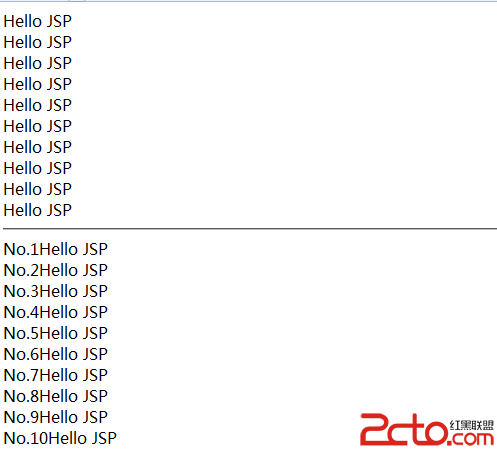
烈火建站學院文檔 在進行網頁編程中我們經常會遇到一些亂碼問題,諸如GET/POST提交的數據在服務器端處理時出現亂碼,浏覽器顯示服務器端響應出現亂碼等,ajax交互過程中出現亂碼,而更糟糕的是每次遇到問題我們都要到網上去搜索一堆的解決方案,但是這些方案大都都捉襟見肘,只能解決部分問題。
分析主要原因,是我們對編碼基本知識,java語言對編碼處理,浏覽器/服務器端在請求響應的過程中對編碼的處理,URL的編碼規則,還有ajax應用編碼規則了解不夠透徹等導致的。
本文將從以上這幾個原因出發,分析亂碼出現的原因和解決方案。
<!--[if !supportLists]-->一、<!--[endif]-->編碼基礎知識
<!--[if !supportLists]-->1.1 <!--[endif]-->字符、字符集和編碼
字符:是文字與符號的總稱,包括文字、圖形符號、數學符號等。
字符集:就是一組抽象字符的集合。字符集常常和一種具體的語言文字對應起來,該文字中的所有字符或者大部分常用字符就構成了該文字的字符集,比如英文字符集。一組有共同特征的字符也可以組成字符集,比如繁體漢字字符集、日文漢字字符集。字符集的子集也是字符集。
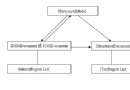
字符和字符集之間的關系可以用下圖表示:
<!--[if !supportLists]-->1.2 <!--[endif]-->常用字符集
ASCII:
American Standard Code for Information Interchange,美國信息交換標准碼。
目前計算機中用得最廣泛的字符集及其編碼,由美國國家標准局(ANSI)制定。它已被國際標准化組織(ISO)定為國際標准,稱為ISO 646標准。 ASCII字符集由控制字符和圖形字符組成。在計算機的存儲單元中,一個ASCII碼值占一個字節(8個二進制位),其最高位(b7)用作奇偶校驗位。所謂奇偶校驗,是指在代碼傳送過程中用來檢驗是否出現錯誤的一種方法,一般分奇校驗和偶校驗兩種。奇校驗規定:正確的代碼一個字節中1的個數必須是奇數,若非奇數,則在最高位b7添1。偶校驗規定:正確的代碼一個字節中1的個數必須是偶數,若非偶數,則在最高位b7添1。
ISO 8859-1:
ISO 8859,全稱ISO/IEC 8859,是國際標准化組織(ISO)及國際電工委員會(IEC)聯合制定的一系列8位字符集的標准,現時定義了15個字符集。
ASCII收錄了空格及94個“可印刷字符”,足以給英語使用。但是,其他使用拉丁字母的語言(主要是歐洲國家的語言),都有一定數量的變音字母,故可以使用ASCII及控制字符以外的區域來儲存及表示。除了使用拉丁字母的語言外,使用西裡爾字母的東歐語言、希臘語、泰語、現代阿拉伯語、希伯來語等,都可以使用這個形式來儲存及表示。
* ISO 8859-1 (Latin-1) - 西歐語言
* ISO 8859-2 (Latin-2) - 中歐語言
* ISO 8859-3 (Latin-3) - 南歐語言。世界語也可用此字符集顯示。
* ISO 8859-4 (Latin-4) - 北歐語言
* ISO 8859-5 (Cyrillic) - 斯拉夫語言
* ISO 8859-6 (Arabic) - 阿拉伯語
* ISO 8859-7 (Greek) - 希臘語
* ISO 8859-8 (Hebrew) - 希伯來語(視覺順序)
* ISO 8859-8-I - 希伯來語(邏輯順序)
* ISO 8859-9 (Latin-5 或 Turkish) - 它把Latin-1的冰島語字母換走,加入土耳其語字母。
* ISO 8859-10 (Latin-6 或 Nordic) - 北日耳曼語支,用來代替Latin-4。
* ISO 8859-11 (Thai) - 泰語,從泰國的 TIS620 標准字集演化而來。
* ISO 8859-13 (Latin-7 或 Baltic Rim) - 波羅的語族
* ISO 8859-14 (Latin-8 或 Celtic) - 凱爾特語族
* ISO 8859-15 (Latin-9) - 西歐語言,加入Latin-1欠缺的法語及芬蘭語重音字母,以及歐元符號。
* ISO 8859-16 (Latin-10) - 東南歐語言。主要供羅馬尼亞語使用,並加入歐元符號。
很明顯,iso8859-1編碼表示的字符范圍很窄,無法表示中文字符。但是,由於是單字節編碼,和計算機最基礎的表示單位一致,所以很多時候,仍舊使用iso8859-1編碼來表示。而且在很多協議上,默認使用該編碼。
Unicode:
Unicode(統一碼、萬國碼、單一碼)是一種在計算機上使用的字符編碼。 它是http://www.unicode.org制定的編碼機制, 要將全世界常用文字都函括進去。 它為每種語言中的每個字符設定了統一並且唯一的二進制編碼,以滿足跨語言、跨平台進行文本轉換、處理的要求。 1990年開始研發,1994年正式公布。隨著計算機工作能力的增強,Unicode也在面世以來的十多年裡得到普及。 但自從unicode2.0開始,unicode采用了與ISO 10646-1相同的字庫和字碼,ISO也承諾ISO10646將不會給超出0x10FFFF的UCS-4編碼賦值,使得兩者保持一致。 Unicode的編碼方式與ISO 10646的通用字符集(Universal Character Set,UCS)概念相對應,目前的用於實用的Unicode版本對應於UCS-2,使用16位的編碼空間。 也就是每個字符占用2個字節,基本滿足各種語言的使用。實際上目前版本的Unicode尚未填充滿這16位編碼,保留了大量空間作為特殊使用或將來擴展。
UTF:
Unicode 的實現方式不同於編碼方式。
一個字符的Unicode編碼是確定的,但是在實際傳輸過程中,由於不同系統平台的設計不一定一致,以及出於節省空間的目的,對Unicode編碼的實現方式有所不同。
Unicode的實現方式稱為Unicode轉換格式(Unicode Translation Format,簡稱為 UTF)。
* UTF-8: 8bit變長編碼,對於大多數常用字符集(ASCII中0~127字符)它只使用單字節,而對其它常用字符(特別是朝鮮和漢語會意文字),它使用3字節。
* UTF-16: 16bit編碼,是變長碼,大致相當於20位編碼,值在0到0x10FFFF之間,基本上就是unicode編碼的實現,與CPU字序有關。
漢字編碼:
* GB2312字集是簡體字集,全稱為GB2312(80)字集,共包括國標簡體漢字6763個。
* BIG5字集是台灣繁體字集,共包括國標繁體漢字13053個。
* GBK字集是簡繁字集,包括了GB字集、BIG5字集和一些符號,共包括21003個字符。
* GB18030是國家制定的一個強制性大字集標准,全稱為GB18030-2000,它的推出使漢字集有了一個“大一統”的標准。
<!--[if !supportLists]-->1.3 <!--[endif]-->為什麼會有亂碼
在下面的描述中,將以"中文"兩個字為例,經查表可以知道其GB2312編碼是"d6d0 cec4",Unicode編碼為"4e2d 6587",UTF編碼就是"e4b8ad e69687"。注意,這兩個字沒有iso8859-1編碼,但可以用iso8859-1編碼來"表示",例如GB2312編碼的"中文"可以用iso8859-1表示成:"d6 d0 ce c4",utf-8編碼的"中文"可以用iso8859-1表示成:" e4 b8 ad e6 96 87"。
Java中出現亂碼主要有兩個原因:
<!--[if !supportLists]-->l <!--[endif]-->Unicode-->Byte, 如果目標代碼集不存在對應的代碼,則得到的結果是0x3f。
如:"\u00d6\u00ec\u00e9\u0046\u00bb\u00f9".getBytes("GBK") 的結果是 "?ìéF?ù", Hex 值是3fa8aca8a6463fa8b4.
仔細看一下上面的結果,你會發現\u00ec被轉換為0xa8ac, \u00e9被轉換為\xa8a6... 它的實際有效位變長了!這是因為GB2312符號區中的一些符號被映射到一些公共的符號編碼,由於這些符號出現在ISO-8859-1或其它一些SBCS字符集中,故它們在 Unicode中編碼比較靠前,有一些其有效位只有8位,和漢字的編碼重疊(其實這種映射只是編碼的映射,在顯示時仔細不是一樣的。Unicode 中的符號是單字節寬,漢字中的符號是雙字節寬) . 在Unicode\u00a0--\u00ff 之間這樣的符號有20個。了解這個特征非常重要!由此就不難理解為什麼JAVA編程中,漢字編碼的錯誤結果中常常會出現一些亂碼(其實是符號字符), 而不全是'?'字符, 就比如上面的例子。
<!--[if !supportLists]-->l <!--[endif]-->Byte-->Unicode, 如果Byte標識的字符在源代碼集不存在,則得到的結果是0xfffd.
如:
Byte ba[] = {(byte)0x81,(byte)0x40,(byte)0xb0,(byte)0xa1};
new String(ba,"gb2312");( new String(ba,"gbk");輸出為"丂啊")
結果是"?啊", hex 值是"\ufffd\u554a". 0x8140 是GBK字符,按GB2312轉換表沒有對應的值,取\ufffd. (請注意:在顯示該uniCode時,因為沒有對應的本地字符,所以也適用上一種情況,顯示為一個"?"。
<!--[if !supportLists]-->二、<!--[endif]-->Java語言對編碼的處理
在java應用軟件中,會有多處涉及到字符集編碼,有些地方需要進行正確的設置,有些地方需要進行一定程度的處理。
<!--[if !supportLists]-->2.1 <!--[endif]-->Byte[] getBytes(String charset)
這是java字符串處理的一個標准函數,其作用是將字符串所表示的字符按照charset編碼,並以字節方式表示。注意字符串在java內存中總是按unicode編碼存儲的。比如"中文",正常情況下(即沒有錯誤的時候)存儲為"4e2d 6587",如果charset為"gbk",則被編碼為"d6d0 cec4",然後返回字節"d6 d0 ce c4"。如果charset為"utf8"則最後是"e4 b8 ad e6 96 87"。如果是"iso8859-1",則由於無法編碼,最後返回 "3f 3f"(兩個問號)。
<!--[if !supportLists]-->2.2 <!--[endif]-->new String(byte[] bytes, String charset)
這是java字符串處理的另一個標准函數,和上一個函數的作用相反,將字節數組按照charset編碼進行組合識別,最後轉換為unicode存儲。參考上述getBytes的例子,"gbk" 和"utf8"都可以得出正確的結果"4e2d 6587",但iso8859-1最後變成了"003f 003f"(兩個問號)。因為utf8可以用來表示/編碼所有字符,所以new String( str.getBytes( "utf8" ), "utf8" ) === str,即完全可逆。