序言
企業級應用系統軟件通常有著對並發數和響應時間的要求,這就要求大量的用戶能在高響應時間內完成業務操作。這兩個性能指標往往決定著一個應用系統軟件能否成功上線,而這也決定了一個項目最終能否驗收成功,能否得到客戶認同,能否繼續在一個行業發展壯大下去。由此可見性能對於一個應用系統的重要性,當然這似乎也成了軟件行業的不可言說的痛 —— 絕大多數的應用系統在上線之前,項目組成員都要經歷一個脫胎換骨的過程。
生產環境的建立包含眾多方面,如存儲規劃、操作系統參數調整、數據庫調優、應用系統調優等等。這幾方面互相影響,只有經過不斷的調整優化,才能達到資源的最大利用率,滿足客戶對系統吞吐量和響應時間的要求。在無數次的實踐經驗中,很多軟件專家能夠達成一致的是:應用系統本身的優化是至關重要的,否則即使有再大的內存,也會被消耗殆盡,尤其是產生 OOM(Out Of Memory)的錯誤的時候,它會貪婪地吃掉你的內存空間,直到系統宕機。
內存洩露 — 難啃的骨頭
產生 OOM 的原因有很多種,大體上可以簡單地分為兩種情況,一種就是物理內存確實有限,發生這種情況時,我們很容易找到原因,但是它一般不會發生在實際的生產環境中。因為生產環境往往有足以滿足應用系統要求的配置,這在項目最初就是根據系統要求進行購置的。
另外一種引起 OOM 的原因就是應用系統本身對資源的的不恰當使用、配置,引起內存使用持續增加,最終導致 JVM Heap Memory 被耗盡,如沒有正確釋放 JDBC 的 Connection Pool 中的對象,使用 Cache 時沒有限制 Cache 的大小等等。本文並不針對各種情況做討論,而是以一個項目案例為背景,探索解決這類問題的方式方法,並總結一些最佳實踐,供廣大開發工程師借鑒參考。
項目背景介紹
項目背景:
內網用戶 500 人,需要同時在線進行業務操作(中午休息一小時,晚 6 點下班)。
生產環境采用傳統的主從式,未做 Cluster ,提供 HA 高可用性。
服務器為 AIX P570,8U,16G,但是只有一半的資源,即 4U,8G 供新系統使用。
項目三月初上線,此前筆者與架構師曾去客戶現場簡單部署過一兩次,主要是軟件的安裝,應用的部署,測一下應用是不是能夠跑起來,算作是上線前的准備工作。應用上線(試運行)當天,項目組全體入住客戶現場,看著用戶登錄數不斷攀升,大家心裡都沒有底,高峰時候到了 440,系統開始有點反應變慢,不過還是扛下來了,最後歸結為目前的資源有限,等把另一半資源劃過來,就肯定沒問題了。(須知增加資源,調優的工作大部分都要重新做一遍,系統級、數據庫級等等,這也是後面為什麼建議如果資源可用,最好一步到位的原因。)為了臨時解決資源有限的問題,通過和客戶協商,決定中午 12 點半和晚上 11 點通過系統調度重啟一次應用服務器,這樣,就達到了相隔幾個小時,手動清理內存的目的。
項目在試運行階段,仍舊有新的子應用開始投入聯調,同時客戶每天都會提出這樣那樣的需求變更,如果要的很急的話,就要隨時修改,隔天修正使用。修改後沒有充分的時間進行回歸測試,新部署的代碼難免會有這樣那樣的問題,遇到過幾次這種情況,最後不得不在業務系統使用的時候,對應用系統進行重新啟動,於是就會出現業務終止引起的數據不一致,還要對這些數據進行修正維護,加大了工作量。期間,應用在運行過程中有幾次異常緩慢的情形,由於業務不能中斷太久,需要迅速恢復系統投入使用,所以往往是重啟一下應用服務器來釋放內存。事後檢查日志,才發現日志中赫然記錄有 OOM 的錯誤,這才引起了項目經理的注意,要求架構師對該問題進行進一步研究確認。
但是幾個月過去,問題依舊出現,於是通過客戶和公司的協調,請來幾位專家,包括操作系統專家、數據庫專家,大部分的專家在巡檢之後,給出的結論是:大部分需要調整的參數都已經調整過了,還是要從應用系統本身找原因,看來還是要靠我們自己來解決了。(最終的結果也證明,如此詭異隱蔽的 OOM 問題是很難一眼就能發現的,工具的作用不可忽視。)
我們通過對底層封裝的框架代碼,主要是 DAO 層與數據庫交互的統一接口,增加了 log 處理以抓取所有執行時間超過 10 秒鐘的 SQL 語句,記錄到應用系統日志中備查。同時通過數據庫監控輔助工具給出的建議,對所有超標的 SQL 通過建立 index,或者修正數據結構(主要是通過建立冗余字段來避免多表關聯查詢)來進行優化。這樣過了幾天後,已經基本上不存在執行時間超過 10 秒的 SQL 語句,可以說我們對應用層的優化已經達標了。
但是,宕機的問題並沒有徹底解決,陸續發生了幾次,通過短暫的控制台監控,發現都有線程等待的現象發生,還有兩三次產生了幾個 G 大小的 heapdump 文件,同時伴隨有 javacore 文件產生。因為每次宕機的時候都需要緊急處理,不允許長時間監控,只能保留應用服務器日志和產生的 heapdump 文件,做進一步的研究。通過日志檢查,我們發現幾次宕機時都發生在相同的某兩個業務點上,但是多次對處理該業務功能的代碼進行檢查分析,仍舊沒有找到原因。看來只能寄希望於宕機產生的 heapdump 和 javacore 了,於是開始重點對 OOM 產生的這些文件進行分析。
IBM 分析工具的使用
這裡,我們簡單介紹一下 heapdump 文件和 javacore 文件。heapdump 文件是一種鏡像文件,是指定時刻的 Java 堆棧的快照。應用程序在發生內存洩露的錯誤時,往往會生成 heapdump 文件,同時伴隨有 javacore 文件生成,javacore 包含 JVM 和應用程序相關的在特定時刻的一些診斷信息,如操作系統,內存,應用程序環境,線程等的信息。如本文案例中分析的下圖中的 heapdump.20090602.134015.430370.phd 和 javacore.20090602.134015.430370.txt。
由於筆者之前並沒有這方面的分析經驗,覺得 heapdump 文件很大,就想當然拿它開刀了。首先是尋找工具,類似的工具有多種,筆者最後選擇了 IBM 的 HeapAnalyzer(http://www.alphaworks.ibm.com/tech/heapanalyzer)。通過對 heapdump 文件的解析,HeapAnalyzer 可以分析出哪些對象占用了太多的堆棧空間,從而發現導致內存洩露或者可能引起內存洩露的對象。它的使用很簡單,可以從它的 readme 文檔中找到,這裡我們簡單舉個例子如下:
#/usr/java50/bin/java – Xmx2000m – jar ha36.jar heapdump.20090602.134015.430370.phd
通常我們需要使用較大的 heapsize 來啟動 HeapAnalyzer,因為通過 HeapAnalyzer 打開過大的 heapdump 文件時,也可能會因為 heapsize 不夠而產生 OOM 的錯誤。開始的時候,筆者從服務器上將 heapdump 文件通過 ftp 下載下來,然後試圖通過本機 window 環境進行分析。筆者使用的電腦是 2G 內存,啟動 HeapAnalyzer 時指定的是 1536 M,但是幾次都是到 90% 多的時候進度條就停止前進了。迫不得已同時也是為了能達到環境一致的效果,筆者將 HeapAnalyzer 上傳到生產環境,直接在生產環境下打開 heapdump 文件。
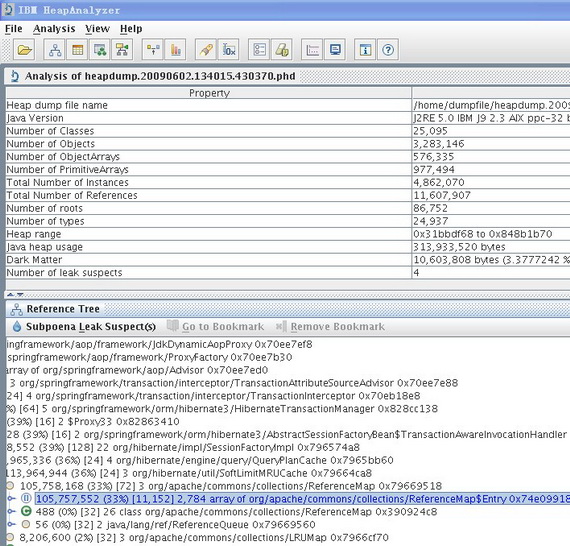
個人感覺 HeapAnalyzer 給出的分析結果可讀性不強,而且不能准確定位問題,從分析結果看大致是因為加載的對象過多,但是是哪個模塊導致的問題就跟蹤不到了。筆者開始尋找 HeapAnalyzer 分析結果相關的資料,試圖從這個可讀性不強的結果中找到蛛絲馬跡,可是許久沒有進展,再一次陷入了困境。
在多次研究 heapdump 文件無果的情況下,筆者開始逐漸將注意力轉移到 javacore 文件上,雖然它比較小,說不定內藏玄機呢。通過多方搜尋,找到了 IBM Thread and Monitor Dump Analyzer for Java(以下簡稱 jca)—— A tool that allows identification of hangs, deadlocks, resource contention, and bottlenecks in Java threads。通過它自身的這段描述來看,這正是筆者所需要的好工具。
這個工具的使用和 HeapAnalyzer 一樣,非常容易,同樣提供了詳細的 readme 文檔,這裡也簡單舉例如下:
#/usr/java50/bin/java -Xmx1000m -jar jca37.jar
圖 2. 通過 xManager 工具登錄到 AIX 服務器上打開 jca 的效果圖
筆者直接在生產環境下直接通過它對產生的 javacore 文件進行分析,令人驚喜的是,其分析結果非常明了,筆者心頭的疑雲在對結果進行進一步分析核實後也漸漸散去。
圖 3. jca 對 javacore.20090602.134015.430370.txt 的分析結果 —— 第一部分
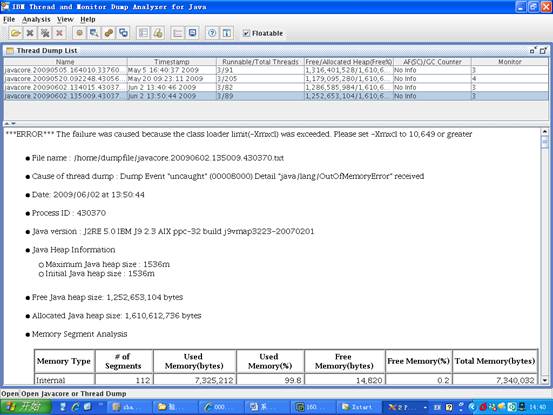
從圖中,我們可以清楚地看到引發錯誤的原因 —— The failure was caused because the class loader limit was exceeded。同時我們還能看出當前生產環境使用的 JRE 版本是:J2RE 5.0 IBM J9 2.3 AIX ppc-32 build j9vmap3223-20070201 ,這個 SR4 的版本有個問題,我們可以從分析結果圖的第二部分的 NOTE 小節清楚地看到:
圖 4. jca 對 javacore.20090602.134015.430370.txt 的分析結果 —— 第二部分
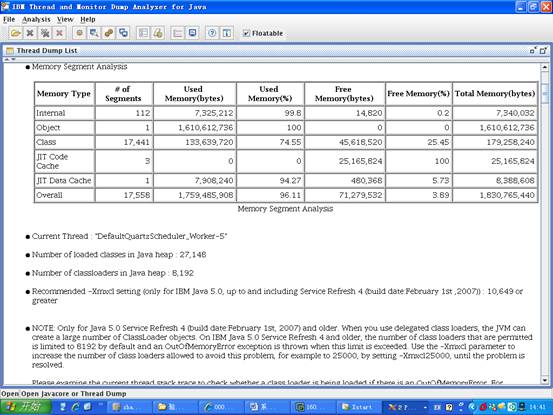
NOTE: Only for Java 5.0 Service Refresh 4 (build date:February 1st, 2007) and older. When you use delegated class loaders, the JVM can create a large number of ClassLoader objects. On IBM Java 5.0 Service Refresh 4 and older, the number of class loaders that are permitted is limited to 8192 by default and an OutOfMemoryError exception is thrown when this limit is exceeded. Use the -Xmxcl parameter to increase the number of class loaders allowed to avoid this problem, for example to 25000, by setting -Xmxcl25000, until the problem is resolved.
原來,OOM 竟然是因為這個原因產生的。那麼到底是哪裡加載的對象超過了這個 8192 的限制呢?接下來筆者結合分析結果和應用系統 log 進行了進一步的分析,更加驗證了 JCA 分析結果的正確性。
在分析結果中可以看到 Current Thread ,就是對應引起 OOM 的應用服務器的線程,使用該線程的名稱作為關鍵字在我們的 log 裡進行搜索,迅速定位到了業務點——這是一個定時的調度,其功能是按固定時間間隔以 DBLink 的方式從外部應用的數據庫系統中抽取數據,通過應用層邏輯轉換後保存到內網數據庫系統中。應用層的邏輯是對所有的業務數據進行循環,對每條業務數據進行到 POJO 的一一對照轉換,這意味這一條業務數據需要 10 幾個 POJO 進行組合對照,也就是說,如果外網在指定的時間間隔內數據量稍大,就會加載大量的對象,使 JVM 的 class loaders 瞬間超過 8192 的限制,而產生 OOM 的錯誤,從而使內存不斷被消耗,直至宕機。
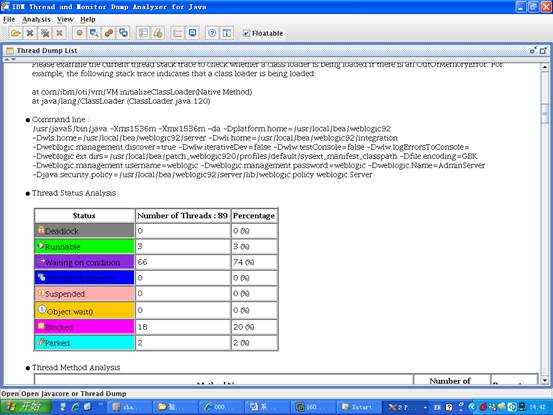
jca 還提供了對垃圾回收和線程狀態的詳細分析數據,可以參考如下兩圖:
圖 5. jca 對垃圾回收狀態的分析數據
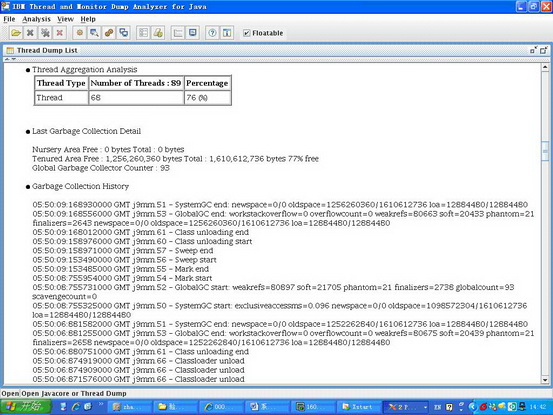
圖 6. jca 對垃圾線程狀態的分析數據
問題核實後,如何進行解決呢?分析結果中也給出了相應的建議,從圖 4 的 Recommended 小節我們可以看到:
Recommended -Xmxcl setting (only for IBM Java 5.0, up to and including Service Refresh 4 (build date:February 1st ,2007)) : 10,649 or greater。
為了考慮到對既有舊系統不產生影響,我們沒有對 JRE 進行升級,而是采用了分析結果給出的建議,在應用服務器啟動後設置 -Xmxcl 參數為 25000,為驗證我們的修改是不是成功解決掉了 OOM 宕機的問題,筆者取消了對應用服務器的自動重啟調度,通過一段時間的監控發現,系統運行良好,一直沒有再出現 OOM 而宕機的問題,問題得以最終解決。
總結
整體規劃
系統上線前要做好充分的准備工作,這一點很重要,上線計劃可不是拍拍腦門就能想出來的,需要很多項目成員的參與。
項目實施計劃書:要包括預計實施目標,雙方的實施負責人(包括 backup),協調哪些資源應該找哪些人,詳細的階段性計劃等等。
實施小組:指定具有實施經驗的架構師,系統工程師,開發組長組成實施小組,負責生產環境的搭建及調整。成員構成上一定要包含項目組內的穩定核心人員,以保證能在特殊情況需要時做 backup。核心人員的流動會引起項目風險,尤其是在上線初期的不穩定階段。
對可規劃使用的資源一定要充分利用,這一點應包含在項目實施計劃書內,盡量做到資源一步到位。因為本項目案例中,舊有系統和新系統並行運行,可用的資源在不斷發生變化,期間為解決性能問題,曾嘗試將資源分配向新系統傾斜,以嘗試是否能解決問題,這在一定程度上也會影響實施的進度。
需要對核心的配置進行確認,如 JRE 版本,數據庫版本等。如果我們在生產環境建立的初期,就把 JRE 升級到最新的版本,可能就避免了這次 6 個月宕機的煎熬。
壓力測試
大部分具有並發需求的應用系統上線前,都要經過開發團隊的壓力測試,這樣在試運行階段才能心裡有底。本項目案例中,由於工期過於緊張,加之其他因素,導致壓力測試不夠充分,雖然 OOM 的問題並不是因為並發數過多產生,但是這一環節是不可忽視的。
攻堅團隊
一個擁有高度的執行力的團隊一定是一個責任分明的團隊。在應對突發、嚴重、緊急情況時,要有專門的攻堅團隊來解決這類問題,這個團隊應該包括項目組的核心開發人員,有較強的動手能力和研究能力,能夠變通解決問題,思路開闊。他們的作用是至關重要的,往往可能決定項目的成敗。
信心很重要
每一次攻堅內存洩露的問題都是一次探險之旅,需要有清醒的意識和頭腦,更要凝結你的意志和信心,因為這是一個艱苦的過程。本文案例由發生至解決有半年之久,當筆者轉向分析 javacore 文件後,迅速定位了問題,終於柳暗花明,這種喜悅是難以言表的。
紙上得來終覺淺, 絕知此事要躬行。
這一條不多說了,有所行,才有所得。