了解 Groovy 的並發庫如何利用流行的並發模型並使其在 Java 平台上可供訪問
在並發性時代,帶有 4、6 和 16 個處理器核心的芯片變得很普遍,而且在不久的將來,我們會看到帶有上百甚至上千個核心的芯片。這種處理能力蘊含著巨大的可能性,但對於軟件開發人員來說,它也帶來了挑戰。最大限度地利用這些閃耀新核的需求推動了對並發性、狀態管理和為兩者構建的編程語言的關注熱潮。
Groovy、Scala 和 Clojure 等 JVM 語言滿足了這些需求。這三種都是較新的語言,運行於高度優化的 JVM 之上,可以使用 Java 1.5 中新增的強大的 Java 並發庫。盡管每種語言基於其原理采用不同的方法,不過它們都積極支持並發編程。
在本文中,我們將使用 GPars,一種基於 Groovy 的並發庫,來檢查模型以便解決並發性問題,比如後台處理、並行處理、狀態管理和線程協調。
為何選擇 Groovy ?為何選擇 GPars ?
Groovy 是運行於 JVM 之上的一種動態語言。基於 Java 語言,Groovy 移除了 Java 代碼中的大量正式語法,並添加了來自其他編程語言的有用特性。Groovy 的強大特性之一是它允許編程人員輕松創建基於 Groovy 的 DSL。
GPars 或 Groovy Parallel Systems 是一種 Groovy 並發庫,捕捉並發性和協調模型作為 DSL。GPars 的構思源自其他語言的一些最受歡迎的並發性和協調模型,包括:
來自 Java 語言的 executors 和 fork/join
來自 Erlang 和 Scala 的 actors
來自 Clojure 的 agents
來自 Oz 的數據流變量
Groovy 和 GPars 的結合成為展示各種並發性方法的理想之選。甚至不熟悉 Groovy 的 Java 開發人員也能輕松關注相關討論,因為 Groovy 的語法以 Java 語言為基礎。本文中的示例基於 Groovy 1.7 和 GPars 0.10。
後台和並行處理
一個常見的性能難題是需要等待 I/O。I/O 可能涉及到從一個磁盤、一個 web 服務或甚至是一名用戶讀取數據。當一個線程在等待 I/O 的過程中被阻止時,將等待中的線程與原始執行線程分離開來將會很有用,這將使它能繼續工作。由於這種等待是在後台發生的,所以我們稱這種技術為 後台處理。
例如,假設我們需要這樣一個程序,即調用 Twitter API 來找到針對若干 JVM 語言的最新 tweets 並將它們打印出來。Groovy 能夠使用 Java 庫 twitter4j 很容易就編寫出這樣的程序,如清單 1 所示:
清單 1. 串行讀取 tweets (langTweets.groovy)
import twitter4j.Twitter
import twitter4j.Query
@Grab(group='net.homeip.yusuke', module='twitter4j', version='2.0.10')
def recentTweets(api, queryStr) {
query = new Query(queryStr)
query.rpp = 5 // tweets to return
query.lang = "en" // language
tweets = api.search(query).tweets
threadName = Thread.currentThread().name
tweets.collect {
"[${threadName}-${queryStr}] @${it.fromUser}: ${it.text}"
}
}
def api = new Twitter()
['#erlang','#scala','#clojure'].each {
tweets = recentTweets(api, it)
tweets.each {
println "${it}"
}
}
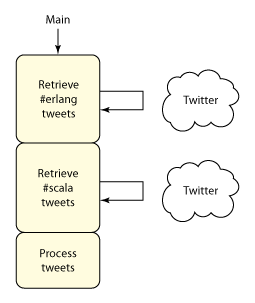
在 清單 1中,我首先使用了 Groovy Grape來捕獲 twitter4j 庫依賴性。然後定義了一個 recentTweets方法來接受查詢字符串並執行該查詢,返回一列格式化為字符串的 tweets。最後,我遍歷了標記列表中的每個標記,獲取了 tweets 並將它們打印出來。由於未使用線程,該代碼串行執行每個搜索,如圖 1 所示:
圖 1. 串行讀取 tweets
並行處理
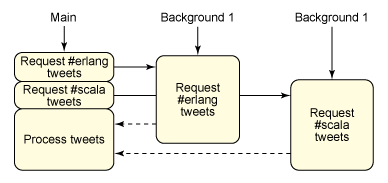
如果 清單 1中的程序靜候等待,它也可能不止等待一個處理。如果我將每個遠程請求放入一個後台線程中,程序會並行等待每個響應查詢,如圖 2 所示:
圖 2. 並行讀取 tweets
GPars Executors DSL 使得我們更容易將 清單 1中的程序從串行處理轉換為並行處理,如清單 2 所示:
清單 2. 並行讀取 tweets (langTweetsParallel.groovy)
import twitter4j.Twitter
import twitter4j.Query
import groovyx.gpars.GParsExecutorsPool
@Grab(group='net.homeip.yusuke', module='twitter4j', version='2.0.10')
@Grab(group='org.codehaus.gpars', module='gpars', version='0.10')
def recentTweets(api, queryStr) {
query = new Query(queryStr)
query.rpp = 5 // tweets to return
query.lang = "en" // language
tweets = api.search(query).tweets
threadName = Thread.currentThread().name
tweets.collect {
"[${threadName}-${queryStr}] @${it.fromUser}: ${it.text}"
}
}
def api = new Twitter()
GParsExecutorsPool.withPool {
def retrieveTweets = { query ->
tweets = recentTweets(api, query)
tweets.each {
println "${it}"
}
}
['#erlang','#scala','#clojure'].each {
retrieveTweets.callAsync(it)
}
}
我使用 Executors DSL 為 GParsExecutorsPool添加了一段 import語句,並使用 Groovy Grape 依賴性系統添加了一段 Grab語句來捕獲 GPars 庫。然後我引入了一個 GParsExecutorsPool.withPool塊,這將增強塊中的代碼以添加額外功能。在 Groovy 中,可以使用 call方法來調用閉包。GParsExecutorsPool將在底層內存池中作為任務執行通過 call 方法調用的閉包。此外,GParsExecutorsPool通過一個 callAsync方法增強閉包,被調用後該方法在無阻塞的情況下立即返回。在本例中,我包裝了我的 tweet 搜索並將操作包裝到一個閉包中,然後為每個查詢異步調用它。
由於 GPars 將這些任務分配給了一批作業員,我現在可以並行執行我的所有搜索了(只要內存池足夠大)。我也可以並行處理每個查詢所得結果,在其到達時打印到屏幕。
該例展示了後台處理能夠提高性能和響應能力的兩種方式:I/O 等待並行完成,依賴於該 I/O 的處理也並行發生。
Executors
您可能想知道什麼是 executor,GParsExecutorsPool中的後台處理如何工作。Executor實際上是 Java 5 中引入的 java.util.concurrent庫的一部分。java.util.concurrent.Executor接口僅有一個方法:execute(Runnable)。它存在的目的在於將任務的提交與一個 Executor實現中任務的實際執行方式分離開來。
java.util.concurrent.Executors類提供許多有用的方法來創建各種不同的線程池類型支持的 Executor實例。GParsExecutorsPool默認使用一個含守護進程線程和固定數目線程的一個線程池(Runtime.getRuntime().availableProcessors() + 1)。當默認設置不合適時,要更改線程池大小、使用一個自定義 ThreadFactory或指定現有的整個 Executor池(withExistingPool)很簡單。
要更改線程數,我可以將 GParsExecutorsPool線程計數傳遞給 withPool方法,如清單 3 所示:
清單 3. 使用線程計數啟動一個 Executor 池
GParsExecutorsPool.withPool(8) {
// ...
}
或者如果我想傳遞一個具有專門命名線程的自定義線程工廠,我可以像清單 4 這樣做。
清單 4. 使用自定義線程工廠啟動一個 Executor 池
def threadCounter = new AtomicLong(0)
def threadFactory = {Runnable runnable ->
Thread thread = new Thread(runnable)
id = threadCounter.getAndIncrement()
thread.setName("thread ${id}")
return thread
} as ThreadFactory
def api = new Twitter()
GParsExecutorsPool.withPool(2, threadFactory) {
// ...
}
async和 callAsync方法不阻止線程並立即返回一個 Future對象來表示異步計算的未來結果。接收者可以要求 Future阻止線程,直至一個結果就緒,檢測查看它是否完成並取消計算指令,或檢查是否有其他進程取消了它。與 Executor接口一樣,Future類是底層 java.util.concurrent包的一部分。
CPU 的並行性
在後台處理示例中,您了解了讓一個程序並行等待多個 I/O 密集型任務(而非串行處理它們)的好處。使用一批作業員來並行執行多個任務對 CPU 密集型任務也大有裨益。
您的應用程序的兩個重要方面影響著它可以接受的並行度,因此您具有的編程選項包括:
任務粒度,即任務在時間或數據上的范圍
任務依賴性,即通常存在於任務之間的依賴關系的數量
兩個方面存在於一個狀態集上,且在制定一個解決方案之前考慮該狀態集上的問題所在是很有用的。例如,一個程序的任務粒度可由大型事務級工作定義,它也可以由大型數據集一小部分(整幅圖像的幾個像素)中的多個簡短的計算指令組成。由於任意工作量的一個線程或進程的上下文切換涉及到的開銷較大,小粒度級的系統往往效率低下且遭遇低性能問題。基於任務粒度的批處理是為您的系統找到最佳性能點的一種方法。
依賴性較少的任務通常被描述為 “高度平行”,即太容易將它們分成多個並行任務了。典型的例子包括圖形處理、強力搜索、分形和粒子模擬。任何處理或轉換大批命令或文件的業務處理程序也可歸入這一類。
Executor 隊列爭用
我們已經探究了如何使用 GPars 將任務推入 Executor池的機理。不過,最好要記住,Executor是在 2005 年某個時候添加到 Java 2 Platform、Standard Edition (J2SE) 的。它們是為相對少數的核心(2 到 8 個)而調優的,這些核心運行粗粒度的、可能會阻止具有較少任務相關性的事務型任務。Executor是在單個傳入的工作隊列由多個工作線程共享的情況下實現的。
對於該模型的一個關鍵問題是增加工作線程數會加劇對工作隊列的爭用(如圖 3 所示)。這種爭用最終會隨線程和核心的增多而成為一個可伸縮性瓶頸。
圖 3. Executor 隊列爭用
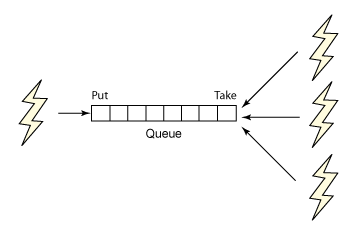
Executor隊列的一個替代項是 fork/join 框架,該框架目前存有 JSR 166y 維護更新,且會在 JDK 7 中正式引入 Java 平台。Fork/join 是為運行細粒度計算任務的大量並發任務而調優的。
GPars 中的 Fork/join
Fork/join 支持定義任務間的依賴關系和生成新任務;這些屬性使其成為分而治之風格算法的理想之選,該算法將一個任務分為若干子任務,然後重新將子計算指令聯合起來。通過讓一個線程擁有一個工作隊列,Fork/join 解決了隊列爭用的問題。所有情況下使用的隊列其實是一種 雙隊列(deque)(兩端都能輸入數據的數據行列,發音為 “deck”),它允許線程從另一個隊列的後端竊取工作,從而平衡進入線程池的工作。
以查找列表中最大值的任務為例。最明顯的戰略是簡單地遍歷所有數字,在遍歷過程中密切注意最大值。但是,這本質上是一種串行戰略,且不利用那些昂貴的核心。
而如果我將最大值函數作為一個分而治之的並行算法來實現,想想會發生什麼。分而治之算法是一種遞歸算法;每一步都具有如清單 5 所示的結構:
清單 5. 分而治之算法
IF problem is small enough to solve directly
THEN solve it directly
ELSE {
Divide the problem in two or more sub-problems
Solve each sub-problem
Combine the results
}
IF條件允許我改變每個任務的粒度。該風格的算法將生成一棵樹,其中樹葉由采用 THEN分支的任務定義。樹中的內部節點是采用 ELSE分支的任務。每個內部節點必須等待(依賴於)其兩個(或多個)子任務。fork/join 模型是專為這種算法設計的,即一棵依賴樹中有大量任務在等待中。fork/join 中處於等待中的任務實際上不阻止線程。
GPars 允許我們通過執行 fork/join 任務來創建和執行 fork/join 算法,如清單 6 所示:
清單 6. max() (computeMax.groovy) 的並行 fork/join 實現
import static groovyx.gpars.GParsPool.runForkJoin
import groovyx.gpars.GParsPool
import groovyx.gpars.AbstractForkJoinWorker
@Grab(group='org.codehaus.gpars', module='gpars', version='0.10')
class Config {
static DATA_COUNT = 2**14
static GRANULARITY_THRESHHOLD = 128
static THREADS = 4
}
items = [] as List<Integer>
items.addAll(1..Config.DATA_COUNT)
Collections.shuffle(items)
GParsPool.withPool(Config.THREADS) {
computedMax = runForkJoin(1, Config.DATA_COUNT, items.asImmutable())
{begin, end, items ->
int size = end - begin
if (size <= Config.GRANULARITY_THRESHHOLD) {
return items[begin..<end].max()
} else { // divide and conquer
leftEnd = begin + ((end + 1 - begin) / 2)
forkOffChild(begin, leftEnd, items)
forkOffChild(leftEnd + 1, end, items)
return childrenResults.max()
}
}
println "expectedMax = ${Config.DATA_COUNT}"
println "computedMax = ${computedMax}"
}
注意,fork/join 在 groovyx.gpars.GParsPool類中擁有其特定的線程池。GParsPool與 GParsExecutorsPool共享多個常見功能,但擁有 fork/join 所特有的功能。要直接使用 fork/join,您必須使用帶有一個任務閉包的 runForkJoin()方法或一個將 AbstractForkJoinWorker分為子類的任務類。
並行集合
Fork/join 提供一種不錯的方式來定義和執行並行任務結構,特別是分而治之算法中的那些結構。不過,您可能已經注意到,上面的示例中涉及到相當多的繁文缛節。我必須定義任務閉包、確定合適的任務粒度、分離子問題、綜合結果,等等。
理論上,我希望在更高抽象級別工作,即定義一個數據結構,然後並行對其執行常見操作,無需在每種情況下定義管理細節的低級別任務。
JSR 166y 維護更新指定為此指定一個高級接口,稱為 ParallelArray。ParallelArray對一個數組結構提供常見的函數程序設計操作,這些函數通過一個 fork/join 池並行執行。
由於 API 的函數特性,傳遞一個函數(方法)給這些操作很有必要,這樣就可以在 ParallelArray中的每個項目上執行它。JDK 7 仍在開發中的一項功能是對 λ 的支持,該功能允許開發人員定義和傳遞代碼塊。此時,JDK 7 中所含 ParallelArray的狀態有待 λ 項目結果定奪。
GPars 中的 ParallelArray
Groovy 完全支持將代碼塊定義為閉包並將它們作為一類對象四處傳遞,因此使用 Groovy 和 GPars 在這種函數式樣下工作很自然。ParallelArray和 GPars 支持一組核心的函數運算符:
map
reduce
filter
size
sum
min
max
另外,GPars 在一個 GParsPool塊內擴展集合,為我們提供構建於原語之上的其他並行方法:
eachParallel
collectParallel
findAllParallel
everyParallel
groupByParallel
可以將並行集合方法透明化,以便標准集合方法默認情況下並行運作。這將允許您傳遞一個並行集合給現有(非並行)代碼庫並按原樣使用該代碼。不過,考慮這些並行方法使用的狀態仍然很重要,因為外部代碼可能不保證必要的同步運作。
再看一下 清單 6中的示例,注意到,max()是一個已經在並行集合中提供的方法,因此沒有必要直接定義和調用 fork/join 任務,如清單 7 所示:
清單 7. 使用 GPars ParallelArray 函數(computeMaxPA.groovy)
import static groovyx.gpars.GParsPool.runForkJoin
import groovyx.gpars.GParsPool
@Grab(group='org.codehaus.gpars', module='gpars', version='0.10')
class Config {
static DATA_COUNT = 2**14
static THREADS = 4
}
items = [] as List<Integer>
items.addAll(1..Config.DATA_COUNT)
Collections.shuffle(items)
GParsPool.withPool(Config.THREADS) {
computedMax = items.parallel.max()
println "expectedMax = ${Config.DATA_COUNT}"
println "computedMax = ${computedMax}"
}
使用 ParallelArray 的函數程序設計
現在假設我在一個庫存系統中編寫訂單報告,計算過期的訂單數以及這些訂單的平均過期天數。我可以這麼做:首先定義方法來確定訂單是否過期(通過比較當前日期與到期日),然後計算今天與到期日之間的天數差額。
該代碼的核心是使用核心的 ParallelArray方法計算所需數目的那一部分,如清單 8 所示:
清單 8. 充分利用並行函數運算符(orders.groovy)
GParsPool.withPool {
def data = createOrders().parallel.filter(isLate).map(daysOverdue)
println("# overdue = " + data.size())
println("avg overdue by = " + (data.sum() / data.size()))
}
這裡我選取了一個訂單列表,將其轉化為一個 ParallelArray,僅保留那些 isLate返回值為真的訂單,並計算了每個訂單的映射函數,以將其轉化為過期天數。然後我可以使用內置的聚合函數來獲取過期天數的大小和總和並計算平均值。該代碼可能與使用函數程序設計語言編寫的那些很類似,不過它的額外優勢在於該代碼是自動並行執行的。
管理狀態
任何時候要處理將由多個線程讀寫的數據時,您必須考慮如何管理該數據並協調更改。用 Java 語言和其他語言管理共享狀態的主導范例包括由鎖或其他關鍵節標記保護的可變狀態。
出於多種原因,可變狀態和鎖容易出問題。鎖意味著要整理代碼中的依賴性,使開發人員對於執行路徑和預期結果有理可循。但是,由於鎖的多個方面未加以實施,因此看到低質量代碼是很常見的,這些代碼包含可見性、安全發布、競爭條件、死鎖和其他常見並發弊病方面的問題。
一個更嚴重的問題是,即使您一開始使用兩個在並發性方面得到正確編寫的組件,也有可能在結合它們時生成新的意外錯誤。因此編寫構建於可變狀態和鎖之上、且該狀態和鎖隨系統增長仍然可靠的並發系統很難。
在接下來幾節,我將展示跨系統中的線程管理和共享狀態的三個范例。從根本上講,這些范例可以(且是)構建於線程和鎖的基底之上,但是它們創建降低復雜度的更高的抽象級別。
我將要展示的三種方法是 actors、agents 和數據流變量,它們均受 GPars 支持。
Actors
actor 范例最初是在 Erlang 中普及的,而最近因在 Scala 中的使用而聲名遠揚。Erlang 是於 20 世紀 80 年代和 90 年代在 Ericsson 專為 AXD301 電信交換機而設計的。設計這種交換機很有挑戰性,需要考慮幾個因素:高可靠性、無停機時間(熱代碼升級)、大規模並發性。
Erlang 以 “進程” 為前提,如同輕量級線程(而不像操作系統進程),但是不直接映射到本地線程。進程的執行由底層虛擬機調度。Erlang 中的進程內存較小,可快速啟動和進行上下文切換。
Erlang actors 僅僅是在進程上執行的函數。Erlang 無共享內存,且其中的所有狀態都是不變的。不可變數據是許多側重於並發性的語言的關鍵方面,因為它有如此好的屬性。不可變數據是不能更改的,因此讀取不可變數據無需用到鎖,即使有多個線程讀取時也是如此。對不可變數據的更改包括構建數據新版本並從新版本開始工作。對於主要在共享可變狀態語言(比如 Java 語言)方面有背景知識的開發人員來說,這一角度轉變需要一些時間來適應。
狀態是通過傳遞不可變消息在 actors 之間 “共享” 的。每個 actor 都有一個郵箱,而且通過在其郵箱中接收消息可反復執行 actor函數。消息的發送通常是異步的,盡管構建同步調用也很簡單,而且有些 actor 實現提供這樣的特性。
GPars 中的 Actors
GPars 使用來自 Erlang 和 Scala 的許多概念實現 actor 模型。GPars 中的 Actors 是從郵箱中使用消息的輕量級進程。根據消息是由 receive()或 react()方法使用,可以放棄或保留線程綁定。
在 GPars 中,可以利用接受閉包的 factory 方法或通過為 groovyx.gpars.actor.AbstractPooledActor劃分子類來創建 actors。在 actor 中,應當由一個 act()方法。通常 act()方法包含一個無止境重復的循環,然後調用 react(面向輕量級 actor)或 receive(面向仍然與其線程綁定的重量級 actor)。
清單 9. 'Rock, Paper, Scissors' (rps.groovy) 的 actor 實現
package puredanger.gparsdemo.rps;
import groovyx.gpars.actor.AbstractPooledActor
enum Move { ROCK, PAPER, SCISSORS }
@Grab(group='org.codehaus.gpars', module='gpars', version='0.10')
class Player extends AbstractPooledActor {
String name
def random = new Random()
void act() {
loop {
react {
// player replies with a random move
reply Move.values()[random.nextInt(Move.values().length)]
}
}
}
}
class Coordinator extends AbstractPooledActor {
Player player1
Player player2
int games
void act() {
loop {
react {
// start the game
player1.send("play")
player2.send("play")
// decide the winner
react {msg1 ->
react {msg2 ->
announce(msg1.sender.name, msg1, msg2.sender.name, msg2)
// continue playing
if(games-- > 0)
send("start")
else
stop()
}
}
}
}
}
void announce(p1, m1, p2, m2) {
String winner = "tie"
if(firstWins(m1, m2) && ! firstWins(m2, m1)) {
winner = p1
} else if(firstWins(m2, m1) && ! firstWins(m1, m2)) {
winner = p2
} // else tie
if(p1.compareTo(p2) < 0) {
println toString(p1, m1) + ", " + toString(p2, m2) + ", winner = " + winner
} else {
println toString(p2, m2) + ", " + toString(p1, m1) + ", winner = " + winner
}
}
String toString(player, move) {
return player + " (" + move + ")"
}
boolean firstWins(Move m1, Move m2) {
return (m1 == Move.ROCK && m2 == Move.SCISSORS) ||
(m1 == Move.PAPER && m2 == Move.ROCK) ||
(m1 == Move.SCISSORS && m2 == Move.PAPER)
}
}
final def player1 = new Player(name: "Player 1")
final def player2 = new Player(name: "Player 2")
final def coordinator = new Coordinator(player1: player1, player2: player2, games: 10)
[player1,player2,coordinator]*.start()
coordinator << "start"
coordinator.join()
[player1,player2]*.terminate()
清單 9 含有對 “Rock, Paper, Scissors” 游戲的完整表示,該游戲是通過 GPars 使用一個 Coordinatoractor 和兩個 Playeractors 實現的。Coordinator發送一條 play消息給兩個 Players,然後等待接收響應。在它接收到兩條響應之後,Coordinator打印出比賽結果並自我發送一條消息,以開始新游戲。Playeractors 等待動向請求,因此每一個都用一個任意舉動進行響應。
GPars 很好地實現了所有關鍵 actor 功能以及一些額外功能。actor 方法也許不是針對所有並發性問題的最佳解決方案,但是它確實提供了很好的方式來建模涉及消息傳遞的問題。
Agents
Agents 在 Clojure中用於協調對可識別變更狀態的多線程訪問。Agents 分離不必要的身份(所指內容的名稱)耦合和該身份引用的當前值。在大部分語言中,這兩個方面有著千絲萬縷的聯系,因此擁有名稱也就意味著您可以變更值。該關系如圖 4 所示:
圖 4. 管理狀態的 Agent
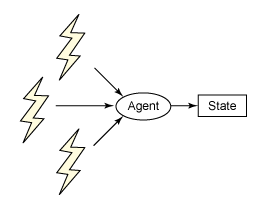
Agents 在變量持有者與可變狀態本身之間提供一層間接關系。要更改狀態,您可以向 agent 傳遞一個函數,然後 agent 評估功能流,用每個函數的輸出替換狀態。由於 agent 序列化了數據訪問,因此不會有競爭條件或數據損壞風險。
此外,數據的讀取包括查看當前快照,這僅需很少的並發性開銷,因為快照不會改變。
變更被異步發送到 agents。如有必要,一個線程可以阻止 agent,直至其更改被應用,或者您可以在應用變更時指定執行一個操作。
GPars 中的 agents
GPars 實現 Clojure 中的很多 agent 功能。在清單 10 中,我建模了一個僵屍進程入侵場景,並管理了 agent 內的世界狀態。有兩個線程:其中一個線程假設每隔一定時間,一個僵屍進程就會吃人腦,將該數字轉化為僵屍。另一個進程假設其余僵屍進程的 5% 被幸存者使用彈槍殺死。主線程監守世界並報告入侵進度。
清單 10. 保護世界免受僵屍大災難
(zombieApocalypse.groovy)
import groovyx.gpars.agent.Agent
import groovyx.gpars.GParsExecutorsPool
public class World {
int alive = 1000
int undead = 10
public void eatBrains() {
alive = alive - undead
undead = undead * 2
if(alive <= 0) {
alive = 0
println "ZOMBIE APOCALYPSE!"
}
}
public void shotgun() {
undead = undead * 0.95
}
public boolean apocalypse() {
alive <= 0
}
public void report() {
if(alive > 0) {
println "alive=" + alive + " undead=" + undead
}
}
}
@Grab(group='org.codehaus.gpars', module='gpars', version='0.10')
def final world = new Agent<World>(new World())
final Thread zombies = Thread.start {
while(! world.val.apocalypse()) {
world << { it.eatBrains() }
sleep 200
}
}
final Thread survivors = Thread.start {
while(! world.val.apocalypse()) {
world << { it.shotgun() }
sleep 200
}
}
while(! world.instantVal.apocalypse()) {
world.val.report()
sleep 200
}
Agents 是 Clojure 中的一個重要特性,很高興可以看到它們出現在 GPars 中。GPars 實現在失去一些功能(比如修改操作和觀察程序),但這些只是微小遺漏,將來可能會予以添加。
數據流變量
數據流變量與 Oz 編程語言顯著關聯,但是實現已在 Clojure、Scala 和 GPars 中得到構建。
對數據流變量的最常用類比是,它們如同電子表格中的單元格 —它們關注於指定必須發生的計算和必須提供值來執行該計算的變量。底層調度程序然後負責執行能夠取得進展的線程,因為其輸入可用。數據流系統僅關注數據如何在系統中流動,交由線程來決定如何有效利用多個核心。
數據流有一些不錯的屬性,其中問題的某些類是不可能的(競爭條件),某些類是可能而決定性的(死鎖);因此您可以確保,如果您的代碼在測試期間不生成死鎖,它在生產過程中就不會經歷死鎖現象。
數據流變量可能僅被綁定一次,因而其使用是有限的。數據流充當值的綁定隊列,因此可以通過代碼定義的結構灌注數據,保留相同的有益屬性。在實踐中,數據流變量提供一種不錯的方式來將值從一個線程傳輸到另一個線程,且它們通常用於傳輸多線程單元測試中的結果。GPars 還定義通過線程池(比如 actors)調度的邏輯數據流任務並通過數據流變量進行傳輸。
Dataflow streams
在 清單 2中,您看到每個後台線程接收和打印檢索特定主題 tweets 的結果。清單 11 是該程序的一個變體,只是此次創建一個 DataFlowStream。後台任務將使用 DataFlowStream來將結果 tweets 流式傳輸回主線程,該主線程從數據流中讀取它們。
清單 11. 通過 DataFlowStream 流式傳輸結果
(langTweetsDataflow.groovy)
import twitter4j.Twitter
import twitter4j.Query
import groovyx.gpars.GParsExecutorsPool
import groovyx.gpars.dataflow.DataFlowStream
@Grab(group='net.homeip.yusuke', module='twitter4j', version='2.0.10')
@Grab(group='org.codehaus.gpars', module='gpars', version='0.10')
def recentTweets(api, queryStr, resultStream) {
query = new Query(queryStr)
query.rpp = 5 // tweets to return
query.lang = "en" // language
tweets = api.search(query).tweets
threadName = Thread.currentThread().name
tweets.each {
resultStream << "[${threadName}-${queryStr}] @${it.fromUser}: ${it.text}"
}
resultStream << "DONE"
}
def api = new Twitter()
def resultStream = new DataFlowStream()
def tags = ['#erlang','#scala','#clojure']
GParsExecutorsPool.withPool {
tags.each {
{ query -> recentTweets(api, query, resultStream) }.callAsync(it)
}
}
int doneMessages = 0
while(doneMessages < tags.size()) {
msg = resultStream.val
if(msg == "DONE") {
doneMessages++
} else {
println "${msg}"
}
}
注意,“DONE” 消息被通過數據流從每個後台線程發送到結果偵聽程序。表示線程發送結果任務已完成的指標有時在消息傳遞領域稱為 “毒消息”。它充當 producer 與 consumer 之間的信號。
管理狀態的其他方法
本文中未涉及的兩個重要並發模型是通信順序進程(CSP)和軟件事務內存(STM)。
CSP 基於 Tony Hoare 的經典之作中對並發程序行為的正式規范,且基於進程和通道的核心概念。進程在某些方面與前面討論的 actor 模型類似,而 通道與數據流有很多相似之處。CSP 進程與 actors 的不同之處在於,它比單個郵箱有更豐富的輸入和輸出通道集。GPars 包含一個 API,完成 CSP 思想的 JCSP 實現。
STM 過去幾年中一直是一個活躍研究領域,Haskell、Clojure 和 Fortress 等語言包括(有點不同)該概念的實現。STM 需要程序員在源代碼中劃分事務界限,然後系統向底層狀態應用每個事務。如果檢測到沖突,可以重試事務,不過它是自動處理的。然而,GPars 不包括 STM 的實現,但是將來有可能會包括。
結束語
並發性目前是一個熱門領域,各種語言和庫采用的方法之間有諸多混雜。GPars 采用目前一些最流行的並發模型,通過 Groovy 使其在 Java 平台上可訪問。
帶有大量核心的計算機占據很大地位,而且事實上在芯片上可用的核心的數量呈指數級上升。相應地,並發性會繼續成為一個探索和革新領域;我們得知,JVM 將成為最持久方案之源。