前面我們比較了 muduo 和 libevent2 的吞吐量,得到的結論是 muduo 比 libevent2 快 18%。有 人會說,libevent2 並不是為高吞吐的應用場景而設計的,這樣的比較不公平,勝之不武。為了公平起 見,這回我們用 libevent2 自帶的性能測試程序(擊鼓傳花)來對比 muduo 和 libevent2 在高並發 情況下的 IO 事件處理效率。
測試對象
libevent 2.0.6-rc, 源代碼包 http://monkey.org/~provos/libevent-2.0.6-rc.tar.gz
muduo 0.1.2-alpha,源碼 http://muduo.googlecode.com/files/muduo-0.1.2-alpha.tar.gz SHA1 Checksum: 9e7da4b46ad87602dd206eaedf54e67c17dfe4e1 。須編譯為 release 版。
測試環境
測試用的軟硬件環境與《muduo 與 boost asio 吞吐量對比》和《muduo 與 libevent2 吞吐量對比》相同,另外我還在自己的筆記本上運行了測試,結果也附在後面。
測 試內容
測試的場景是:有 1000 個人圍成一圈,玩擊鼓傳花的游戲,一開始第 1 個人手裡有花 ,他把花傳給右手邊的人,那個人再繼續把花傳給右手邊的人,當花轉手 100 次之後游戲停止,記錄 從開始到結束的時間。
用程序表達是,有 1000 個網絡連接 (socketpairs 或 pipes),數據在 這些連接中順次傳遞,一開始往第 1 個連接裡寫 1 個字節,然後從這個連接的另一頭讀出這 1 個字 節,再寫入第 2 個連接,然後讀出來繼續寫到第 3 個連接,直到一共寫了 100 次之後程序停止,記 錄所用的時間。
以上是只有一個活動連接的場景,我們實際測試的是 100 個或 1000 個活動連 接(即 100 朵花或 1000 朵花,均勻分散在人群手中),而連接總數(即並發數)從 100 到 100,000 (十萬)。注意每個連接是兩個文件描述符,為了運行測試,需要調高每個進程能打開的文件數,比如設 為 256000。
libevent2 的測試代碼位於 test/bench.c,我修復了 2.0.6-rc 版裡的一個小 bug,修正後的代碼見 http://github.com/chenshuo/recipes/blob/master/pingpong/libevent/bench.c
muduo 的測 試代碼位於 examples/pingpong/bench.cc,見 http://gist.github.com/564985#file_pingpong_bench.cc
測試結果與討論
第一輪,分 別用 100 個活動連接和 1000 個活動連接,無超時,讀寫 100 次,測試一次游戲的總時間(包含初始 化)和事件處理的時間(不包含注冊 event watcher)隨連接數(並發數)變化的情況。具體解釋見 libev 的性能測試文檔 http://libev.schmorp.de/bench.html ,不同之處在於我們不比較 timer event 的性能,只比較 IO event 的性能。對每個並發數,程序循環 25 次,刨去第一次的熱身數據, 後 24 次算平均值。測試用的腳本在 http://github.com/chenshuo/recipes/blob/master/pingpong/libevent/run_bench.sh 。這個腳本是 libev 的作者 Marc Lehmann 寫的,我略作改用,用於測試 muduo 和 libevent2。
第一輪的結 果,請先只看紅線和綠線。紅線是 libevent2 用的時間,綠線是 muduo 用的時間。數字越小越好。注 意這個圖的橫坐標是對數的,每一個數量級的取值點為 1, 2, 3, 4, 5, 6, 7.5, 10。
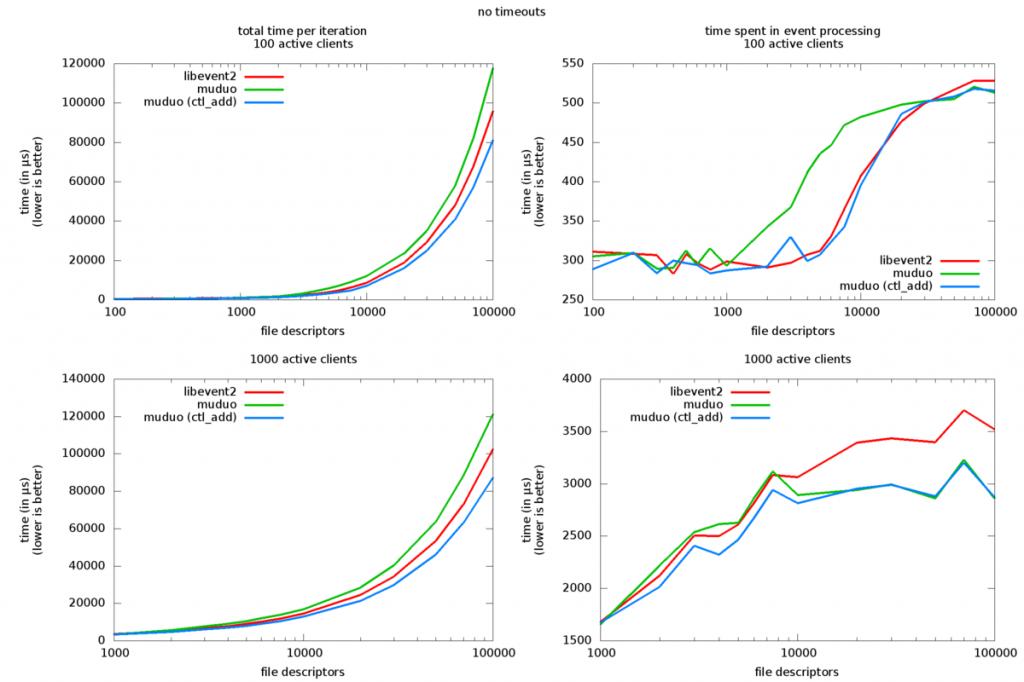
從紅綠線對比可以看出:
1. libevent2 在初始化 event watcher 上面比 muduo 快 20% ( 左邊的兩個圖)
2. 在事件處理方面(右邊的兩個圖):a) 在 100 個活動連接的情況下, libevent2 和 muduo 分段領先。當總連接數(並發數)小於 1000 時,二者性能差不多;當總連接數 大於 30000 時,muduo 略占優;當總連接數大於 1000 小於 30000 時,libevent2 明顯領先。b) 在 1000 個活動連接的情況下,當並發數小於 10000 時,libevent2 和 muduo 得分接近;當並發數大於 10000 時,muduo 明顯占優。
這裡我們有兩個問題:1. 為什麼 muduo 花在初始化上的時間比 較多? 2. 為什麼在一些情況下它比 libevent2 慢很多。
我仔細分析了其中的原因,並參考了 libev 的作者 Marc Lehmann 的觀點 ( http://lists.schmorp.de/pipermail/libev/2010q2/001041.html ),結論是:在第一輪初始化時, libevent2 和 muduo 都是用 epoll_ctl(fd, EPOLL_CTL_ADD, …) 來添加 fd event watcher。不同之 處在於,在後面 24 輪中,muduo 使用了 epoll_ctl(fd, EPOLL_CTL_MOD, …) 來更新已有的 event watcher;然而 libevent2 繼續調用 epoll_ctl(fd, EPOLL_CTL_ADD, …) 來重復添加 fd,並忽略返 回的錯誤碼 EEXIST (File exists)。在這種重復添加的情況下,EPOLL_CTL_ADD 將會快速地返回錯誤 ,而 EPOLL_CTL_MOD 會做更多的工作,花的時間也更長。於是 libevent2 撿了個便宜。
為了 驗證這個結論,我改動了 muduo,讓它每次都用 EPOLL_CTL_ADD 方式初始化和更新 event watcher, 並忽略返回的錯誤。
第二輪測試結果見上圖的藍線,可見改動之後的 muduo 的初始化性能比 libevent2 更好,事件處理的耗時也有所降低(我推測是 kernel 內部的原因)。
這個改動只 是為了驗證想法,我並沒有把它放到 muduo 最終的代碼中去,這或許可以留作日後優化的余地。(具 體的改動是 muduo/net/poller/EPollPoller.cc 第 115 行和 144 行,讀者可自行驗證。)
同 樣的測試在雙核筆記本電腦上運行了一次,結果如下:(我的筆記本的 CPU 主頻是 2.4GHz,高於台式 機的 1.86GHz,所以用時較少。)
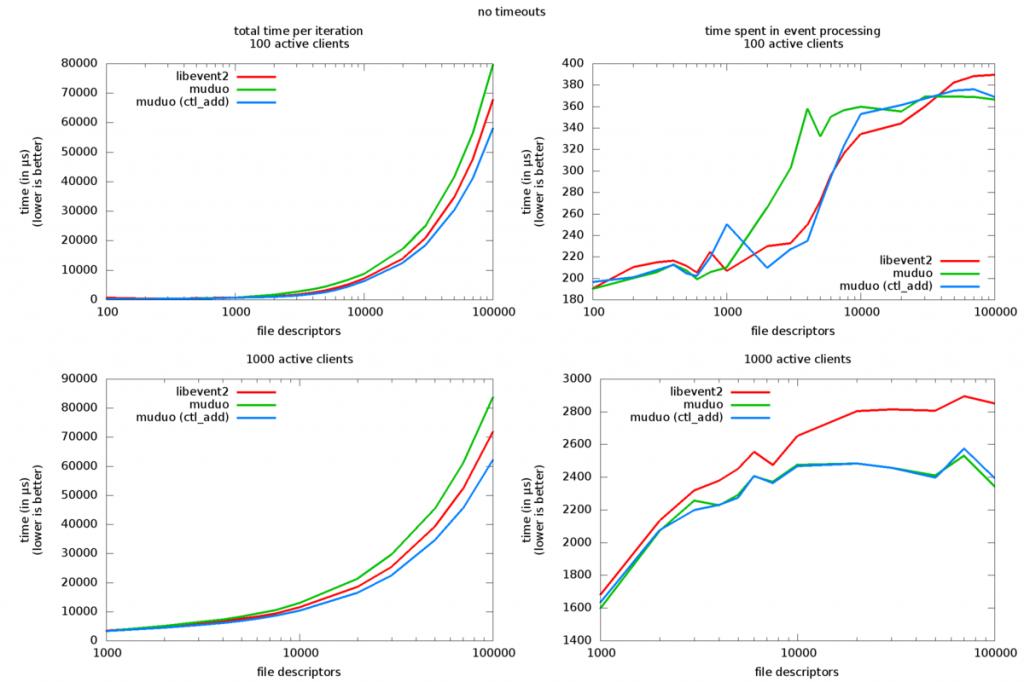
結論:在事件處理效率方面,muduo 與 libevent2 總體比較接近,各擅勝場。在並發量特別大的情 況下(大於 10k),muduo 略微占優。
查看本欄目