Java中常見的排序算法
這是我摘取的一段英文資料,我覺得學習算法之前,對各種排序得有個大致的了解:
Sorting algorithms are an important part of managing data. At Cprogramming.com, we offer tutorials for understanding the most important andcommon sorting techniques. Each algorithm has particular strengths and weaknesses and in many cases the best thing to do is just use the built-in sorting function qsort. For times when this isn't an option or you just need a quick and dirty sorting algorithm, there are a variety of choices.
Most sorting algorithms work by comparing the data being sorted. In some cases, it may be desirable to sort a large chunk of data (for instance, a struct containing a name and address) based on only a portion of that data. The piece of data actually used to determine the sorted order is called the key.
Sorting algorithms are usually judged by their efficiency. In this case, efficiency refers to the algorithmic efficiency as the size of the input grows large and is generally based on the number of elements to sort. Most of the algorithms in use have an algorithmic efficiency of either O(n^2) or O(n*log(n)). A few special case algorithms (one example is mentioned inProgramming Pearls) can sort certain data sets faster than O(n*log(n)). These algorithms are not based on comparing the items being sorted and rely on tricks. It has been shown that no key-comparison algorithm can perform better than O(n*log(n)).
Many algorithms that have the same efficiency do not have the same speed on the same input. First, algorithms must be judged based on their average case, best case, and worst case efficiency. Some algorithms, such as quick sort, perform exceptionally well for some inputs, but horribly for others. Other algorithms, such as merge sort, are unaffected by the order of input data. Even a modified version of bubble sort can finish in O(n) for the most favorable inputs.
A second factor is the "constant term". As big-O notation abstracts away many of the details of a process, it is quite useful for looking at the big picture. But one thing that gets dropped out is the constant in front of the expression: for instance, O(c*n) is just O(n). In the real world, the constant, c, will vary across different algorithms. A well-implemented quicksort should have a much smaller constant multiplier than heap sort.
A second criterion for judging algorithms is their space requirement -- do they require scratch space or can the array be sorted in place (without additional memory beyond a few variables)? Some algorithms never require extra space, whereas some are most easily understood when implemented with extra space (heap sort, for instance, can be done in place, but conceptually it is much easier to think of a separate heap). Space requirements may even depend on the data structure used (merge sort on arrays versus merge sort on linked lists, for instance).
A third criterion is stability -- does the sort preserve the order of keys with equal values? Most simple sorts do just this, but some sorts, such as heap sort, do not.
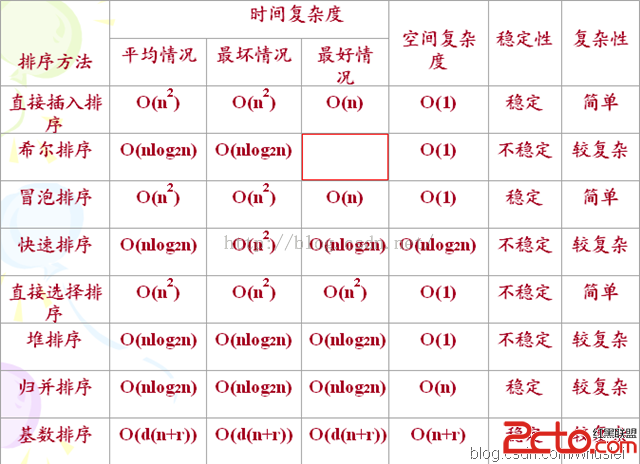
The following chart compares sorting algorithms on the various criteria outlined above; the algorithms with higher constant terms appear first, though this is clearly an implementation-dependent concept and should only be taken as a rough guide when picking between sorts of the same big-O efficiency.
Time |
Sort
Average
Best
Worst
Space
Stability
Remarks
Bubble sort
O(n^2)
O(n^2)
O(n^2)
Constant
Stable
Always use a modified bubble sort
Modified Bubble sort
O(n^2)
O(n)
O(n^2)
Constant
Stable
Stops after reaching a sorted array
Selection Sort
O(n^2)
O(n^2)
O(n^2)
Constant
Stable
Even a perfectly sorted input requires scanning the entire array
Insertion Sort
O(n^2)
O(n)
O(n^2)
Constant
Stable
In the best case (already sorted), every insert requires constant time
Heap Sort
O(n*log(n))
O(n*log(n))
O(n*log(n))
Constant
Instable
By using input array as storage for the heap, it is possible to achieve constant space
Merge Sort
O(n*log(n))
O(n*log(n))
O(n*log(n))
Depends
Stable
On arrays, merge sort requires O(n) space; on linked lists, merge sort requires constant space
Quicksort
O(n*log(n))
O(n*log(n))
O(n^2)
Constant
Stable
Randomly picking a pivot value (or shuffling the array prior to sorting) can help avoid worst case scenarios such as a perfectly sorted array.
QuickSort(快速):
@快速排序的思路是(以首元素為基准)將數組切分成兩塊,左邊的元素都小於基准元素(A區域),右邊的元素都大於基准元素(H區域),此時基准元素的位置已經確定了(仔細想想),請查看
思路一部分;
這時我們得用遞歸的思想繼續後面的排序:
@既然基准元素的位置已經確定,那麼我們用來比較的元素的兩個游標i,j就要[i--,j++](因為基准元素的位置是當 i = j才確定的,如有不懂請看一下後面的代碼部分);
@現在開始排列第一次分離出來比基准元素大的部分(H區域),(將這一部分看做一個新的數組,那麼頭元素的下標就是j++);只有當
(H區域)的元素都排列好了之後,才會去排列(A區域),【遞歸的思想------想一下】
思路一:
這是數組中的最初順序:
(i = 0, j = 8)
66
55
88
11
44
22
99
33
77
選擇頭元素66(下標i = 0)作為比較的基准,與尾元素77(下標j = 8)作比較:
@如果比77大就互換位置,i++;(下一次與55(下標i = 1)作比較了);@否則不換位置(j--【注意咯】),那麼下一次與33(下標j= 7)作比較了,就是我們這種情況);【記住啦:產生交換就j--;否則i++】
(i = 0, j = 7)
33
55
88
11
44
22
99
66
77
(i = 1, j = 7)
33
55
88
11
44
22
99
66
77
(i = 2, j = 7)
33
55
66
11
44
22
99
88
77
(i = 2, j = 6)
33
55
66
11
44
22
99
88
77
(i = 3, j = 5)
33
55
22
11
44
66
99
88
77
(i = 4, j = 5)
33
55
22
11
44
66
99
88
77
(i = 4, j = 4)
33
55
22
11
44
66
99
88
77
@以數組的頭元素作為基准,當第一輪比較完之後如1所示:
@大於66的元素在右邊,小於66的元素在左邊【驗證了前面的----66位置已確定!後面再也沒有改動過了吧】
66 55 88 11 44 22 99 33 77 最初位置
33 55 22 11 44 66 99 88 77 1
33 55 22 11 44 66 77 88 99 2
33 55 22 11 44 66 77 88 99 3
11 22 33 55 44 66 77 88 99 4
11 22 33 44 55 66 77 88 99 5
11 22 33 44 55 66 77 88 99 6
// 快速排序
private static void quickSort(int[] array, int start, int end) {
if (start >= end) {
return;
}
int i = start;
int j = end;
boolean isrun = true;
// 思路一的邏輯代碼
while (i != j) {
if (array[i] > array[j]) {
swap(array, i, j);
isrun = (isrun == true) ? false : true;
}
if (isrun) {
j--;
} else {
i++;
}
time++;
}
print(array);
i--;
j++;
quickSort(array, j, end);
quickSort(array, start, i);
}
BinarySearch(二分):
前言:二分法排序的基本思想是 (二分查找的遞歸):【從小到大排序】
@獲取數組array的大小len,定義游標i = 0,其中下標i對應的元素是待插入的目標元素,每一輪過後,下標i前面的元素將會順序排列;
【在每一輪的排序過程中】
@記錄數組中首元素和尾元素的下標left = 0 和 right = i - 1(為什麼要減1,因為i是我們待插入的元素下標),每次采用折中的辦法找到所對應元素的下標mid;
@如果待插入的元素array[i] < array[mid]
@那麼我們可以確定所要插入的區域在左邊,因此左區域的最大范圍right = mid - 1;(>同理)。
@通過不斷的折中,當(left > right)時就能確定插入的位置,【記住:下標i之前的元素都已經排好序的,故只要整體往後挪動一個單位即可】。
66
55
88
11
44
22
66
55
88
11
44
22
55
66
88
11
44
22
55
66
88
11
44
22
11
55
66
88
44
22
11
44
55
66
88
22
11
22
44
55
66
88
// 二分法排序
private static void binaryCheck(int[] array) {
for (int i = 0; i < array.length; i++) {
int key = array[i];
int left = 0;
int right = i - 1;
int mid = 0;
// 每一輪查找的邏輯代碼
while (left <= right) {
mid = (right + left) / 2;
if (key < array[mid]) {
right = mid - 1;
} else {
left = mid + 1;
}
time++;
}
// 區間[left,i-1]整體往後挪動一個單位
for (int j = i - 1; j >= left; j--) {
array[j + 1] = array[j];
}
// 將目標元素插入指定位置
if (left != i) {
array[left] = key;
}
print(test);
}
}
ShellSort(希爾):
請看下面的每一輪過後數組的排序信息:
66 11 99 55 22 77 --------原始序列
55 11 99 66 22 77 1
55 11 99 66 22 77
------------------------------------------------------
55 11 77 66 22 99
11 55 77 66 22 99
11 55 77 66 22 99 2
11 55 66 77 22 99 ----------EXP
11 22 55 66 77 99
11 22 55 66 77 99
有沒有找出一點規律哦~~~(再找找看)
構建代碼:
@1中的數組元素比較是(下標i和i+d) [d = array.length/2];
@2中的數組元素比較是(下標i和i+d) [d = (array.length/2)/2];
@[d = array.length/2];當d<0時,排序結束;
--------------------------------------------------------------------
@當我們比較EXP時會發現元素77(下標i = 3)和22(下標i = 4)後,22的下標(i = 1,而不是 i = 3,這樣的替換),
那麼在這裡我們需要進行邏輯控制,需要遍歷該下標之前的元素;(紅色部分)
while(j>=0&&array[j+d]
temp=array[j];
array[j]=array[j+d];
array[j+d]=temp;
j=j-d;
}
// 希爾排序
private static void shellSort(int[] array, int len) {
int j;
int d = len / 2;
int temp = 0;
while (d > 0) {
for (int i = d; i < len; i++) {
j = i - d;
while (j >= 0 && array[j + d] < array[j]) {
temp = array[j];
array[j] = array[j + d];
array[j + d] = temp;
j = j - d;
time++;
}
print(test);
}
d = d / 2;
}
}
MergeSort(歸並):
數組{33,55,99,11,66,22,77}的歸並過程:
{33,55},{11,99},{22,66},{77} --------3;
{11,33,55,99},{22,66,77}------------4(當22與11比較完後,66就直接從33開始比較至99結束);
{11,22,33,55,66,77,99}--------------5;
總共比較了12 = 3 + 4 + 5次;
// 歸並排序
private static void myMerge(int[] array,int first,int sStart,int sEnd){
int[] temp = new int[sEnd - first + 1];
int i = first,j = sStart,k = 0;
while(i < sStart && j <= sEnd){ //因為每一輪歸並後,產生的數組中元素將會順序排列,若A中的第一個元素大於B中的
//最後一個元素,那麼A中的其他元素無需比較,直接轉移
if(array[i] <= array[j]){
temp[k] = array[i];
i++;
k++;
}else{
temp[k] = array[j];
k++;
j++;
}
}
while(i < sStart){
temp[k] = array[i];
k++;
i++;
}
while(j <= sEnd){
temp[k] = array[j];
k++;
j++;
}
System.arraycopy(temp, 0, array, first, temp.length);
}
private static void mySort(int[] array,int start,int len){
int size = 0; //計算歸並的第一組元素的起始位置
int length = array.length;
int mtime = length/(2*len); //歸並的數組個數
int rest = length & (2*len - 1); //統計歸並的最後一個數組(當數組元素的個數為奇數時,那麼在歸並的過程中最後一個數組元素個數是奇數)
// 如果在歸並過程中數組的個數剛好是偶數那麼rest = 0;
if(mtime == 0){
return;
}
for(int i = 0;i < mtime;i ++){
size = 2*i*len;
myMerge(array, size, size + len, size + 2*len - 1);
}
if(rest != 0){
myMerge(array, length - rest - 2*len, length - rest, length - 1);
}
//下一輪歸並
mySort(array, 0, 2*len);
}