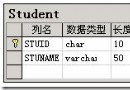
最近做某項目的數據庫分析,要實現對海量數據的導入問題,就是最多把200萬條數據一次導入sqlserver中,如果使用普通的insert語句進行寫出的話,恐怕沒個把小時完不成任務,先是考慮使用bcp,但這是基於命令行的,對用戶來說友好性太差,實際不大可能使用;最後決定使用BULK INSERT語句實現,BULK INSERT也可以實現大數據量的導入,而且可以通過編程實現,界面可以做的非常友好,它的速度也很高:導入100萬條數據不到20秒中,在速度上恐怕無出其右者。
但是使用這種方式也有它的幾個缺點:
1.需要獨占接受數據的表
2.會產生大量的日志
3.從中取數據的文件有格式限制
但相對於它的速度來說,這些缺點都是可以克服的,而且你如果願意犧牲一點速度的話,還可以做更精確的控制,甚至可以控制每一行的插入。
對與產生占用大量空間的日志的情況,我們可以采取在導入前動態更改數據庫的日志方式為大容量日志記錄恢復模式,這樣就不會記錄日志了,導入結束後再恢復原來的數據庫日志記錄方式。
具體的一個語句我們可以這樣寫:
代碼如下:
alter database taxi
set RECOVERY BULK_LOGGED
BULK INSERT taxi..detail FROM 'e:\out.txt'
WITH (
DATAFILETYPE = 'char',
FIELDTERMINATOR = ',',
ROWTERMINATOR = '\n',
TABLOCK
)
alter database taxi
set RECOVERY FULL
這個語句將從e:\out.txt導出數據文件到數據庫taxi的detail表中。