簡介
既然 DB2 9 發布了,現在是時候對它的最新特性之一 —— pureXML® 進行測試驅動了。為此,建立了一個模擬的經紀業務環境。這個環境具有以下特征:
高事務量和並發性
小的事務大小
大量小型 XML 文檔
可變的 XML 文檔結構 —— 測試包含符合 FIXML 的數據,FIXML 是 Financial Information Exchange(FIX)標准的金融業 XML 實現。
請記住,XML 應用程序大致分成以下兩類:
面向數據的(高數據量,小文檔,這個測試就是針對這種情況)
面向文檔的(可變數據量,大文檔)
另外,涉及 XML 的數據庫應用程序也是各種各樣的,包括以下情況:
以 XML 形式發布關系數據
用 XML 全文本搜索進行內容和文檔管理
合並不同的數據源
表單處理
對 Web 服務和面向服務體系結構(SOA)的後端支持
基於消息的事務處理和基於 XML 的在線事務處理(OLTP),尤其是在金融業中
本文在一個基於 XML 的事務處理場景中進行性能度量,這個場景模擬一個面向數據的金融應用程序。測試設備包括最新的 POWER5 服務器(p5 560Q)以及 AIX 5.3 和 TotalStorage DS8100 磁盤系統。
DB2 9 和 XML
DB2 9 中新的 XML 支持包括純 XML 存儲、XML 索引、XQuery、SQL/XML 和高級的 XML 模式處理。“純” 意味著以標注上類型的樹的形式存儲和處理 XML 文檔,這與商業關系數據庫中以前的任何技術都不同。尤其是,pureXML 與將 XML 存儲為大對象(BLOB 或 CLOB)或者將 XML 分解到關系表中的技術有顯著差異。
測試場景:在線經紀業務
這個測試場景對在線經紀業務進行建模。我們曾經幫助金融公司采用 XML。這些經歷幫助我們理解了他們的數據和處理特征。這個場景有意地進行了簡化,但是在文檔、事務和 XML 模式方面仍然具有代表性。
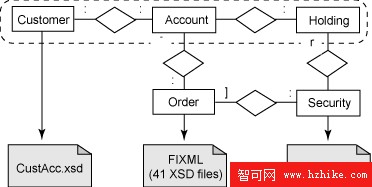
這個場景中主要的邏輯數據實體如下(見圖 1):
Customer: 一個客戶可以有一個或多個帳號(account)。
Account: 每個帳號包含一個或多個持有物(holding)。
Holding: 某一證券 的數量。
Security: 某一持有物的標識符(例如,股票名稱)。
Order: 為一個帳號 買賣一種證券 的訂單。
圖 1. 數據實體和 XML 模式
文檔處理和大小因文檔類型而異:
對於每個客戶,有一個 CustAcc 文檔,其中包含這個客戶的所有客戶信息、帳號信息和持有物信息。CustAcc 文檔的大小在 4KB 和 20KB 之間。
使用 FIXML 4.4 表示訂單。FIXML 是用於交易相關消息(比如買賣訂單)的行業標准 XML 模式(www.fixprotocol.org)。訂單文檔的大小是 1KB 到 2KB。訂單文檔有許多屬性,而且數據節點的比例很高。
證券文檔(20833 個)使用實際的證券符號和名稱,表示在美國交易的大多數股票和共同基金。它們的大小在 3KB 和 10KB 之間。
使用 Toxgene 數據生成器為這三個模式生成實例文檔。
測試設備和配置
測試在以下設備上運行:
處理器: IBM System p5 560Q,使用 8 個處理器的邏輯分區(LPAR),這是一個中等的 IBM System p5 560Q。8 個處理器以 1.5GHz 的頻率運行。
內存: 32GB
操作系統: AIX 5L v5.3 TL04(系統類型:9116-561,兩個 4 芯片模塊)
並發多線程提供 16 個並發執行線程或邏輯處理器。
安裝了一個多路徑子系統設備驅動程序(SDD)。這個特性可以改進存儲服務器訪問,比如改進數據可用性和存儲服務器上跨光纖通道適配器的動態 I/O 負載平衡。
存儲: IBM TotalStorage DS8100,通過 4 個光纖通道適配器連接到 LPAR。
AIX 配置
在安裝 DB2 期間,會自動執行所有必需的操作系統參數調整。設置了以下的虛擬內存管理參數,從而更好地控制文件系統緩存使用的內存量:
vmo -o minperm%=5
vmo -o maxclIEnt%=15
vmo -o maxperm%=15
另外,為了防止在數據裝載期間試圖緩存輸入文件,在掛裝命令中使用 -o cio 選項,用 JFS2 文件系統的並發 I/O 特性掛裝包含原始 XML 輸入文件的文件系統。
存儲配置
使用 TotalStorage DS8100 的標准默認配置。DS8100 在內部基本上是一個 POWER5 eServer p5 570。與之前的 ESS 使用 SSA 循環不同,DS8100 磁盤互連是一個 Switched Fiber Channel Arbitrated Loop(FC-AL),可以提供更快的數據訪問和高可用性。DS8100 配置了 128 個磁盤,在這些磁盤上創建了 16 個卷。在其中,8 個卷(64 個磁盤)分配給這個 LPAR。4 個卷使用 6+Parity+Spare 設置為 388GB。另外 4 個卷使用 7+Parity 設置為 452GB。創建了一個跨越所有 8 個卷的卷組(VG)。在這個卷組上定義了 DB2 數據庫的所有存儲組件,包括表空間、日志和備份。表 1 總結了配置。
表 1. 存儲配置
方面 配置 處理器 兩個處理器,每個附帶 pSerIEs POWER5 1.9 GHz 兩路 CEC 內存(緩存) 32GB 磁盤互連 Switched FC-AL 磁盤數量 128 個(只有 64 個由主機 LPAR 使用) 磁盤大小/速度 73 GB,15000 RPM
DB2 配置
DB2 9 包含許多新特性,包括新的自治自調整功能。在這個測試中,利用了其中幾種自治功能,包括:
自動存儲管理
自調整內存管理
因為啟動了 DB2 的自調整內存管理器(STMM),它會連續調整一系列 DB2 配置參數的設置。在測試運行期間 STMM 管理和調整的一些關鍵的 DB2 配置參數見表 2。要意識到的重要情況是,STMM 會根據正在運行的工作負載類型(比如純插入、純查詢或混合型工作負載)自主地修改這些值。
表 2. 數據庫配置,自調整
DB 配置參數名 初始設置 SELF_TUNING_MEM ON(默認值) DATABASE_MEMORY AUTOMATIC(默認值) SORTHEAP 156 SHEAPTHRES_SHR 10000 LOCKLIST 53000 MAXLOCKS 80 PCKCACHESZ 27000 緩沖池名 初始設置 IBMDEFAULTBP 1100000 CATBP 4000 TEMPBP 1000
DBA 只需要執行很少的數據庫配置任務,見表 3。
表 3. 數據庫配置,手工
方面 配置/設置 數據庫 Unicode。所有表空間采用自動存儲。DB2 日志在單獨的條帶上 內存 為所有測試啟用 STMM 頁面大小 16K(表空間和緩沖池) 表和索引 3 個表:CustAcc、order、security。24 個 XML 索引:10 個在 CustAcc 上,5 個在 order 上,9 個在 security 上 表空間 一共 6 個表空間:3 個表各有一個表空間,每個表的索引各有一個表空間。對所有表空間禁用文件系統緩存 緩沖池 一共 3 個緩沖池:默認緩沖池、用於編目表空間的緩沖池和用於臨時表空間的緩沖池
工作負載
設計、執行並度量了三種 XML 工作負載:
插入(只寫)
查詢(只讀)
混合(讀-寫)
這些工作負載都具有很高的並發性。工作負載由一個 Java 驅動程序執行,這個程序產生一個到 n 個並發線程。每個線程模擬一個用戶,該用戶連接到數據庫並提交一個事務流,而不考慮次數。每個事務流是以加權方式從一系列事務模板中隨機選擇的一系列事務。每個事務被分配一個權重,這個權重決定這個事務在工作負載中的百分比。在運行時,事務中的參數標志替換為具體的值,這些值是從可配置的隨機值分布和輸入列表中提取的。
插入工作負載:只寫
插入工作負載用大約 100GB 的原始 XML 數據填充數據庫:
600 萬個 CustAcc 文檔
3000 萬個訂單
20833 種證券
首先,83 個並發用戶插入所有證券。然後,分階段插入 CustAcc 和訂單文檔,從而檢驗插入性能是可伸縮的。在每個階段使用 100 個並發用戶,見表 4。
表 4. 分階段的數據庫填充
階段 數據庫中的 CustAcc 文檔數量 數據庫中的訂單文檔數量 1 100,000 500,000 2.1 200,000 1,000,000 2.2 300,000 1,500,000 2.3 400,000 2,000,000 2.4 500,000 2,500,000 2.5 600,000 3,000,000 3.1 1,000,000 5,000,000 3.2 1,500,000 7,500,000 3.3 2,000,000 10,000,000 4.1 2,500,000 12,500,000 4.2 3,000,000 15,000,000 4.3 3,500,000 17,500,000 4.4 4,000,000 20,000,000 5.1 4,500,000 22,500,000 5.2 5,000,000 25,000,000 5.3 5,500,000 27,500,000 5.4 6,000,000 30,000,000
查詢工作負載:只讀
在插入負載填充數據庫之後,對數據庫執行一個只讀的工作負載。這個工作負載由 7 個 XML 查詢組成,使用 25、50、75、100、125 和 150 個並發用戶以不同的並發度執行。測試的時間長度是這 6 個測試各運行一個小時。
7 個查詢都具有以下特征:
它們都是用符合標准的 SQL/XML 表示法編寫的,比如帶有嵌入式 XQuery 的 SQL,利用了參數標志。
它們使用 SQL/XML 謂詞 XMLEXISTS 根據一個或多個條件選擇 XML 文檔,條件用 XQuery 表示法表示。
它們使用 SQL/XML 函數 XMLQUERY 檢索完整的或部分 XML 文檔,或者構造與數據庫中存儲的文檔不同的結果文檔。
它們使用與 XML 數據中的名稱空間對應的 XML 名稱空間。
它們利用一個或多個 XML 索引完全避免表掃描。
這 7 個查詢在工作負載中具有同樣的權重。
表 5 顯示這 7 個查詢的特征差異和它們涉及的表。
表 5. XML 查詢小結
Q 查詢名 CustAcc Security Order 特征 1 get_order - - X 返回完整的訂單文檔,但是沒有 FIXML 根元素。 2 get_security - X - 返回完整的證券文檔。 3 customer_profile X - - 提取 7 個客戶元素來構造概況文檔。 4 search_securitIEs - X - 根據 4 個謂詞從一些證券中提取元素。 5 account_summary X - - 構造一個帳號說明。 6 get_security_price - X - 提取一種證券的價格。 7 customer_max_order X - X 聯結 CustAcc 和訂單,尋找一位客戶的最大訂單。
混合工作負載:讀/寫
與只讀工作負載相似,混合工作負載針對填充的 600 萬個 CustAcc 文檔和 3000 萬個訂單執行,並使用 25、50、75、100、125 和 150 個並發用戶產生不同的並發度。測試的時間長度是每個測試各運行一個小時。
混合工作負載由以下操作組成:
70% 的讀操作:查詢
30% 的寫操作:6% 的更新操作,12% 的文檔刪除操作,12% 的插入操作。
查詢與上面的只讀工作負載中的查詢完全一樣,下面是定義更新/刪除/插入事務時考慮的情況:
更新客戶帳號以反映交易(訂單的執行),但是不需要在每個訂單之後立即執行(3% 的 CustAcc 更新)
在我們的場景中不更新訂單文檔(因此沒有訂單更新事務)
在交易時間定期更新證券的價格(3% 的證券更新)
客戶的插入和刪除少(2% 的 CustAcc 插入,2% 的 CustAcc 刪除)
新訂單不斷到達,舊訂單從系統中刪除,兩者的速率是相同的(10% 的訂單插入,10% 的訂單刪除)
證券種類的數量是固定的(沒有刪除和插入事務)
通過考慮這些目標,產生了表 6 所示的事務組合。
表 6. 混合工作負載的事務
# 名稱 類型 占總量的百分比 1 get_order 查詢 10 2 get_security 查詢 10 3 customer_profile 查詢 10 4 search_securitIEs 查詢 10 5 account_summary 查詢 10 6 get_security_price 查詢 10 7 customer_max_order 查詢 10 8 upd_custacc 更新 3 9 upd_security 更新 3 10 del_custacc 刪除 2 11 del_order 刪除 10 12 insert_custacc 插入 2 13 Insert_order 插入 10
更新事務首先根據一個 XQuery 謂詞讀取一個特定文檔,然後使用它更新數據庫中這個文檔的原副本。在實際情況下,在讀取和更新步驟之間會更新文檔,但是這與本文的目的沒什麼關系,因此為了簡化省略了這個步驟。
在執行插入時不進行 XML 模式檢驗。
更新和刪除操作所針對的文檔是在數據庫中隨機選擇的。每個新插入的訂單和 CustAcc 文檔馬上可以被後續的事務更新或刪除。
結果
數據庫設置和所有工作負載不間斷地連續執行。23 小時的不間斷系統測試的結果見表 7。
表 7. 使用所有工作負載的全面測試的計時
任務 花費的時間(分鐘) 解釋/說明 創建數據庫和更新數據庫配置 1 - 插入工作負載 160 所有階段的總時間 在表和索引上運行 stats 340 時間的分布如下:
22 分 - 證券
2 小時 45 分 - CustAcc
2 小時 54 分 - 訂單
數據庫備份 23 - 查詢和混合工作負載 825 這兩個工作負載都使用 25、50、75、100、125 和 150 個用戶運行 數據庫恢復 17.5 - 其他 ~15 其他各種任務 總時間 ~1380 總運行時間為 23 小時插入工作負載的結果
插入 36,020,833 個文檔花費的總時間大約是 160 分鐘,產生的平均吞吐量是每秒 3770 個插入。吞吐量隨文檔的大小而變化:
訂單文檔(1K 到 2K)以平均每秒 5320 個插入的吞吐量插入。
帳號文檔(3K 到 10K)以平均每秒 1550 個插入的吞吐量插入。
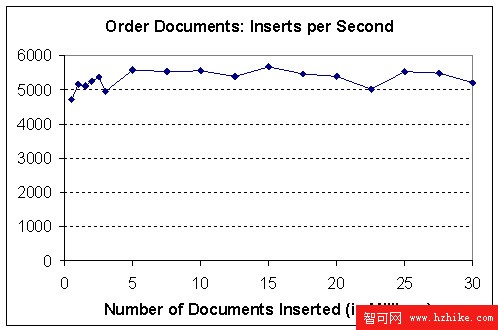
插入這兩種文檔的數據量速度都是大約每小時 30GB。圖 2 顯示隨著訂單數量增長到 300 萬個文檔,訂單插入的速度幾乎保持不變。
圖 2. 訂單文檔的插入速度
查詢工作負載的結果
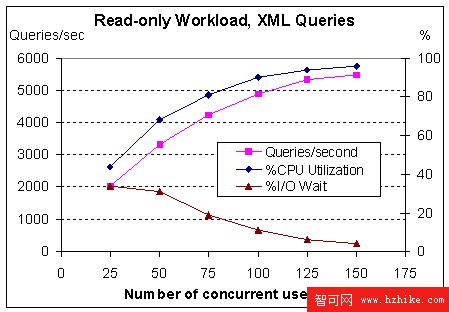
查詢工作負載的性能隨著用戶數量的增加和更好地利用 CPU 而增加。正如預期的,隨著 CPU 利用率接近 100%,吞吐量曲線逐漸變平。最好的吞吐量出現在有 150 個用戶的情況下,在 CPU 利用率為 96% 時達到每秒 5480 個查詢,見圖 3。
將用戶數量增加到 175 並不會使吞吐量顯著提高,因為機器已經達到滿負荷了。
圖 3. 只讀查詢吞吐量、CPU 利用率和 I/O 等待時間
混合工作負載的結果
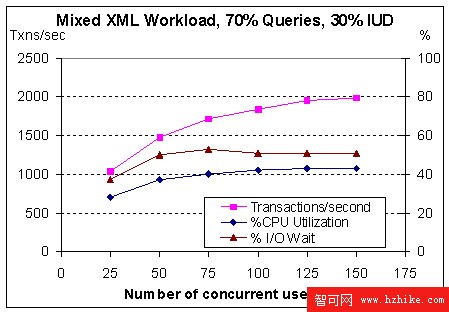
混合工作負載最好的性能也出現在有 150 個並發用戶時,見圖 4。吞吐量是每秒 1980 個事務。正如預期的,混合工作負載的吞吐量比純查詢和純插入工作負載低。
圖 4. 混合工作負載吞吐量、CPU 利用率和 I/O 等待時間
結束語
這次性能研究的目的是,在使用最新的 IBM 服務器硬件、存儲、AIX 操作系統和 DB2 9 軟件的情況下,演示 XML 工作負載的操作性能特征。所有測試都使用 DB2 新的 STMM 和自動存儲特性。
我們覺得,對於包含基於消息的事務處理的 XML 應用程序以及處理大量小 XML 文檔的 Web 服務應用程序,這個工作負載場景是有代表性的。選擇金融業是因為我們在這方面有經驗,而且它采用了一種成熟的標准化的 XML 模式 —— FIXML。
下面對測試的情況做一下總結:
總測試時間為 23 小時,包括創建數據庫。
測試數據由 600 萬個 CustAcc 文檔、3000 萬個訂單文檔和 20833 個證券文檔組成。
測試分別采用 25、50、75、100、125 和 150 個並發用戶。
插入吞吐量(每秒事務數,即 tps)隨文檔的大小而變化,但是在一個大小內是線性的。吞吐數據量穩定在每小時 30GB,與文檔大小無關:
1550 tps(CustAcc 文檔,4K 到 20K)
5320 tps(訂單文檔,1K 到 2K)
查詢吞吐量隨並發用戶數量伸縮:
25 個用戶時 2000 tps
150 個用戶時 5500 tps(CPU 利用率最大,I/O 等待時間接近零)
混合事務吞吐量也隨並發用戶數量伸縮,直到大約 2000 tps:
25 個用戶時 1000 tps
150 個用戶時 2000 tps(~42% 的CPU 利用率,~50% 的 I/O 等待時間)。