + s[n-1]
所謂“沖突”,就是在存儲數據計算hash地址的時候,我們希望盡量減少有同樣的hash地址。如果使用相同hash地址的數據過多,那麼這些數據所組成的hash鏈就更長,從而降低了查詢效率。
所以在選擇系數的時候要選擇盡量長的系數並且讓乘法盡量不要溢出的系數,因為如果計算出來的hash地址越大,所謂的“沖突”就越少,查找起來效率也會提高。
現在很多虛擬機裡面都有做相關優化,使用31的原因可能是為了更好的分配hash地址,並且31只占用5bits。
在Java中,整型數是32位的,也就是說最多有2^32= 4294967296個整數,將任意一個字符串,經過hashCode計算之後,得到的整數應該在這4294967296數之中。那麼,最多有 4294967297個不同的字符串作hashCode之後,肯定有兩個結果是一樣的。
hashCode可以保證相同的字符串的hash值肯定相同,但是hash值相同並不一定是value值就相同。
substring
前面我們介紹過,java 7 中的substring方法使用String(value, beginIndex, subLen)方法創建一個新的String並返回,這個方法會將原來的char[]中的值逐一復制到新的String中,兩個數組並不是共享的,雖然這樣做損失一些性能,但是有效地避免了內存洩露。
replaceFirst、replaceAll、replace區別
StringreplaceFirst(Stringregex,Stringreplacement)
StringreplaceAll(Stringregex,Stringreplacement)
Stringreplace(CharSequencetarget,CharSequencereplacement)
publicStringreplace(charoldChar,charnewChar){
if(oldChar!=newChar){
intlen=value.length;
inti=-1;
char[]val=value;/*avoidgetfieldopcode*/
while(++i
replace的參數是char和CharSequence,即可以支持字符的替換,也支持字符串的替換 replaceAll和replaceFirst的參數是regex,即基於規則表達式的替換
比如可以通過replaceAll(“\d”, “*”)把一個字符串所有的數字字符都換成星號;
相同點是都是全部替換,即把源字符串中的某一字符或字符串全部換成指定的字符或字符串,如果只想替換第一次出現的,可以使用 replaceFirst(),這個方法也是基於規則表達式的替換。另外,如果replaceAll()和replaceFirst()所用的參數據不是基於規則表達式的,則與replace()替換字符串的效果是一樣的,即這兩者也支持字符串的操作。
copyValueOf 和 valueOf
String的底層是由char[]實現的,早期的String構造器的實現呢,不會拷貝數組的,直接將參數的char[]數組作為String的value屬性。字符數組將導致字符串的變化。
為了避免這個問題,提供了copyValueOf方法,每次都拷貝成新的字符數組來構造新的String對象。
現在的String對象,在構造器中就通過拷貝新數組實現了,所以這兩個方面在本質上已經沒區別了。
valueOf()有很多種形式的重載,包括:
public static String valueOf(boolean b) {
return b ? "true" : "false";
}
public static String valueOf(char c) {
char data[] = {c};
return new String(data, true);
}
public static String valueOf(int i) {
return Integer.toString(i);
}
public static String valueOf(long l) {
return Long.toString(l);
}
public static String valueOf(float f) {
return Float.toString(f);
}
public static String valueOf(double d) {
return Double.toString(d);
}
可以看到這些方法可以將六種基本數據類型的變量轉換成String類型。
intern()方法
public native String intern(); 該方法返回一個字符串對象的內部化引用。
String類維護一個初始為空的字符串的對象池,當intern方法被調用時,如果對象池中已經包含這一個相等的字符串對象則返回對象池中的實例,否則添加字符串到對象池並返回該字符串的引用。
String對“+”的重載
我們知道,Java是不支持重載運算符,String的“+”是java中唯一的一個重載運算符,那麼java使如何實現這個加號的呢?我們先看一段代碼:
public static void main(String[] args) {
String string="hollis";
String string2 = string + "chuang";
}
然後我們將這段代碼的實際執行情況:
public static void main(String args[]){
String string = "hollis";
String string2 = (new
StringBuilder(String.valueOf(string))).append("chuang").toString();
}
看了反編譯之後的代碼我們發現,其實String對“+”的支持其實就是使用了StringBuilder以及他的append、toString兩個方法。
String.valueOf和Integer.toString的區別
接下來我們看以下這段代碼,我們有三種方式將一個int類型的變量變成呢過String類型,那麼他們有什麼區別?
int i = 5;
String i1 = "" + i;
String i2 = String.valueOf(i);
String i3 = Integer.toString(i);
第三行和第四行沒有任何區別,因為String.valueOf(i)也是調用Integer.toString(i)來實現的。
第二行代碼其實是String i1 = (new StringBuilder()).append(i).toString();
首先創建了一個StringBuilder對象,然後再調用append方法,再調用toString方法。
switch對字符串支持的實現
還是先上代碼:
public class switchDemoString {
public static void main(String[] args) {
String str = "world";
switch (str) {
case "hello":
System.out.println("hello");
break;
case "world":
System.out.println("world");
break;
default: break;
}
}
}
對編譯後的代碼進行反編譯:
public static void main(String args[]) {
String str = "world";
String s;
switch((s = str).hashCode()) {
case 99162322:
if(s.equals("hello"))
System.out.println("hello");
break;
case 113318802:
if(s.equals("world"))
System.out.println("world");
break;
default: break;
}
}
看到這個代碼,你知道原來字符串的switch是通過equals()和hashCode()方法來實現的。記住,switch中只能使用整型,比如byte,short,char(ackii碼是整型)以及int。
還好hashCode()方法返回的是int而不是long。
通過這個很容易記住hashCode返回的是int這個事實。仔細看下可以發現,進行switch的實際是哈希值,然後通過使用equals方法比較進行安全檢查,這個檢查是必要的,因為哈希可能會發生碰撞。
因此性能是不如使用枚舉進行switch或者使用純整數常量,但這也不是很差。因為Java編譯器只增加了一個equals方法,如果你比較的是字符串字面量的話會非常快,比如”abc” ==”abc”。如果你把hashCode()方法的調用也考慮進來了,那麼還會再多一次的調用開銷,因為字符串一旦創建了,它就會把哈希值緩存起來。
因此如果這個siwtch語句是用在一個循環裡的,比如逐項處理某個值,或者游戲引擎循環地渲染屏幕,這裡hashCode()方法的調用開銷其實不會很大。
其實swich只支持一種數據類型,那就是整型,其他數據類型都是轉換成整型之後在使用switch的。
總結
一旦string對象在內存(堆)中被創建出來,就無法被修改。
特別要注意的是,String類的所有方法都沒有改變字符串本身的值,都是返回了一個新的對象。
如果你需要一個可修改的字符串,應該使用StringBuffer 或者 StringBuilder。
否則會有大量時間浪費在垃圾回收上,因為每次試圖修改都有新的string對象被創建出來。 如果你只需要創建一個字符串,你可以使用雙引號的方式,如果你需要在堆中創建一個新的對象,你可以選擇構造函數的方式。