用php實現的下載css文件中的圖片的代碼
用php實現的下載css文件中的圖片的代碼
作為一個資深並且專業的扒皮人員,在我從初三開始投入偉大的互聯網中到現在積累了豐富的扒皮經驗。我相信每個做web的程序員也都會有類似的經歷。 在扒皮過程中,必不可
php 獲取當前訪問的url文件名的方法小結
推薦函數:一是PHP獲取當前頁面的網址: dedecms也是用的這個復制代碼 代碼如下: //獲得當前的腳本網址 function GetCurUrl() {
php date與gmdate的獲取日期的區別
date -- 格式化一個本地時間/日期 gmdate -- 格式化一個 GMT/UTC 日期/時間,返回的是格林威治標准時(GMT)。 舉個例子,我們
php下把數組保存為文件格式的實例應用
我使用過兩種辦法: 第一種是數組序列化,簡單,但是調用時比較麻煩一些;第二種是保存為標准的數組格式,保存時麻煩但是調用時簡單。 第一種方法: PHP代碼 復制代
php+mysql事務rollback&commit示例
mysql_query(BEGIN);//開始一個事務 mysql_query(SET AUTOCOMMIT=0); //設置事務不自動commit $inse
php 處理上百萬條的數據庫如何提高處理查詢速度
1.對查詢進行優化,應盡量避免全表掃描,首先應考慮在 where 及 order by 涉及的列上建立索引。 2.應盡量避免在 where 子句中對字段進行 n
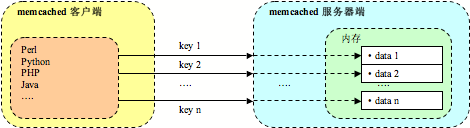 PHP Memcached應用實現代碼
PHP Memcached應用實現代碼
肖理達 (KrazyNio AT hotmail.com), 2006.04. 06, 轉載請注明出處一、memcached 簡介在很多場合,我們都會聽到 me
php 自寫函數代碼 獲取關鍵字 去超鏈接
1.根據權重獲取關鍵字 復制代碼 代碼如下: function getkey($contents){ $rows = strip_tags($contents)
檢查url鏈接是否已經有參數的php代碼 添加 ? 或 &
比如分頁,因為有些鏈接已經有參數了,在附加分頁信息的時候不能把原有的參數丟掉,所以判斷一下鏈接是否有參數,然後根據需要附加分頁信息。 方法很簡單: 復制代碼 代
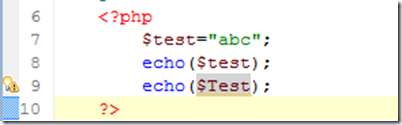
 一步一步學習PHP(1) php開發環境配置
一步一步學習PHP(1) php開發環境配置
1. AppServnetwork首先,我們先來下載PHP相關的一些東西。首先,我們來下載一整套PHP相關的工具——AppServnetwork。AppServ