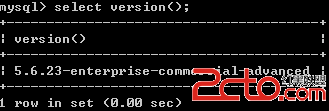
基於mysql系統構造的深刻解析。本站提示廣大學習愛好者:(基於mysql系統構造的深刻解析)文章只能為提供參考,不一定能成為您想要的結果。以下是基於mysql系統構造的深刻解析正文
由:銜接池組件、治理辦事和對象組件、sql接口組件、查詢剖析器組件、優化器組件、
緩沖組件、插件式存儲引擎、物理文件構成。
mysql是獨有的插件式系統構造,各個存儲引擎有本身的特色。

mysql各個存儲引擎概述:
innodb存儲引擎:[/color][/b] 面向oltp(online transaction processing)、行鎖、支撐外鍵、非鎖定讀、默許采取repeaable級別(可反復讀)經由過程next-keylocking戰略防止幻讀、拔出緩沖、二次寫、自順應哈希索引、預讀
myisam存儲引擎:不支撐事務、表鎖、全文索引、合適olap(在線剖析處置),個中myd:放數據文件,myi:放索引文件
ndb存儲引擎:集群存儲引擎,share nothing,可進步可用性
memory存儲引擎:數據寄存在內存中,表鎖,並發機能差,默許應用哈希索引
archive存儲引擎:只支撐insert和select zlib算法緊縮1:10,合適存儲歸檔數據如日記等、行鎖
maria存儲引擎:目標代替myisam、緩存數據和索引、行鎖、mvcc
innodb特征:
主系統構造:默許7個後台線程,4個io thread(insert buffer、log、read、write),1個master thread(優先級最高),1個鎖(lock)監控線程,1個毛病監控線程。可以經由過程show engine innodb status來檢查。新版本已對默許的read thread和write thread分離增年夜到4個,可經由過程show variables like 'innodb_io_thread%'檢查。
存儲引擎構成:緩沖池(buffer pool)、重做日記緩沖池(redo log buffer)和額定的內存池(additional memory pool).詳細設置裝備擺設可由show variables like 'innodb_buffer_pool_size'、show variables like
'innodb_log_buffer_size'、show variables like 'innodb_additional_mem_pool_size'來檢查。
緩沖池:占最年夜塊內存,用來寄存各類數據的緩存包含有索引頁、數據頁、undo頁、拔出緩沖、自順應哈希索引、innodb存儲的鎖信息、數據字典信息等。任務方法老是將數據庫文件按頁(每頁16k)讀取到緩沖池,然後按比來起碼應用(lru)的算法來保存在緩沖池中的緩存數據。假如數據庫文件須要修正,老是起首修正在緩存池中的頁(產生修正後即為髒頁),然後再依照必定的頻率將緩沖池的髒頁刷新到文件。經由過程敕令show engine innodb status;來檢查。
日記緩沖:將重做日記信息先放入這個緩沖區,然後按必定頻率將其刷新到重做日記文件。

master thread:
loop主輪回每秒一次的操作:
日記緩沖洗新到磁盤,即便這個事務還沒有提交。(老是履行,所以再年夜的事務commit
的時光也是很快的)
歸並拔出緩沖(innodb以後一秒產生的io次數小於5次則履行)
至少刷新100個innodb的緩沖池中的髒頁到磁盤(跨越設置裝備擺設的髒頁所占緩沖池比例則執
行,在設置裝備擺設文件中由innodb_max_dirty_pages_pac決議,默許是90,新版本是75,
谷歌建議是80)
假如以後沒用用戶運動,切換到backgroud loop
loop主輪回每10秒一次的操作:
刷新100個髒頁到磁盤(曩昔10秒IO操作小於200次則履行)
歸並至少5個拔出緩沖(老是)
將日記緩沖到磁盤(老是)
刪除無用的Undo頁(老是)
刷新100個或許10個髒頁到磁盤(有跨越70%的髒頁,刷新100個髒頁;不然刷新10個髒頁)
發生一個檢討點
backgroud loop,若以後沒有效戶運動(數據庫余暇時)或許數據庫封閉時,就會切換到這個輪回:
刪除無用的Undo頁(老是)
歸並20個拔出緩沖(老是)
跳回到主輪回(老是)
赓續刷新100個頁,直到相符前提(能夠在flush loop中完成)
假如flush loop中也沒有甚麼工作可以做了,InnoDB存儲引擎會切換到suspend_loop,將master thread掛起,期待事宜的產生。若啟用了InnoDB存儲引擎,卻沒有應用任何InnoDB存儲引擎的表,那末master thread老是處於掛起狀況
拔出緩沖:不是緩沖池的一部門,Insert Buffer是物理頁的一個構成部門,它帶來InnoDB機能的進步。依據B+算法(下文會提到)的特色,拔出數據的時刻會主鍵索引是次序的,不會形成數據庫的隨機讀取,而關於非集合索引(即幫助索引),葉子節點的拔出不再是次序的了,這時候須要團圓地拜訪非集合索引,拔出機能在這裡變低了。InnoDB引入拔出緩沖,斷定非集合索引頁能否在緩沖池中,假如在則直接拔出;不在,則先放在 拔出緩沖區中。然後依據上述master thread中引見的,會有必定的頻率將拔出緩沖歸並。另外,幫助索引不克不及是獨一的,由於拔出到拔出緩沖時,其實不去查找索引頁的情形,不然依然會形成隨機讀,掉去拔出緩沖的意義了。拔出緩沖能夠會占緩沖池中內存,默許也能會占到1/2,所以可以將這個值調小點,到1/3。經由過程IBUF_POOL_SIZE_PER_MAX_SIZE來設置,2表現1/2,3表現1/3。
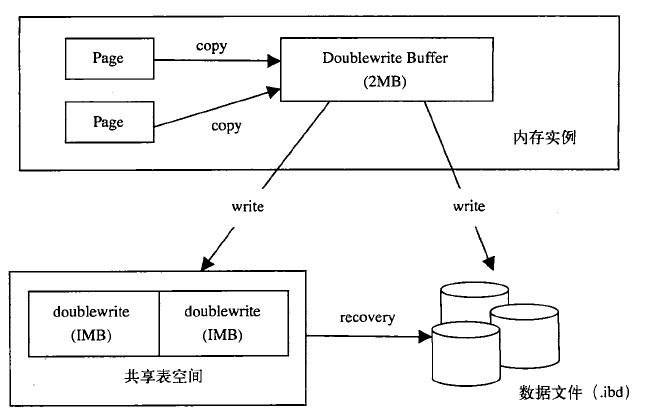
兩次寫: 它帶來InnoDB數據的靠得住性。假如寫掉效,可以經由過程重做日記停止恢復,然則重做日記中記載的是對頁的物理操作,假如頁自己破壞,再對其停止重做是沒成心義的。所以,在運用重做日記前,須要一個頁的正本,當寫入掉效產生時,先經由過程頁的正本來復原該頁,再停止重做,這就是doublewire。
恢單數據=頁正本+重做日記
自順應哈希索引:InnoDB存儲引擎提出一種自順應哈希索引,存儲引擎會監控對表上索引的查找,假如不雅察到樹立樹立哈希索引會帶來速度的晉升,則樹立哈希索引,所以稱之為自順應的。自順應哈希索引只能用來搜刮等值的查詢,如select * from table where index_col='***', 另外自順應哈希是由InnoDB存儲引擎掌握的,我們只能經由過程innodb_adaptive_hash_index來禁用或啟用,默許開啟。
mysql 文件
參數文件:告知Mysql實例啟動時在哪裡可以找到數據庫文件,而且指定某些初始化參數,這些參數界說了某種內存構造的年夜小等設置。用文件存儲,可編纂,若啟動時加載不到則不克不及勝利啟動(與其他數據庫分歧)。參數有靜態和靜態之分,靜態相當於只讀,靜態是可以set的。如我們經由過程show variable like '***'查出來的key、value值,是可以經由過程set key=value直接修正的。同是,修正時還有感化域之分,即這個seesion個有用和全局有用,在對應的key前加上session或global便可,如select @@seesion.read_buffer_size、set @@global.read_buffer_size。
日記文件:用來記載Mysql實例對某種前提做出呼應時寫入的文件。如毛病日記文件、二進制日記文件、慢查詢日記文件、查詢日記文件等。
毛病日記:經由過程show variables like 'log_error'來檢查毛病日記寄存地址
慢查詢日記:經由過程show variables like '%long%' 檢查慢查詢日記記載的阈值,新版本設成了0.05;經由過程show variables like 'log_slow_queries'檢查能否開啟了,默許為封閉的;經由過程show variabes like 'log_queries_not_using_indexes'檢查是將沒有應用索引的查詢記載到慢日記中。mysql中可以直接經由過程mysqldumpslow敕令來檢查慢日記。
二進制文件:不記載查詢,只記載對數據庫一切的修正操作。目標是為了恢復(point-in-time修復)和復制。經由過程show variables like 'datadir'檢查寄存途徑。二進制日記支撐STATEMENT、ROW、MIX三種格局,經由過程binlog_format參數設定,平日設置為ROW,可認為數據庫的恢復和復制帶來更好的靠得住性,但會帶來二進制文件年夜小的增長,復制時會增長收集開支。mysql中經由過程mysqlbinlog檢查二進制日記文件內容。
socket文件:當用Unix域套接字方法停止銜接時須要的文件。
pid文件:Mysql實例的過程ID文件。
Mysql表構造文件:用來寄存Mysql表構造界說文件。由於Mysql插件式存儲引擎的系統構造,每一個表都有一個對應的文件,以frm後綴開頭。
存儲引擎文件:存儲本身的文件來保留各類數據,真正存儲了數據和索引等數據。上面重要引見InnoDB的存儲引擎下的表空間文件和重做日記文件。
表空間文件:InnoDB默許的表空間文件為ibdata1,可經由過程show variables like 'innodb_file_per_table'檢查每一個表能否發生零丁的.idb表空間文件。然則,零丁的表空間文件僅存儲該表的數據、索引和拔出緩沖等信息,其他信息照樣寄存在默許的表空間中。

重做日記文件:實例和介質掉敗,重做日記文件就可以派上用處,如數據庫失落電,InnoDB存儲引擎會應用重做日記恢復到失落電前的時辰,以此來包管數據的完全性。參數innodb_log_file_size指定了重做日記文件的年夜小;innodb_log_file_in_group指定了日記文件組中重做日記文件的數目,默許為2,innodb_mirrored_log_groups指定了日記鏡像文件組的數目,默許為1,代表只要一個日記文件組,沒有鏡像;innodb_log_group_home_dir指定了日記文件組地點途徑,默許在數據庫途徑下。
二進制日記和重做日記的差別:起首,二進制日記會記載一切與Mysql有關的日記記載,包含InnoDB、MyISAM、Heap等其他存儲引擎的日記。而InnoDB存儲引擎重做日記只存儲有關其自己的事務日記;其次內容分歧,不論將二進制日記文件記載的格局設為STATEMENT照樣ROW,又或許是MIXED,其記載的都是關於一個事務的詳細操作內容。而InnoDB存儲引擎的重做日記文件記載的關於每一個頁的更改的物理情形 。另外,寫入時光分歧,二進制日記文件是在事務提交進步行記載的,而在事務停止的進程中,赓續有重做日記條目被 寫入重做日記文件中。
mysql innodb表
表空間:表空間可看作是InnoDB存儲引擎邏輯構造的最高層。
段:表空間由各個段構成,罕見的段稀有據段、索引段、回滾段等。
區:由64個持續的頁構成,每一個頁年夜小為16kb,即每一個區年夜小為1MB。
頁:每頁16kb,且不克不及更改。罕見的頁類型有:數據頁、Undo頁、體系頁、事務數據頁、拔出緩沖位圖頁、拔出緩沖余暇列表頁、未緊縮的二進制年夜對象頁、緊縮的二進制年夜對象頁。
行:InnoDB存儲引擎是面向行的(row-oriented),每頁最多許可寄存7992行數據。
行記載格局:罕見兩種行記載格局Compact和Redundant,mysql5.1版本後,重要是Compact行記載格局。關於Compact,不論是char型照樣varchar型,null型都是不占用存儲空間的;關於Redudant,varchar的null不占用空間,char的null型是占用存儲空間的。
varchar類型的長度限制是65535,其實達不到,會有其余開支,普通是65530閣下,這還跟拔取的字符集有關。另外這個長度限制是一整行的,例如:create table test(a varchar(22000), b varchar(22000), cvarchar(22000)) charset=latin1 engine=innodb也會報錯。
關於blob類型的數據,在數據頁面中只保留了varchar(65535)的前768個字節前綴數據,以後跟的是偏移量,指向行溢出頁,也就是Uncompressed BLOB Page。新的InnoDB Plugin引入了新的文件格局稱為Barracuda,其有兩種新的行記載格局Compressed和Dynamic,二者關於存入Blog字段采取了完整溢出的方法,在數據庫頁中寄存20個字節的指針,現實的數據都存入在BLOB Page中。


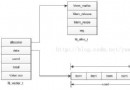
數據頁構造:數據頁構造由以下7個部門構成:
File Header(文件頭):記載頁的一些頭信息,如頁偏移量、上一頁、下一頁、頁類型等,固定長度為38個字節。
Page Header(頁頭):記載頁的狀況信息,堆中記載數、指向余暇列表的指針、已刪除記載的字節數、最初拔出的地位等,固定長度共56個字節。
Infimun+Supremum Records:在InnoDB存儲引擎中,每一個數據頁中有兩個虛擬的行記載,用來限制記載的界限。
Infimun記載是比該頁中任何主鍵都要小的值,Supermum指比任何能夠年夜的值還要年夜的值。這兩個值在頁創立時被樹立,而且在任何情形下不會被刪除。在Compact行格局和Redundant行格局下,二者占用的字節數各不雷同。

User Records(用戶記載,即行記載):完成記載的內容。再次強調,InnoDB存儲引擎表老是B+村索引組織的。
Free Space(余暇空間):指余暇空間,異樣也是個鏈表數據構造。當一筆記錄被刪除後,該空間會被參加余暇鏈 表中。
Page Directory(頁目次):頁目次寄存了記載的絕對地位,其實不是偏移量,有些時刻這些記載稱為Slots(槽),InnoDB其實不是每一個記載一個槽,槽是一個稀少目次,即一個槽中能夠屬於多個記載,起碼屬於4筆記錄,最多屬於8筆記錄。須要切記的是,B+樹索引自己其實不能找到詳細的一筆記錄,B+樹索引能找到只是該記載地點的頁。數據庫把頁載入內存,然後經由過程Page Directory再停止二叉查找。只不外二叉查找的時光龐雜度低,同時內存中的查找很快,是以經由過程疏忽了這部門查找所用的時光。
File Trailer(文件開頭信息):為了包管頁完全地寫入磁盤(如寫進程的磁盤破壞、機械宕機等),固定長8個字節。
視圖:Mysql中的視圖老是虛擬的表,自己不支撐物化視圖。然則經由過程一些其他技能(如觸發器),異樣也能夠完成一些簡略的物化視圖的功效。
分區:Mysql數據庫支撐RANGE、LIST、HASH、KEY、COLUMNS分區,而且可使用HASH或KEY來停止子分區。
mysql innodb罕見索引與算法:
B+樹索引:B+樹的數據構造絕對較龐雜,B代表的是balance最早是從均衡二叉樹演變而來,但B+樹其實不是一個二叉樹,對其較具體的引見可以拜見這篇文章:http://blog.csdn.net/v_JULY_v/article/details/6530142 因為B+樹索引的高扇出性,是以在數據庫中,B+樹的高度普通都在2~3層,也就關於查找某一鍵值的行記載,最多只需2到3次IO,如今普通的磁盤每秒至多可以做100次IO,2~3次的IO意味著查詢時光只需0.02~0.03秒。
數據庫中的B+索引可以分為集合索引(clustered index)和幫助集合索引(secondary index),但其外部都是B+樹的,即高度均衡的,葉子節點寄存數據。
集合索引:因為集合索引是依照主鍵組織的,所以每張表只能有一個集合索引,每一個數據頁都經由過程雙向鏈表停止銜接,葉子節點寄存一整行的信息,所以查詢優化器更偏向走集合索引。另外,關於集合索引的存儲是邏輯上持續的。所以,集合索引關於主鍵的排序查找和規模查找速度異常快。
幫助索引:也叫非集合索引,葉子節點不存全體數據,重要存鍵值及一個boomark(其實就是集合索引的鍵)告知InnoDB哪裡可以找到與索引絕對應的行數據,如一個高度為3的幫助索引和一個高度為3的集合索引,若依據幫助索引來查詢行記載,一共須要6次IO。別的幫助索引可以有多個。
索引的應用准繩:高選擇、掏出表中的少部門數據(也稱為獨一索引)。普通掏出的數據量跨越表中數據的20%,優化器不會應用索引,而停止全表掃描。如關於性別等字段是沒成心義的。
結合索引: 也稱復合索引,是在多列(>=2)上樹立的索引。Innodb中的復合索引也是b+ tree構造。索引的數據包括多列(col1, col2, col3…),在索引中順次依照col1, col2, col3排序。如(1, 2), (1, 3),(2,0)…應用復合索引要充足應用最左前綴准繩,望文生義,就是最左優先。如創立索引ind_col1_col2(col1, col2),那末在查詢where col1 = xxx and col2 = xx或許where col1 = xxx都可以走ind_col1_col2索引,但where col2=****是走不到索引的。在創立多列索引時,要依據營業需求,where子句中應用最頻仍且過濾後果好的的一列放在最右邊。
哈希索引:哈希算法也是比擬罕見的算法,mysql innoDB中應用了比擬罕見的鏈地址法停止去重。另外下面曾經說起,innoDB中的hash是自順應的,甚麼時刻應用hash是體系決議的,沒法停止人工設置。
二分查找法:這個算法比擬罕見,這裡就不多說起了。在InnoDB中,每頁Page Directory中的槽是依照主鍵的次序寄存的,關於某一條詳細記載的查詢是經由過程對Page Directory停止二分查找獲得的。
mysql innodb中的鎖
InnoDB存儲引擎鎖的完成和Oracle異常相似,供給分歧性的非鎖定讀、行級鎖支撐、行級鎖沒有相干的開支,可以同時獲得並發性和分歧性。
InnoDB存儲引擎完成了以下兩種尺度的行級鎖:
同享鎖(S Lock):許可事務讀一行數據;
排他鎖(X Lock):許可事務刪除或許更新一行數據。
當一個事務曾經取得了行r的同享鎖,那末別的的事務可以立刻取得行r的同享鎖,由於讀取沒有轉變行r的數據,我們稱這類情形為鎖兼容。但假如有事務想取得行r的排他鎖,則它必需期待事務釋放行r上的同享鎖————這類情形稱為鎖不兼容。

在InnoDB Plugin之前,只能經由過程SHOW FULL PROCESSLIST,SHOW ENGINE INOODB STATUS等敕令來檢查以後的數據庫要求,然後再斷定以後事務中的鎖的情形。新版本的InnoDB Plugin中,在INFORMATION_SCHEMA架構下添加了INNODB_TRX、INNODB_LOCKS、InnoDB_LOCK_WAITS。經由過程這三張表,可以更簡略地監控以後的事務並剖析能夠存在的鎖的成績。
INNODB_TRX由8個字段構成:
trx_id:InnoDB存儲引擎外部獨一的事務ID
trx_state:以後事務的狀況。
trx_started:事務的開端時光。
trx_requested_lock_id:期待事務的鎖ID。如trx_state的狀況為LOCK WAIT,那末該值代表以後的期待之前事務占用鎖資本的ID.
若trx_state不是LOCK WAIT,則該值為NULL。
trx_wait_started:事務期待開端的時光。
trx_weight:事務的權重,反應了一個事務修正和鎖住的行數。在InnoDB存儲引擎中,當產生逝世鎖須要回滾時,InnoDB存儲會選
擇該值最小的停止回滾。
trx_mysql_thread_id:Mysql中的線程ID,SHOW PROCESSLIST顯示的成果。
trx_query:事務運轉的sql語句。
經由過程select * from infomation_schema.INNODB_TRX;可檢查
INNODB_LOCKS表,該表由以下字段構成:
lock_id:鎖的ID。
lock_trx_id:事務ID。
lock_mode:鎖的形式。
lock_type:鎖的類型,表鎖照樣行鎖。
lock_table:要加鎖的表。
lock_index:鎖的索引。
lock_space:InnoDB存儲引擎表空間的ID號。
lock_page:被鎖住的頁的數目。若是表鎖,則該值為NULL。
lock_rec:被鎖住的行的數目。若是表鎖,則該值為NULL。
lock_data:被鎖住的行的主鍵值。當是表鎖時,該值為NULL。
經由過程select * from information_schema.INNODB_LOCK;可檢查
INNODB_LOCK_WAIT由4個字段構成:
requesting_trx_id:請求鎖資本的事務ID。
requesting_lock_id:請求的鎖的ID。
blocking_trx_id:壅塞的鎖的ID。
經由過程select * from information_schema.INNODB_LOCK_WAITS;可檢查。
分歧性的非鎖定讀:InnoDB存儲引擎經由過程行多版本掌握的方法來讀取以後履行時光數據庫中行的數據。假如讀取的行正在履行Delete、update操作,這時候讀取操作不會是以而會期待行上鎖的釋放,相反,InnoDB存儲引擎會去讀取行的一個快照數據。快照數據是指該行之前版本的數據,該完成是經由過程Undo段來完成。而Undo用來事務中回滾數據,是以快照自己是沒有額定開支的。另外,快照數據是不須要上鎖的,由於沒有需要對汗青的數據停止修正。一個行能夠有不止一個快照數據,所以稱這類技巧為行多版本技巧。由此帶來並發掌握,稱之為多版本並發掌握(Multi VersionConcurrency Control, MVCC)。
事務的隔離級別:Read uncommitted、Read committed、Repeatable read、serializable。在Read Committed和Repeatable Read下,InnoDB存儲引擎應用非鎖定分歧性讀。但是,關於快照的界說卻分歧。在Read Committed事務隔離級別下,關於快照數據,非分歧性讀老是讀取被鎖定行的最新一份快照數據。在Repeatable事務隔離級別下,關於快照數據,非分歧性讀老是讀取事務開端時的行數據版本。

鎖的算法:
Record Lock:單行記載上的鎖
Gap Lock:間隙鎖,鎖定一個規模,但不包括記載自己
Next-Key Lock:Gap Lock + Record Lock,鎖定一個規模,而且鎖定記載自己。加倍具體的引見可以拜見這篇blog,http://www.db110.com/?p=1848
鎖的成績:
喪失更新:經典的數據庫成績,當兩個或多個事務選擇統一行,然後基於最後選定的值更新該行時,會產生喪失更新成績。每一個事務都不曉得其它事務的存在。最初的更新將重寫由其它事務所做的更新,這將招致數據喪失。
例:
事務A和事務B同時修正某行的值,
1.事務A將數值改成1並提交
2.事務B將數值改成2並提交。
這時候數據的值為2,事務A所做的更新將會喪失。
處理方法:事務並行變串行操作,對更新操作加排他鎖。
髒讀:一個事務讀到另外一個事務未提交的更新數據,即讀到髒數據。
例:
1.Mary的原工資為1000, 財政人員將Mary的工資改成了8000(但未提交事務)
2.Mary讀取本身的工資 ,發明本身的工資變成了8000,眉飛色舞!
3.而財政發明操作有誤,回滾了事務,Mary的工資又變成了1000, 像如許,Mary記著的工資數8000是一個髒數據。
處理方法:髒讀只要在事務隔離級別是Read Uncommitted的情形下才會湧現,innoDB默許隔離級別是Repeatable Read,所以臨盆情況下不會湧現髒讀。
弗成反復讀:在統一個事務中,屢次讀取統一數據,前往的成果有所分歧。換句話說就是,後續讀取可以讀到另外一個事務已提交的更新數據。相反"可反復讀"在統一事務屢次讀取數據時,可以或許包管所讀數據一樣,也就是後續讀取不克不及讀到另外一事務已提交的更新數據。髒讀和弗成反復讀的重要差別在於,髒讀是讀到未提交的數據,弗成反復讀是讀到已提交的數據。
例:
1.在事務1中,Mary 讀取了本身的工資為1000,操作並沒有完成
2.在事務2中,這時候財政人員修正了Mary的工資為2000,並提交了事務.
3.在事務1中,Mary 再次讀取本身的工資時,工資變成了2000
處理方法:讀到已提交的數據,普通數據庫是可接收的,是以事務隔離級別普通設為Read Committed。Mysql InnoDB經由過程Next-Key Lock算法防止弗成反復讀,默許隔離級別為Repeatable Read。
mysql innodb中的事務
事務的四個特征:原子性、分歧性、隔離性、耐久性
隔離性經由過程鎖完成,原子性、分歧性、耐久性經由過程數據庫的redo和undo來完成。
重做日記記載了事務的行動,經由過程redo完成,包管了事務的完全性,但事務有時還須要撤消,這時候就須要發生undo。undo和redo正好相反,關於數據庫停止修正時,數據庫不只會發生redo,並且還會發生必定的undo,即便履行的事務或語句因為某種緣由掉敗了,或許假如用一條rollback語句要求回滾,便可以用這些undo信息將數據回滾到修正之前的模樣。與redo分歧的是,redo寄存在重做日記文件中,undo寄存在數據庫外部的一個特別段(segment)中,這稱為undo段(undo segment),undo段位於同享表空間內。還有一點主要的是,undo記載的是與事務操作相反的邏輯操作,如insert undo 記載一個delete,所以undo只是邏輯地將數據庫恢復成事務開端前的模樣。如:insert 10萬行的數據,能夠招致表空間增年夜,回滾後,表空間不會減小歸去。