小小程序猿SQL Server認知的成長
1.沒畢業或工作沒多久,只知道有數據庫、SQL這麼個東東,渾然分不清SQL和Sql Server Oracle、MySql的關系,通常認為SQL就是SQL Server
2.工作好幾年了,也寫過不少SQL,卻渾然不知道索引為何物,只知道數據庫有索引這麼個東西,分不清聚集索引和非聚集索引,只知道查詢慢了建個索引查詢就快了,到頭來索引也建了不少,查詢也確實快了,偶然問之:汝建之索引為何類型?答曰:。。。
3.終於受到刺激開始奮發圖強,買書,gg查資料終於知道原來索引分為聚集索引和非聚集索引,頓時淚流滿面,嗚呼哀哉,吾終知索引為何物也。
4.再進一步學習之亦知聚集索引為物理索引、非聚集索引為邏輯索引,聚集索引為數據的存儲順序,非聚集索引是邏輯索引既對聚集索引的索引
5.再往後學會了查看執行計劃,通過查詢計劃終於對查詢過程有了大概了解,也知道了聚集索引掃描和表掃描沒有用到索引,看到聚集索引、索引查找高興的眉飛色舞,看到RID、鍵查找暗自竊喜,瞧,鍵查找肯定就是關鍵字查找了,用著索引呢,效率肯定高,於是每次寫完sql都要觀看下其執行計劃,表掃描的干貨統統不要,俺只要索引查找、鍵查找。
6.自信滿滿的過著悠哉的小日子,突然有一天迷茫了,為嘛俺明明在這個字段上建立了索引,它她妹的老給我顯示聚集索引掃描的,難道查詢優化器發燒了,實際執行下,發現實際的執行計劃還是表掃描,這下徹底迷惑了,興許是查詢優化器顯示的有問題吧。
7.繼續深入學習終發現,數據庫這潭水太深了,了解的太片面了,想想從猿到人的進化過程吧,恩恩,現在就是一個靈智初開的程序猿,向著偉大的程序員奮勇前進
恩恩,跑題了,進入我們的主題:數據庫的書簽查找
認識書簽查找
書簽查找這個詞可能對於很多開發人員比較陌生,很多人都遇到過,但是卻沒引起足夠的重視以至於一直都忽略它的存在了
定義:當查詢優化器使用非聚集索引進行查找時,如果所選擇的列或查詢條件中的列只部分包含在使用的非聚集索引和聚集索引中時,就需要一個查找(lookup)來檢索其他字段來滿足請求。對一個有聚簇索引的表來說是一個鍵查找(key lookup),對一個堆表來說是一個RID查找(RID lookup),這種查找即是——書簽查找(bookmark lookup)。簡單的說就是當你使用的sql查詢條件和select返回的列沒有完全包含在索引列中時就會發生書簽查找。
書簽查找的重要性
1.書簽查找發生條件:只有在使用非聚集索引進行數據查找時才會產生書簽查找,聚集索引查找、聚集索引掃描和表掃描不會發生書簽查找。
2.書簽查找發生頻率:書簽查找發生頻率非常高,甚至可以說大部分查詢都會發生書簽查找,我們知道一個表只能建立一個聚集索引,所以我們的查詢更多的會使用非聚集索引,非聚集索引不可能覆蓋所有的查詢列,所以會經常性產生書簽查找。
3.書簽查找的影響:導致索引失效的主要原因之一。書簽查找根據索引的行定位器從表中讀取數據,除了索引頁面的邏輯讀取外,還需要數據頁面的邏輯讀取,如果查詢的結果返回數據量較大會導致大量的邏輯讀或者索引失效,這也是為什麼我們查看查詢計劃時有時明明在查詢列上建立了索引,查詢優化器卻依然使用表掃描的原因。
4.如何消除書簽查找:
1.使用聚集索引查找,聚集索引的葉子節點就是數據行本身,因此不存在書簽查找
2.聚集索引掃描、表掃描,說白了就是啥索引都不建直接全表掃描,肯定不會發生書簽查找,不過效率嗎。。。
3.使用非聚集索引的鍵列包含所有查詢或返回的列,這個不靠譜,非聚集索引最大鍵列數為16,最大索引鍵大小為900字節,就算你有勇氣在16列上全部建立索引,那如果表的列數超過16列了你咋辦,還有索引列長度之和不能超過900字節,所以不可能讓非聚集索引包含所有列,而且索引涉及到得列越多維護索引的開銷也就越大。
4.使用include,嗯,這是個好東東,索引做到只能包含16列且不能超過900字節,include不受此限制,最多可以包含1023列怎麼也夠你用了,而且對長度也沒有限制你可以隨心所欲的包含nvarchar(max)這也的列,當然了text之流就不要考慮了
5.其它,其它還有神馬呢,這個我也不知道了,估計應該、可能、大概木有了吧,若有知道的兄弟可以告訴我聲哈
可能上面說的有點抽象,我們開看看具體的例子
一般我們的數據庫都會建上聚集索引(一般大家喜歡建表時有用沒有肯定先來個自增ID列當主鍵,這個主鍵SQL Server默認就給你創建成聚集索引了),故我們這裡都假設表上已經建立了聚集索引,不考慮堆表(就是沒有聚集索引的表)
1.首先創建表Users、插入一些示例數據並建立聚集索引PK_UserID 非聚集索引IX_UserName
復制代碼 代碼如下:
--懶得的肥兔 --創建表Users
Create table Users
(
UserID int identity,
UserName nvarchar(50),
Age int,
Gender bit,
CreateTime datetime
)
--在UserID列創建聚集索引PK_UserID
create unique clustered index PK_UserID on Users(UserID)
--在UserName創建非聚集索引IX_UserName
create index IX_UserName on Users(UserName)
--插入示例數據
insert into Users(UserName,Age,Gender,CreateTime)
select N'Bob',20,1,'2012-5-1'
union all
select N'Jack',23,0,'2012-5-2'
union all
select N'Robert',28,1,'2012-5-3'
union all
select N'Janet',40,0,'2012-5-9'
union all
select N'Michael',22,1,'2012-5-2'
union all
select N'Laura',16,1,'2012-5-1'
union all
select N'Anne',36,1,'2012-5-7'
2.執行以下查詢並查看查詢計劃,可以看到第一個SQL執行聚集索引掃描,第二個SQL執行聚集索引查找都沒有使用到書簽查找
復制代碼 代碼如下:
select * from Users
select * from Users where UserID=4

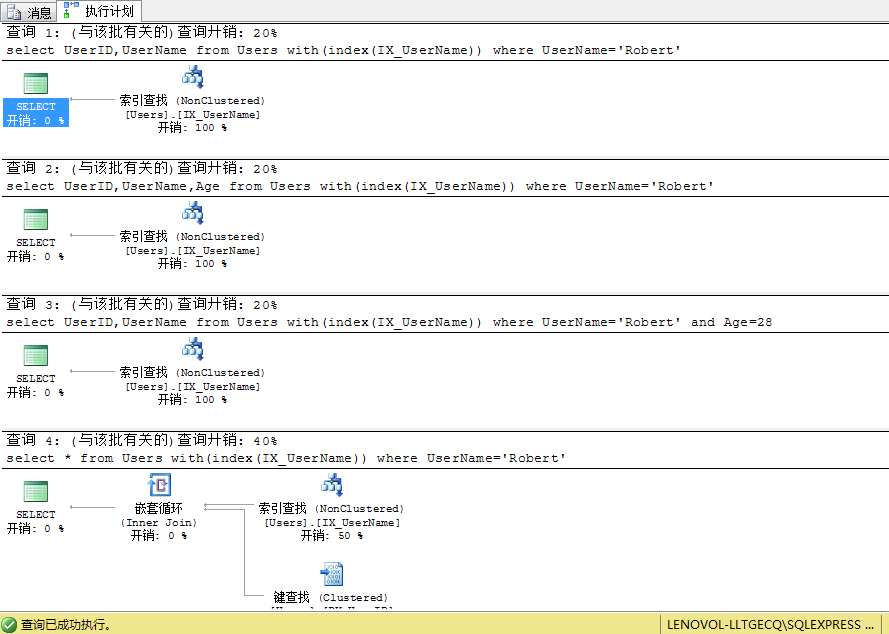
3.比較以下幾個查詢SQL,觀察其查詢計劃,思考下為什麼會發生書簽查找
復制代碼 代碼如下:
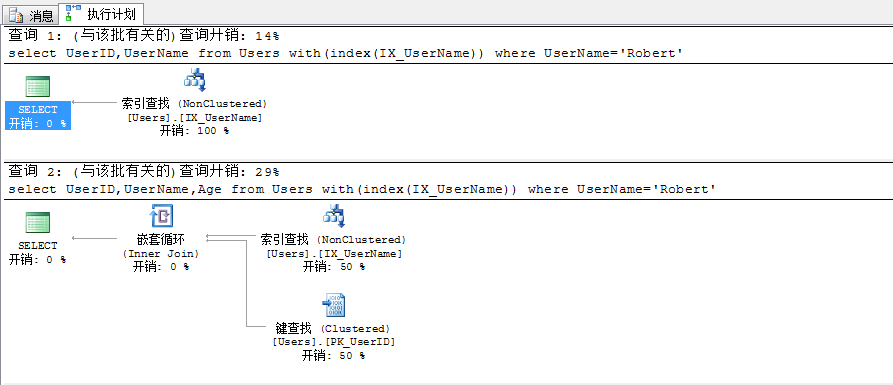
--查詢1:使用索引IX_UserName,選擇列UserID,UserName,查詢條件列為UserName
select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert'
--查詢2:使用索引IX_UserName,選擇列UserID,UserName,Age,查詢條件列為UserName
select UserID,UserName,Age from Users with(index(IX_UserName)) where UserName='Robert'
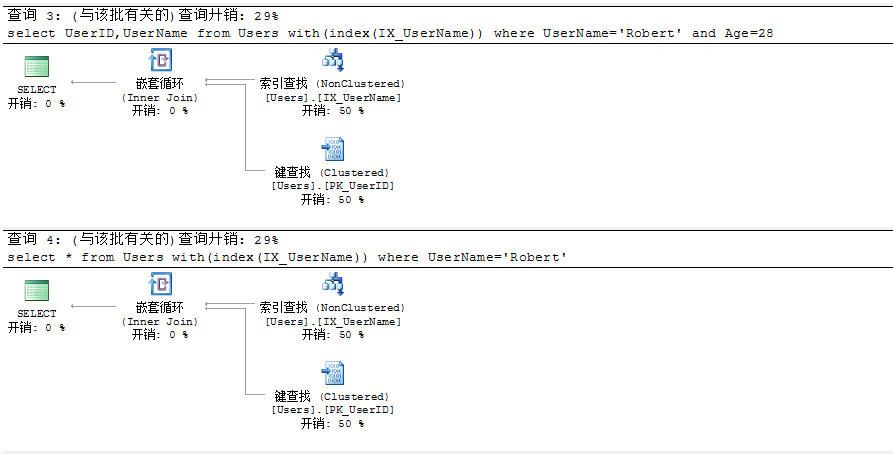
--查詢3:使用索引IX_UserName,選擇列UserID,UserName,查詢條件列為UserName,Age
select UserID,UserName from Users with(index(IX_UserName)) where UserName='Robert' and Age=28
--查詢4:使用索引IX_UserName,選擇列所有列,查詢條件列為UserName
select * from Users with(index(IX_UserName)) where UserName='Robert'
分析:
查詢1:選擇的列UserID是聚集索引PK_UserID的鍵列,UserName為索引IX_UserName的鍵列,查詢條件列為UserName,由於索引IX_UserName包含了查詢用到得所有列,所以僅需要掃描索引即可返回查詢結果,不需要再額外的去數據頁獲取數據,故不會發生書簽查找
查詢2:選擇列Age不包含在聚集索引PK_UserID和IX_UserName中,故需要進行額外的書簽查找
查詢3:查詢條件Age列不包含在聚集索引PK_UserID和IX_UserName中,故需要進行額外的書簽查找
查詢4:包含了所有的列,Age、Gender、CreateTime列均不在聚集索引PK_UserID和IX_UserName中,所以需要書簽查找以定位數據
這裡解釋下:查詢中用到的列無論是一列還是多列不在索引覆蓋范圍查詢開銷基本上一樣,每條記錄均只需要一次書簽查找開銷,不會說因為查詢3只有一個Age列,查詢4有Age、Gender、CreateTime 3列不在索引覆蓋范圍而導致額外的開銷
分析:
查詢1:選擇的列UserID是聚集索引PK_UserID的鍵列,UserName為索引IX_UserName的鍵列,查詢條件列為UserName,由於索引IX_UserName包含了查詢用到得所有列,所以僅需要掃描索引即可返回查詢結果,不需要再額外的去數據頁獲取數據,故不會發生書簽查找
查詢2:選擇列Age不包含在聚集索引PK_UserID和IX_UserName中,故需要進行額外的書簽查找
查詢3:查詢條件Age列不包含在聚集索引PK_UserID和IX_UserName中,故需要進行額外的書簽查找
查詢4:包含了所有的列,Age、Gender、CreateTime列均不在聚集索引PK_UserID和IX_UserName中,所以需要書簽查找以定位數據
這裡解釋下:查詢中用到的列無論是一列還是多列不在索引覆蓋范圍查詢開銷基本上一樣,每條記錄均只需要一次書簽查找開銷,不會說因為查詢3只有一個Age列,查詢4有Age、Gender、CreateTime 3列不在索引覆蓋范圍而導致額外的開銷
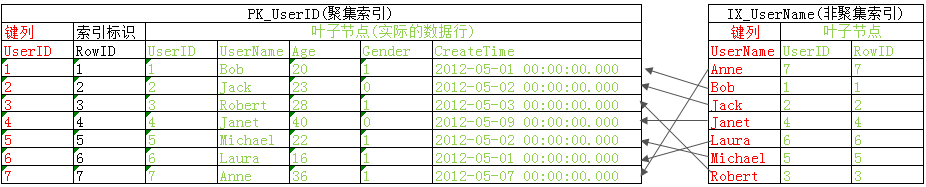
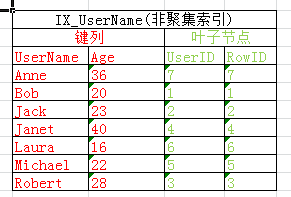
和許多人一樣看到大神們畫的二叉樹索引結構圖就腦袋大,看得雲裡霧裡,所以這裡我們以表Users為例來說聚集索引(PK_UserID)和非聚集索引(IX_UserName)的結構可以簡單的表示為下圖
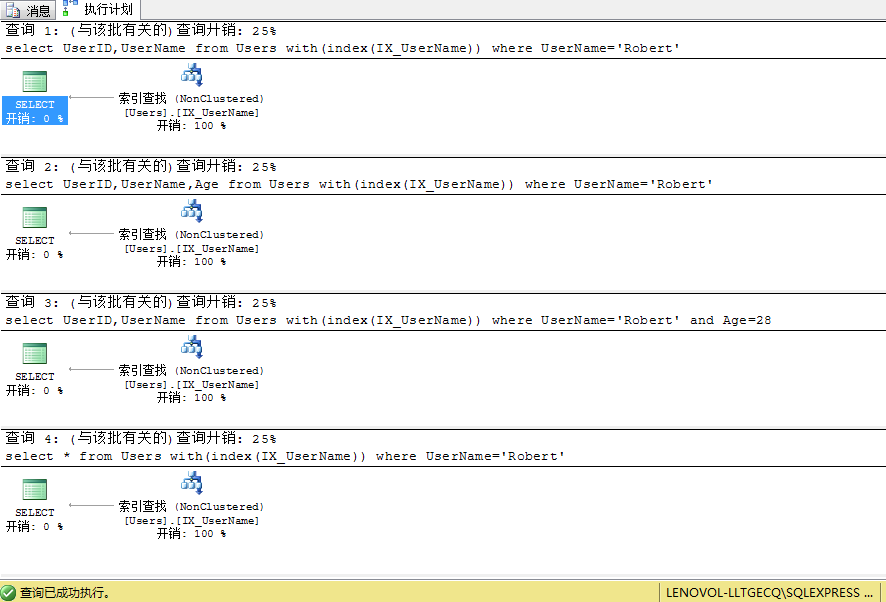
我們可以看到查詢2、查詢3的書簽查找已經消失,因為索引IX_UserName包含了查詢中用到得所有列(UserID,UserName,Age),查詢4因為選擇返回所有列我們的索引沒有包含Gender和CreateTime列,故還是會進行書簽查找
這時索引IX_UserName結構表示如下
可見對於查詢2、查詢3僅僅通過索引IX_UserName既可以拿到需要的列UserName,Age,UserID,而對於查詢4索引並沒有全部覆蓋還是需要進行書簽查找
可以看到我們修改索引使用include包含了Gender,CreateTime後,索引IX_UserName達到了對數據表Users的所有列的全覆蓋,這時候毫無疑問的查詢2、查詢3沒有出現書簽查找,查詢4的書簽查找也消失了。
此時索引IX_UserName 結構如下
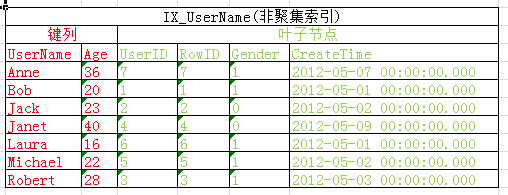
索引IX_UserName已經達到了對Users表的全覆蓋,對於我們的查詢2、查詢3、查詢4來說,僅通過索引IX_UserName即可完成查詢,不需要進行書簽查找。
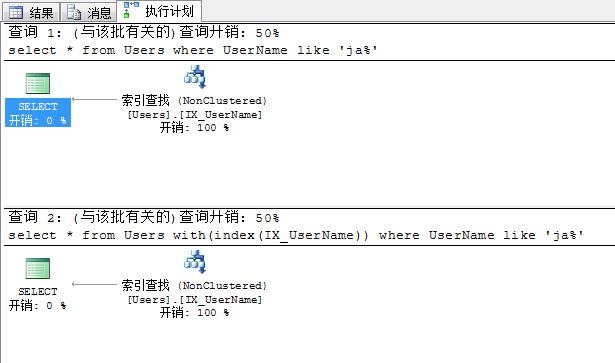
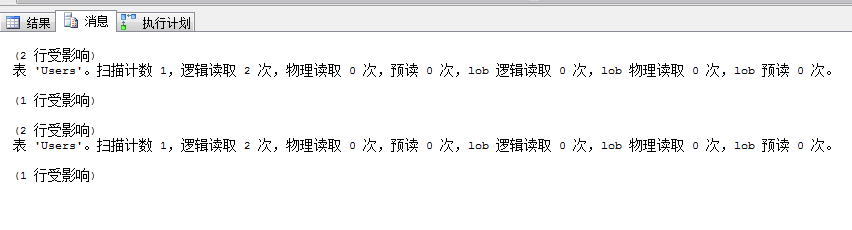
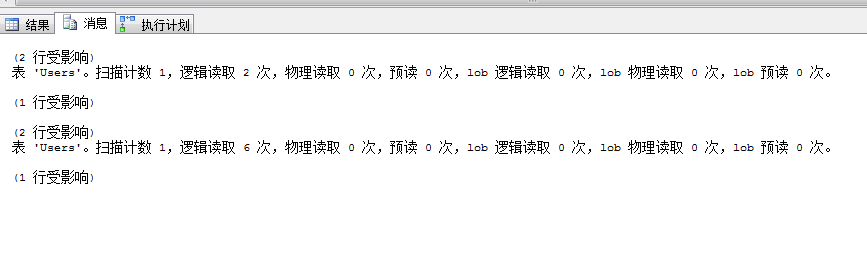
這時我們再來看一下這兩個查詢的開銷及查詢計劃,可以看到不需要我們進行索引提示,查詢優化器已經自動選擇了我們的索引,邏輯讀也降至了2次
select * from Users where UserName like 'ja%'select * from Users with(index(IX_UserName)) where UserName like 'ja%'