本文以一個 Sudoku Solver 為例,回顧了並發網絡服務程序的多種設計方案,並介紹了使用 muduo 網絡庫編寫多線程服務器的兩種最常用手法。以往的例子展現了 Muduo 在編寫單線程並發網絡服務程 序方面的能力與便捷性,今天我們看一看它在多線程方面的表現。
本文代碼見: http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/
下載: http://muduo.googlecode.com/files/muduo-0.2.5-alpha.tar.gz
Sudoku Solver
假設 有這麼一個網絡編程任務:寫一個求解數獨的程序 (Sudoku Solver),並把它做成一個網絡服務。
Sudoku Solver 是我喜愛的網絡編程例子,它曾經出現在《分布式系統部署、監控與進程管理 的幾重境界》、《Muduo 設計與實現之一:Buffer 類的設計》、《〈多線程服務器的適用場合〉例釋 與答疑》等文中,它也可以看成是 echo 服務的一個變種(《談一談網絡編程學習經驗》把 echo 列為 三大 TCP 網絡編程案例之一)。
寫這麼一個程序在網絡編程方面的難度不高,跟寫 echo 服務 差不多(從網絡連接讀入一個 Sudoku 題目,算出答案,再發回給客戶),挑戰在於怎樣做才能發揮現 在多核硬件的能力?在談這個問題之前,讓我們先寫一個基本的單線程版。
協議
一個 簡單的以 /r/n 分隔的文本行協議,使用 TCP 長連接,客戶端在不需要服務時主動斷開連接。
請求:[id:]〈81digits〉/r/n
響應:[id:]〈81digits〉/r/n 或者 [id:] NoSolution/r/n
其中[id:]表示可選的 id,用於區分先後的請求,以支持 Parallel Pipelining,響應中會回顯請求中的 id。Parallel Pipelining 的意義見賴勇浩的《以小見大——那 些基於 protobuf 的五花八門的 RPC(2) 》,或者見我寫的《分布式系統的工程化開發方法》第 54 頁關於 out-of-order RPC 的介紹。
〈81digits〉是 Sudoku 的棋盤,9x9 個數字,未知數字 以 0 表示。
如果 Sudoku 有解,那麼響應是填滿數字的棋盤;如果無解,則返回 NoSolution 。
例子1:
請求: 000000010400000000020000000000050407008000300001090000300400200050100000000806000/r/n
< p>響應: 693784512487512936125963874932651487568247391741398625319475268856129743274836159/r/n
< p>例子2:
請求: a:000000010400000000020000000000050407008000300001090000300400200050100000000806000/r/n
響應: a:693784512487512936125963874932651487568247391741398625319475268856129743274836159/r/n
例子3:
請求: b:000000010400000000020000000000050407008000300001090000300400200050100000000806005/r/n
響應:b:NoSolution/r/n
基於這個文本協議,我們可以用 telnet 模擬客戶端來測試 sudoku solver,不需要單獨編寫 sudoku client。SudokuSolver 的默認端口號是 9981,因為它有 9x9=81 個格子。
基本實現
Sudoku 的求解算法見《談談數獨(Sudoku)》一文,這不是 本文的重點。假設我們已經有一個函數能求解 Sudoku,它的原型如下
string solveSudoku (const string& puzzle);
函數的輸入是上文的"〈81digits〉",輸出是" 〈81digits〉"或"NoSolution"。這個函數是個 pure function,同時也是線程安全的 。
有了這個函數,我們以《Muduo 網絡編程示例之零:前言》中的 EchoServer 為藍本,稍作 修改就能得到 SudokuServer。這裡只列出最關鍵的 onMessage() 函數,完整的代碼見 http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/server_basic.cc 。 onMessage() 的主要功能是處理協議格式,並調用 solveSudoku() 求解問題。
//
muduo/examples/sudoku/server_basic.cc
const int kCells = 81;
void onMessage(const TcpConnectionPtr& conn, Buffer* buf, Timestamp)
{
LOG_DEBUG << conn->name();
size_t len = buf->readableBytes();
while (len >= kCells + 2)
{
const char* crlf = buf->findCRLF();
if (crlf)
{
string request(buf->peek(), crlf);
string id;
buf->retrieveUntil(crlf + 2);
string::iterator colon = find(request.begin(), request.end(), ':');
if (colon != request.end())
{
id.assign(request.begin(), colon);
request.erase(request.begin(), colon+1);
}
if (request.size() == implicit_cast(kCells))
{
string result = solveSudoku(request);
if (id.empty())
{
conn->send(result+"/r/n");
}
else
{
conn->send(id+":"+result+"/r/n");
}
}
else
{
conn->send("Bad Request!/r/n");
conn->shutdown();
}
}
else
{
break;
}
}
}
server_basic.cc 是一個並發服務器,可以同時服務多個客戶連接。但是它是單線程的, 無法發揮多核硬件的能力。
Sudoku 是一個計算密集型的任務(見《Muduo 設計與實現之一: Buffer 類的設計》中關於其性能的分析),其瓶頸在 CPU。為了讓這個單線程 server_basic 程序充 分利用 CPU 資源,一個簡單的辦法是在同一台機器上部署多個 server_basic 進程,讓每個進程占用 不同的端口,比如在一台 8 核機器上部署 8 個 server_basic 進程,分別占用 9981、9982、……、 9988 端口。這樣做其實是把難題推給了客戶端,因為客戶端(s)要自己做負載均衡。再想得遠一點,在 8 個 server_basic 前面部署一個 load balancer?似乎小題大做了。
能不能在一個端口上提 供服務,並且又能發揮多核處理器的計算能力呢?當然可以,辦法不止一種。
常見的並發網絡 服務程序設計方案
W. Richard Stevens 的 UNP2e 第 27 章 Client-Server Design Alternatives 介紹了十來種當時(90 年代末)流行的編寫並發網絡程序的方案。UNP3e 第 30 章,內 容未變,還是這幾種。以下簡稱 UNP CSDA 方案。UNP 這本書主要講解阻塞式網絡編程,在非阻塞方面 著墨不多,僅有一章。正確使用 non-blocking IO 需要考慮的問題很多,不適宜直接調用 Sockets API,而需要一個功能完善的網絡庫支撐。
隨著 2000 年前後第一次互聯網浪潮的興起,業界對 高並發 http 服務器的強烈需求大大推動了這一領域的研究,目前高性能 httpd 普遍采用的是單線程 reactor 方式。另外一個說法是 IBM Lotus 使用 TCP 長連接協議,而把 Lotus 服務端移植到 Linux 的過程中 IBM 的工程師們大大提高了 Linux 內核在處理並發連接方面的可伸縮性,因為一個公司可能 有上萬人同時上線,連接到同一台跑著 Lotus server 的 Linux 服務器。
可伸縮網絡編程這個 領域其實近十年來沒什麼新東西,POSA2 已經作了相當全面的總結,另外以下幾篇文章也值得參考。
http://bulk.fefe.de/scalable- networking.pdf
http://www.kegel.com/c10k.html
http://gee.cs.oswego.edu/dl/cpjs lides/nio.pdf
下表是陳碩總結的 10 種常見方案。其中“多連接互通”指的是如果開發 chat 服務,多個客戶連接之間是否能方便地交換數據(chat 也是《談一談網絡編程學習經驗》中舉的三大 TCP 網絡編程案例之一)。對於 echo/http/sudoku 這類“連接相互獨立”的服務程序,這個功能無足 輕重,但是對於 chat 類服務至關重要。“順序性”指的是在 http/sudoku 這類請求-響應服務中,如 果客戶連接順序發送多個請求,那麼計算得到的多個響應是否按相同的順序發還給客戶(這裡指的是在 自然條件下,不含刻意同步)。
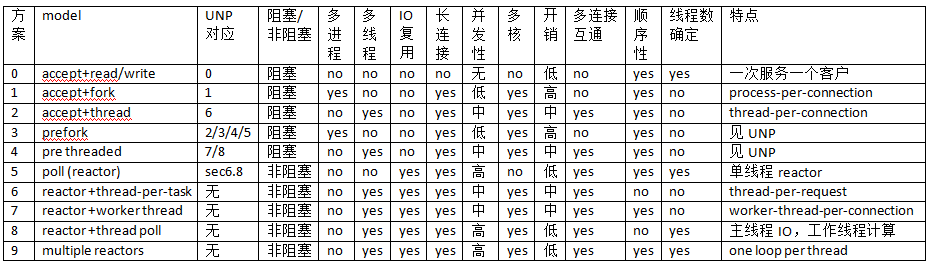
UNP CSDA 方案歸入 0~5。5 也是目前用得很多的單線程 reactor 方案,muduo 對此提供了很好 的支持。6 和 7 其實不是實用的方案,只是作為過渡品。8 和 9 是本文重點介紹的方案,其實這兩個 方案已經在《多線程服務器的常用編程模型》一文中提到過,只不過當時我還沒有寫 muduo,無法用具 體的代碼示例來說明。
在對比各方案之前,我們先看看基本的 micro benchmark 數據(前三項 由 lmbench 測得):
fork()+exit(): 160us
pthread_create()+pthread_join(): 12us
context switch : 1.5us
sudoku resolve: 100us (根據題目難度不同,浮動范圍 20~200us)
方案 0:這其實不是並發服務器,而是 iterative 服務器,因為它一次只能服務一個客戶。代碼 見 UNP figure 1.9,UNP 以此為對比其他方案的基准點。這個方案不適合長連接,到是很適合 daytime 這種 write-only 服務。
方案 1:這是傳統的 Unix 並發網絡編程方案,UNP 稱之為 child-per-client 或 fork()-per-client,另外也俗稱 process-per-connection。這種方案適合並發 連接數不大的情況。至今仍有一些網絡服務程序用這種方式實現,比如 PostgreSQL 和 Perforce 的服 務端。這種方案適合“計算響應的工作量遠大於 fork() 的開銷”這種情況,比如數據庫服務器。這種 方案適合長連接,但不太適合短連接,因為 fork() 開銷大於求解 sudoku 的用時。
方案 2: 這是傳統的 Java 網絡編程方案 thread-per-connection,在 Java 1.4 引入 NIO 之前,Java 網絡服 務程序多采用這種方案。它的初始化開銷比方案 1 要小很多。這種方案的伸縮性受到線程數的限制, 一兩百個還行,幾千個的話對操作系統的 scheduler 恐怕是個不小的負擔。
方案 3:這是針對 方案 1 的優化,UNP 詳細分析了幾種變化,包括對 accept 驚群問題的考慮。
方案 4:這是對 方案 2 的優化,UNP 詳細分析了它的幾種變化。
以上幾種方案都是阻塞式網絡編程,程序 (thread-of-control)通常阻塞在 read() 上,等待數據到達。但是 TCP 是個全雙工協議,同時支持 read() 和 write() 操作,當一個線程/進程阻塞在 read() 上,但程序又想給這個 TCP 連接發數據, 那該怎麼辦?比如說 echo client,既要從 stdin 讀,又要從網絡讀,當程序正在阻塞地讀網絡的時 候,如何處理鍵盤輸入?又比如 proxy,既要把連接 a 收到的數據發給連接 b,又要把從連接 b 收到 的數據發給連接 a,那麼到底讀哪個?(proxy 是《談一談網絡編程學習經驗》中舉的三大 TCP 網絡 編程案例之一。)
一種方法是用兩個線程/進程,一個負責讀,一個負責寫。UNP 也在實現 echo client 時介紹了這種方案。另外見 Python Pinhole 的代碼: http://code.activestate.com/recipes/114642/
另一種方法是使用 IO multiplexing,也就是 select/poll/epoll/kqueue 這一系列的“多路選擇器”,讓一個 thread-of-control 能處理多個連接 。“IO 復用”其實復用的不是 IO 連接,而是復用線程。使用 select/poll 幾乎肯定要配合 non- blocking IO,而使用 non-blocking IO 肯定要使用應用層 buffer,原因見《Muduo 設計與實現之一 :Buffer 類的設計》。這就不是一件輕松的事兒了,如果每個程序都去搞一套自己的 IO multiplexing 機制(本質是 event-driven 事件驅動),這是一種很大的浪費。感謝 Doug Schmidt 為我們總結出了 Reactor 模式,讓 event-driven 網絡編程有章可循。繼而出現了一些通用的 reactor 框架/庫,比如 libevent、muduo、Netty、twisted、POE 等等,有了這些庫,我想基本不用 去編寫阻塞式的網絡程序了(特殊情況除外,比如 proxy 流量限制)。
單線程 reactor 的程 序結構是(圖片取自 Doug Lea 的演講):

方案 5:基本的單線程 reactor 方案,即前面的 server_basic.cc 程序。本文以它作為對比其 他方案的基准點。這種方案的優點是由網絡庫搞定數據收發,程序只關心業務邏輯;缺點在前面已經談 了:適合 IO 密集的應用,不太適合 CPU 密集的應用,因為較難發揮多核的威力。
方案 6:這 是一個過渡方案,收到 Sudoku 請求之後,不在 reactor 線程計算,而是創建一個新線程去計算,以 充分利用多核 CPU。這是非常初級的多線程應用,因為它為每個請求(而不是每個連接)創建了一個新 線程。這個開銷可以用線程池來避免,即方案 8。這個方案還有一個特點是 out-of-order,即同時創 建多個線程去計算同一個連接上收到的多個請求,那麼算出結果的次序是不確定的,可能第 2 個 Sudoku 比較簡單,比第 1 個先算出結果。這也是為什麼我們在一開始設計協議的時候使用了 id,以 便客戶端區分 response 對應的是哪個 request。
方案 7:為了讓返回結果的順序確定,我們 可以為每個連接創建一個計算線程,每個連接上的請求固定發給同一個線程去算,先到先得。這也是一 個過渡方案,因為並發連接數受限於線程數目,這個方案或許還不如直接使用阻塞 IO 的 thread-per -connection 方案2。方案 7 與方案 6 的另外一個區別是一個 client 的最大 CPU 占用率,在方案 6 中,一個 connection 上發來的一長串突發請求(burst requests) 可以占滿全部 8 個 core;而在方 案 7 中,由於每個連接上的請求固定由同一個線程處理,那麼它最多占用 12.5% 的 CPU 資源。這兩 種方案各有優劣,取決於應用場景的需要,到底是公平性重要還是突發性能重要。這個區別在方案 8 和方案 9 中同樣存在,需要根據應用來取捨。
方案 8:為了彌補方案 6 中為每個請求創建線 程的缺陷,我們使用固定大小線程池,程序結構如下圖。全部的 IO 工作都在一個 reactor 線程完成 ,而計算任務交給 thread pool。如果計算任務彼此獨立,而且 IO 的壓力不大,那麼這種方案是非常 適用的。Sudoku Solver 正好符合。代碼見: http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/server_threadpool.cc 後 文給出了它與方案 9 的區別。

如果 IO 的壓力比較大,一個 reactor 忙不過來,可以試試 multiple reactors 的方案 9。
方案 9:這是 muduo 內置的多線程方案,也是 Netty 內置的多線程方案。這種方案的特點是 one loop per thread,有一個 main reactor 負責 accept 連接,然後把連接掛在某個 sub reactor 中(muduo 采用 round-robin 的方式來選擇 sub reactor),這樣該連接的所有操作都在那個 sub reactor 所處的線程中完成。多個連接可能被分派到多個線程中,以充分利用 CPU。Muduo 采用的是固 定大小的 reactor pool,池子的大小通常根據 CPU 核數確定,也就是說線程數是固定的,這樣程序的 總體處理能力不會隨連接數增加而下降。另外,由於一個連接完全由一個線程管理,那麼請求的順序性 有保證,突發請求也不會占滿全部 8 個核(如果需要優化突發請求,可以考慮方案 10)。這種方案把 IO 分派給多個線程,防止出現一個 reactor 的處理能力飽和。與方案 8 的線程池相比,方案 9 減少 了進出 thread pool 的兩次上下文切換。我認為這是一個適應性很強的多線程 IO 模型,因此把它作 為 muduo 的默認線程模型。
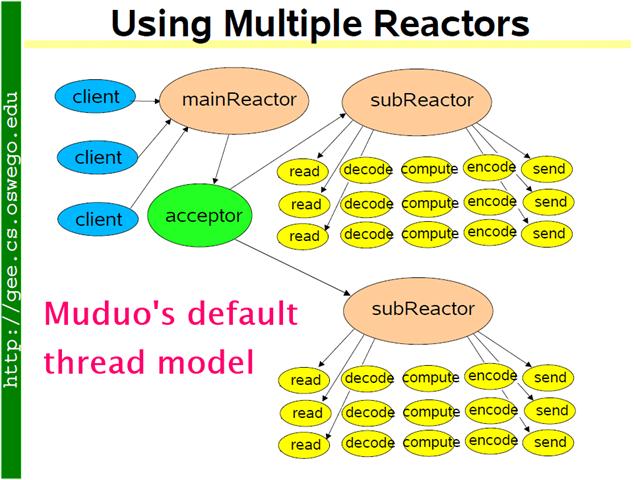
代碼見: http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/server_multiloop.cc
server_multiloop.cc 與 server_basic.cc 的區別很小,關鍵只有一行代碼: server_.setThreadNum(numThreads);
$ diff server_basic.cc server_multiloop.cc -up
--- server_basic.cc 2011-06-15 13:40:59.000000000 +0800
+++ server_multiloop.cc 2011-06-15 13:39:53.000000000 +0800
@@ -21,19 +21,22 @@ using namespace muduo::net;
class SudokuServer
{
public:
- SudokuServer(EventLoop* loop, const InetAddress& listenAddr)
+ SudokuServer(EventLoop* loop, const InetAddress& listenAddr, int numThreads)
: loop_(loop),
server_(loop, listenAddr, "SudokuServer"),
+ numThreads_(numThreads),
startTime_(Timestamp::now())
{
server_.setConnectionCallback(
boost::bind(&SudokuServer::onConnection, this, _1));
server_.setMessageCallback(
boost::bind(&SudokuServer::onMessage, this, _1, _2, _3));
+ server_.setThreadNum(numThreads);
}
查看本欄目
方案 8 使用 thread pool 的代碼與使用多 reactors 的方案 9 相比變化不大,只是把 原來 onMessage() 中涉及計算和發回響應的部分抽出來做成一個函數,然後交給 ThreadPool 去計算 。記住方案 8 有 out-of-order 的可能,客戶端要根據 id 來匹配響應。
$ diff
server_multiloop.cc server_threadpool.cc -up
--- server_multiloop.cc 2011-06-15 13:39:53.000000000 +0800
+++ server_threadpool.cc 2011-06-15 14:07:52.000000000 +0800
@@ -31,12 +32,12 @@ class SudokuServer
boost::bind(&SudokuServer::onConnection, this, _1));
server_.setMessageCallback(
boost::bind(&SudokuServer::onMessage, this, _1, _2, _3));
- server_.setThreadNum(numThreads);
}
void start()
{
LOG_INFO << "starting " << numThreads_ << " threads.";
+ threadPool_.start(numThreads_);
server_.start();
}
@@ -68,15 +69,7 @@ class SudokuServer
}
if (request.size() == implicit_cast(kCells))
{
- string result = solveSudoku(request);
- if (id.empty())
- {
- conn->send(result+"/r/n");
- }
- else
- {
- conn->send(id+":"+result+"/r/n");
- }
+ threadPool_.run(boost::bind(solve, conn, request, id));
}
else
{
@@ -91,8 +84,23 @@ class SudokuServer
}
}
+ static void solve(const TcpConnectionPtr& conn, const string& request, const
string& id)
+ {
+ LOG_DEBUG << conn->name();
+ string result = solveSudoku(request);
+ if (id.empty())
+ {
+ conn->send(result+"/r/n");
+ }
+ else
+ {
+ conn->send(id+":"+result+"/r/n");
+ }
+ }
+
EventLoop* loop_;
TcpServer server_;
+ ThreadPool threadPool_;
int numThreads_;
Timestamp startTime_;
};
完整代碼見: http://code.google.com/p/muduo/source/browse/trunk/examples/sudoku/server_threadpool.cc
方案 10:把方案 8 和方案 9 混合,既使用多個 reactors 來處理 IO,又使用線程池來處理計算 。這種方案適合既有突發 IO (利用多線程處理多個連接上的 IO),又有突發計算的應用(利用線程 池把一個連接上的計算任務分配給多個線程去做)。
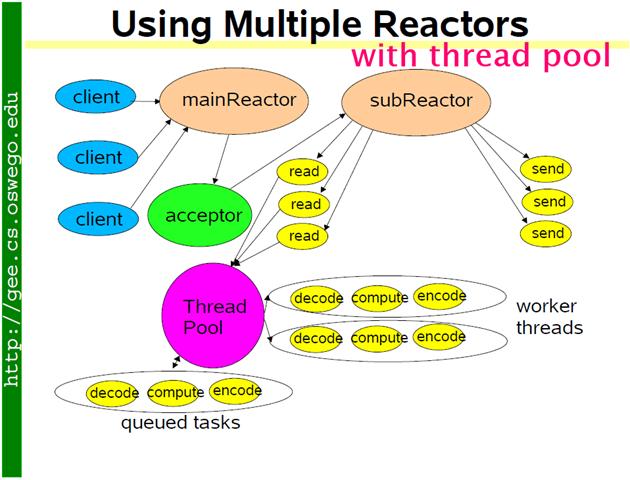
這種其實方案看起來復雜,其實寫起來很簡單,只要把方案 8 的代碼加一行 server_.setThreadNum(numThreads); 就行,這裡就不舉例了。
結語
我在《多線程服務 器的常用編程模型》一文中說
總結起來,我推薦的多線程服務端編程模式為:event loop per thread + thread pool。
event loop 用作 non-blocking IO 和定時器。
thread pool 用來做計算,具體可以是任務隊列或消費者-生產者隊列。
當時(2010年2月)我還說“以這種方式寫服務器程序,需要一個優質的基於 Reactor 模式的網絡 庫來支撐,我只用過in-house的產品,無從比較並推薦市面上常見的 C++ 網絡庫,抱歉。”
現 在有了 muduo 網絡庫,我終於能夠用具體的代碼示例把思想完整地表達出來。